在 Power Automate 中使用文本识别预生成模型
AI Builder 中的文本识别预置模型可从图像和文档中提取打印和手写文本。 通过使用 Power Automate此模型,您可以创建自动处理扫描文档、照片和 PDF 中的文本的工作流,从而实现高效的数据处理以及与其他应用程序的集成。
本文档提供了 Power Automate 中预置文本识别模型的使用指南。
初始化 Power Automate 流
初始化 Power Automate 流是设置自动化流程的第一步。 此步骤允许您定义流的触发器和初始输入参数。 初始化时,可以确保流正确启动,并具有高效处理文本识别任务所需的信息。
要初始化流,请按照以下步骤操作:
登录到 Power Automate。
在左侧导航菜单中选择我的流,然后选择新建流>即时云端流。
为流命名,在选择如何触发此流下选择手动触发流,然后选择创建。
展开手动触发流,然后选择 +添加输入>文件作为输入类型。
选择 +新建步骤>AI Builder,然后在操作列表中选择识别图像或 PDF 文档中的文本。
选择图像输入,然后从动态内容列表中选择文件内容:

若要处理结果,可以使用完整文档文本、页面文本或逐行文档文本。
获取完整的文档文本或整页文本
如果需要对整个文档文本或特定页面文本执行操作,此选项非常有用。 使用页面文本的一个示例是,当您想要搜索子字符串或将其传递给下游操作时。
您可以使用动态内容列表中的文档全文,在 Teams 频道中发布所有提取的文本。
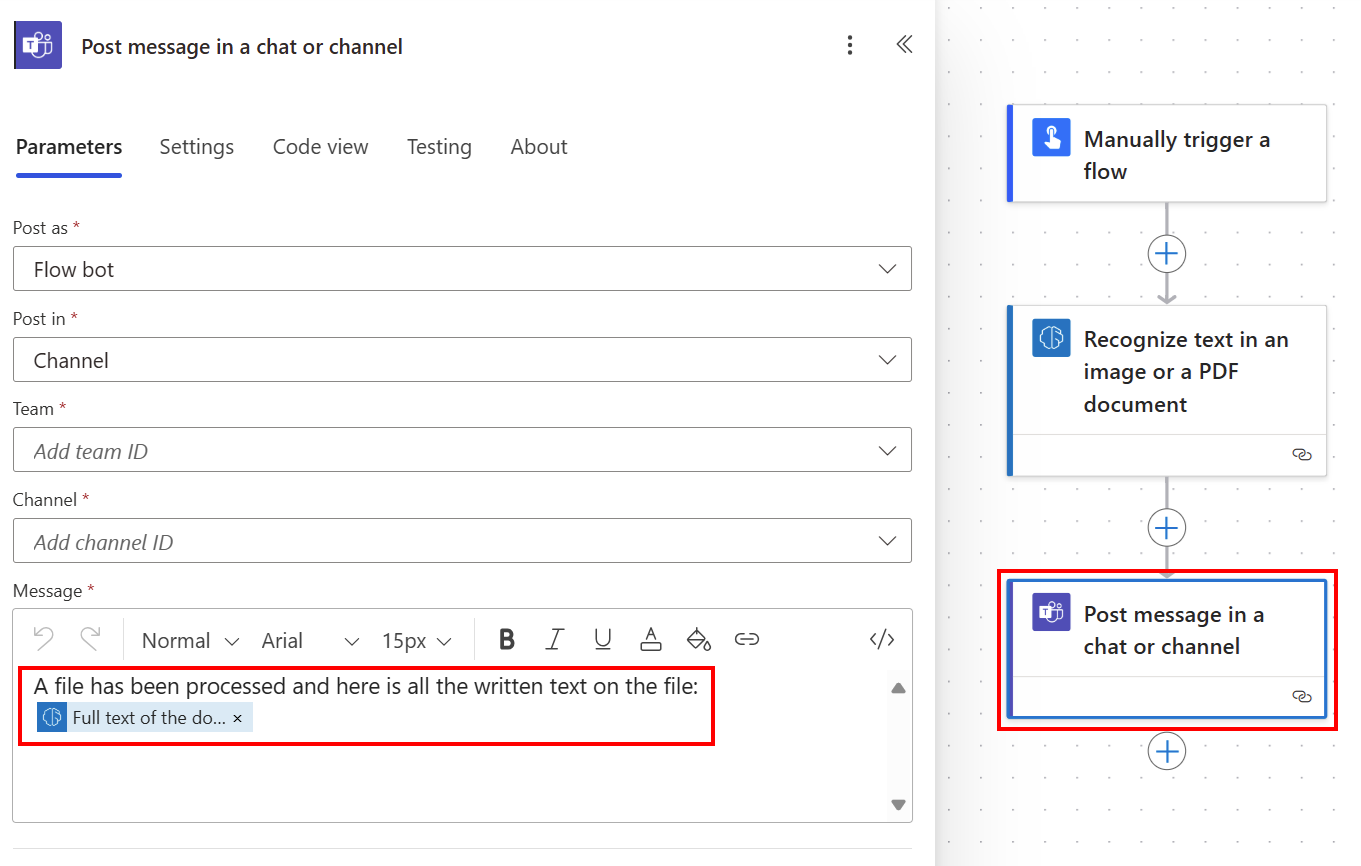
