Connect to and manage Azure Databricks in Microsoft Purview
This article outlines how to register Azure Databricks, and how to authenticate and interact with Azure Databricks in Microsoft Purview. For more information about Microsoft Purview, read the introductory article.
Supported capabilities
| Metadata Extraction | Full Scan | Incremental Scan | Scoped Scan | Classification | Labeling | Access Policy | Lineage | Data Sharing | Live view |
|---|---|---|---|---|---|---|---|---|---|
| Yes | Yes | No | Yes | No | No | No | Yes | No | No |
Note
This connector brings metadata from Azure Databricks workspace-scoped Hive metastore. To scan metadata in Azure Databricks Unity Catalog, refer to Azure Databricks Unity Catalog connector.
When scanning Azure Databricks Hive metastore, Microsoft Purview supports:
Extracting technical metadata including:
- Azure Databricks workspace
- Hive server
- Databases
- Tables including the columns, foreign keys, unique constraints, and storage description
- Views including the columns and storage description
Fetching relationship between external tables and Azure Data Lake Storage Gen2/Azure Blob assets (external locations).
Fetching static lineage between tables and views based on the view definition.
When setting up scan, you can choose to scan the entire Hive metastore, or scope the scan to a subset of schemas.
Comparing to scan via generic Hive Metastore connector in case you use it to scan Azure Databricks earlier:
- You can directly set up scan for Azure Databricks workspaces without direct HMS access. It uses Databricks personal access token for authentication and connects to a cluster to perform scan.
- The Databricks workspace info is captured.
- The relationship between tables and storage assets is captured.
Known limitations
When object is deleted from the data source, currently the subsequent scan won't automatically remove the corresponding asset in Microsoft Purview.
Prerequisites
You must have an Azure account with an active subscription. Create an account for free.
You must have an active Microsoft Purview account.
You need an Azure Key Vault, and to grant Microsoft Purview permissions to access secrets.
You need Data Source Administrator and Data Reader permissions to register a source and manage it in the Microsoft Purview governance portal. For more information about permissions, see Access control in Microsoft Purview.
Set up the latest self-hosted integration runtime. For more information, see Create and configure a self-hosted integration runtime. The minimal supported self-hosted Integration Runtime version is 5.20.8227.2.
Ensure JDK 11 is installed on the machine where the self-hosted integration runtime is installed. Restart the machine after you newly install the JDK for it to take effect.
Ensure that Visual C++ Redistributable (version Visual Studio 2012 Update 4 or newer) is installed on the machine where the self-hosted integration runtime is running. If you don't have this update installed, download it now.
In your Azure Databricks workspace:
Generate a personal access token, and store it as a secret in Azure Key Vault.
Create a cluster. Note down the cluster ID - you can find it in Azure Databricks workspace -> Compute -> your cluster -> Tags -> Automatically added tags ->
ClusterId.Make sure the user has the following permissions so as to connect to the Azure Databricks cluster:
- Can Attach To permission to connect to the running cluster.
- Can Restart permission to automatically trigger the cluster to start if its state is terminated when connecting.
Register
This section describes how to register an Azure Databricks workspace in Microsoft Purview by using the Microsoft Purview governance portal.
Go to your Microsoft Purview account.
Select Data Map on the left pane.
Select Register.
In Register sources, select Azure Databricks > Continue.
On the Register sources (Azure Databricks) screen, do the following:
For Name, enter a name that Microsoft Purview will list as the data source.
For Azure subscription and Databricks workspace name, select the subscription and workspace that you want to scan from the dropdown. The Databricks workspace URL is automatically populated.
Select a collection from the list.
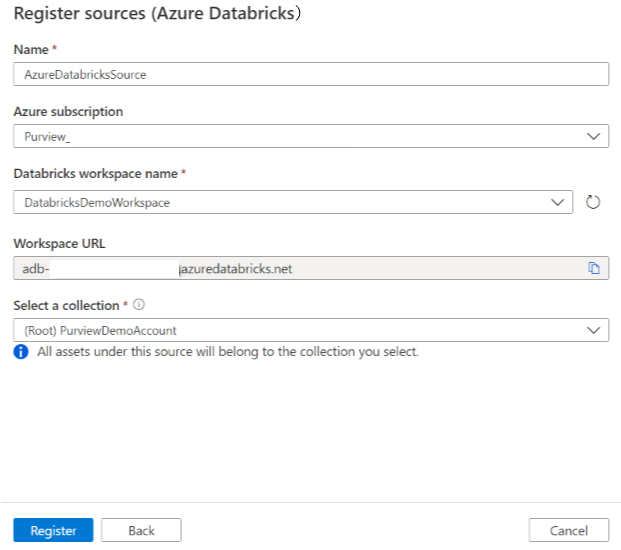
Select Finish.
Scan
Tip
To troubleshoot any issues with scanning:
- Confirm you have followed all prerequisites.
- Review our scan troubleshooting documentation.
Use the following steps to scan Azure Databricks to automatically identify assets. For more information about scanning in general, see Scans and ingestion in Microsoft Purview.
In the Management Center, select integration runtimes. Make sure that a self-hosted integration runtime is set up. If it isn't set up, use the steps in Create and manage a self-hosted integration runtime.
Go to Sources.
Select the registered Azure Databricks.
Select + New scan.
Provide the following details:
Name: Enter a name for the scan.
Extraction method: Indicate to extract metadata from Hive Metastore or Unity Catalog. Select Hive Metastore.
Connect via integration runtime: Select the configured self-hosted integration runtime.
Credential: Select the credential to connect to your data source. Make sure to:
- Select Access Token Authentication while creating a credential.
- Provide secret name of the personal access token that you created in Prerequisites in the appropriate box.
For more information, see Credentials for source authentication in Microsoft Purview.