逐行获取文档文本
如果需要隔离特定文本行或在方便时重新格式化文本,则逐行获取文档文本会很有用。
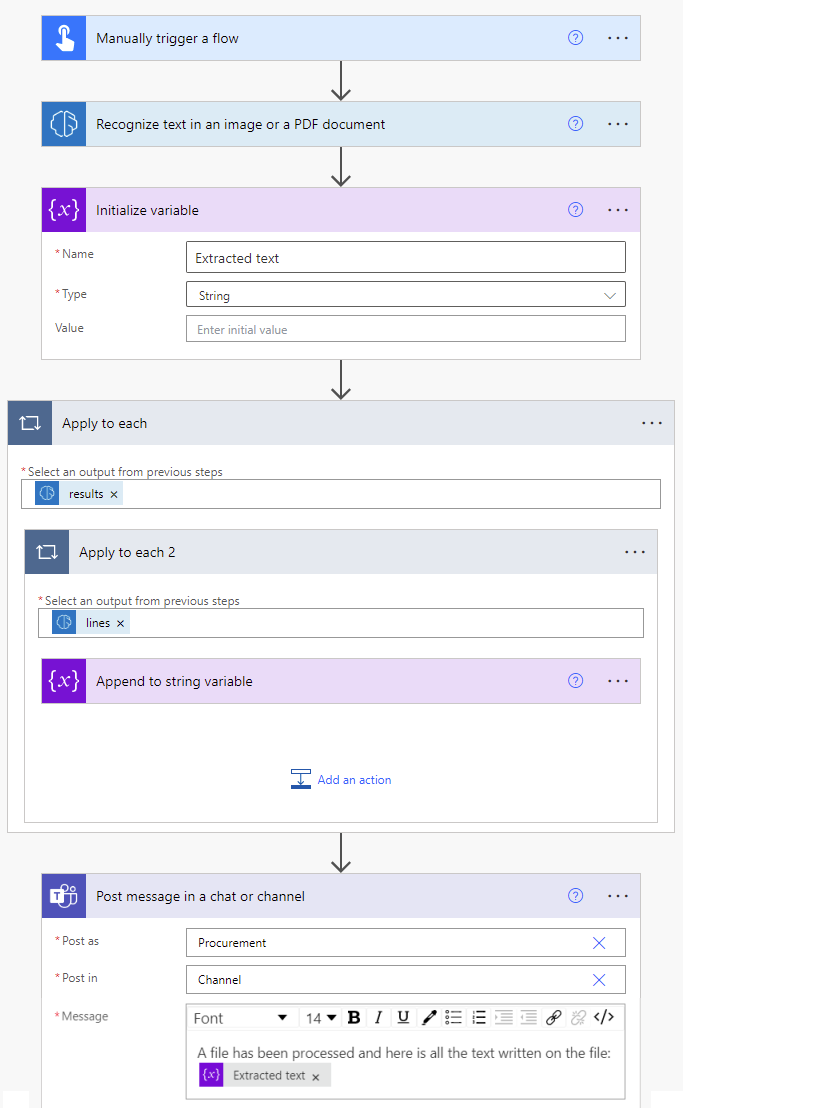
若要创建字符串变量,请选择+ 新建步骤>控件,然后选择初始化变量。
例如,将其命名为提取的文本。
选择+ 新建步骤>控件,然后选择追加到字符串变量。
在值字段中,从动态内容列表中选择文本。
当它读取页面列表中的行文本列表时,它会自动生成两个 应用于每个 操作。 然后,可以在 Teams 频道中发布所有提取的文本。
恭喜! 您创建了一个使用文本识别模型的流程。 可以继续生成此流直到它满足您的需求。 选择右上角的保存,然后选择测试以试用您的流。
参数设置
AI Builder 中的预建文本识别模型包含以下输入和输出参数。
输入
| 客户 | 必需 | 类型 | Description |
|---|---|---|---|
| 图像 | 可以 | 文件 | 要分析的图像 |
输出
检测到的文本将嵌入到结果列表的行子列表中。 您首先需要从应用到每一项操作中选择行列,来查看以下所有列。
| 客户 | Type | 描述 |
|---|---|---|
| 文本 | 字符串 | 包含检测到的文本行的字符串 |
| 页码 | string | 检测到的文本的页码 |
| 坐标 | float | 检测到的文本的坐标 |
| 文档全文 | string | 检测到全文 |
| 页面全文 | string | 检测到的整页文本 |