Cluster ID: Specify the cluster ID that Microsoft Purview connects to and powers the scan. You can find it in Azure Databricks workspace -> Compute -> your cluster -> Tags -> Automatically added tags ->
ClusterId.Mount points: Provide the mount point and Azure Storage source location string when you have external storage manually mounted to Databricks. Use the format
/mnt/<path>=abfss://<container>@<adls_gen2_storage_account>.dfs.core.windows.net/;/mnt/<path>=wasbs://<container>@<blob_storage_account>.blob.core.windows.net. It's used to capture the relationship between tables and the corresponding storage assets in Microsoft Purview. This setting is optional, if it's not specified, such relationship isn't retrieved.You can get the list of mount points in your Databricks workspace by running the following Python command in a notebook:
dbutils.fs.mounts()It prints all the mount points like below:
[MountInfo(mountPoint='/databricks-datasets', source='databricks-datasets', encryptionType=''), MountInfo(mountPoint='/mnt/ADLS2', source='abfss://samplelocation1@azurestorage1.dfs.core.windows.net/', encryptionType=''), MountInfo(mountPoint='/databricks/mlflow-tracking', source='databricks/mlflow-tracking', encryptionType=''), MountInfo(mountPoint='/mnt/Blob', source='wasbs://samplelocation2@azurestorage2.blob.core.windows.net', encryptionType=''), MountInfo(mountPoint='/databricks-results', source='databricks-results', encryptionType=''), MountInfo(mountPoint='/databricks/mlflow-registry', source='databricks/mlflow-registry', encryptionType=''), MountInfo(mountPoint='/', source='DatabricksRoot', encryptionType='')]In this example, specify the following as mount points:
/mnt/ADLS2=abfss://samplelocation1@azurestorage1.dfs.core.windows.net/;/mnt/Blob=wasbs://samplelocation2@azurestorage2.blob.core.windows.netSchema: The subset of schemas to import expressed as a semicolon separated list of schemas. For example,
schema1;schema2. All user schemas are imported if that list is empty. All system schemas and objects are ignored by default.Acceptable schema name patterns can be static names or contain wildcard %. For example:
A%;%B;%C%;D- Start with A or
- End with B or
- Contain C or
- Equal D
Usage of NOT and special characters aren't acceptable.
Note
This schema filter is supported on Self-hosted Integration Runtime version 5.32.8597.1 and above.
Maximum memory available: Maximum memory (in gigabytes) available on the customer's machine for the scanning processes to use. This value is dependent on the size of Azure Databricks to be scanned.
Note
As a thumb rule, please provide 1GB memory for every 1000 tables.
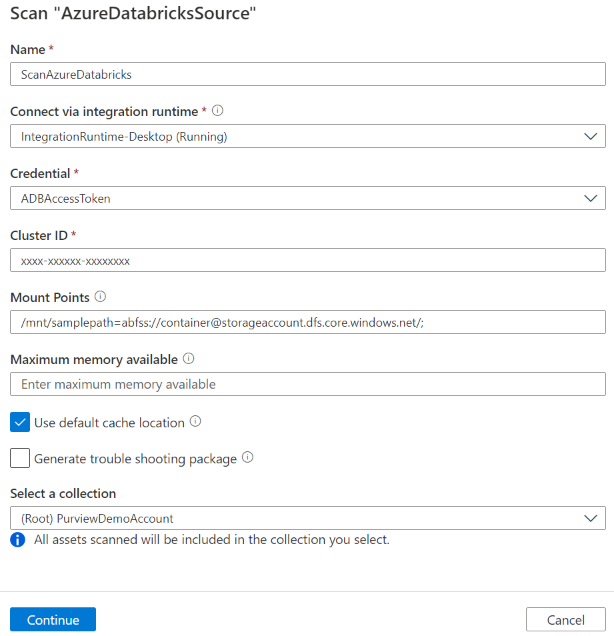
Select Continue.
For Scan trigger, choose whether to set up a schedule or run the scan once.
Review your scan and select Save and Run.
Once the scan successfully completes, see how to browse and search Azure Databricks assets.
View your scans and scan runs
To view existing scans:
- Go to the Microsoft Purview portal. On the left pane, select Data map.
- Select the data source. You can view a list of existing scans on that data source under Recent scans, or you can view all scans on the Scans tab.
- Select the scan that has results you want to view. The pane shows you all the previous scan runs, along with the status and metrics for each scan run.
- Select the run ID to check the scan run details.
Manage your scans
To edit, cancel, or delete a scan:
Go to the Microsoft Purview portal. On the left pane, select Data Map.
Select the data source. You can view a list of existing scans on that data source under Recent scans, or you can view all scans on the Scans tab.
Select the scan that you want to manage. You can then:
- Edit the scan by selecting Edit scan.
- Cancel an in-progress scan by selecting Cancel scan run.
- Delete your scan by selecting Delete scan.
Note
- Deleting your scan does not delete catalog assets created from previous scans.
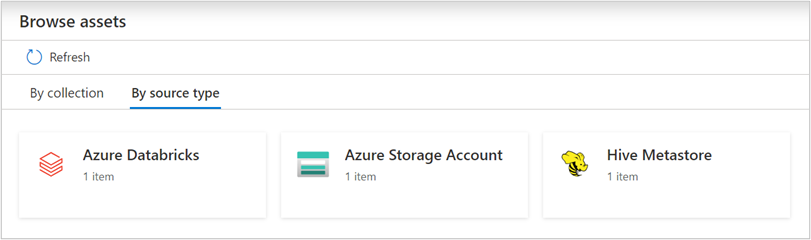
Browse and search assets
After scanning your Azure Databricks, you can browse Unified Catalog or search Unified Catalog to view the asset details.
From the Databricks workspace asset, you can find the associated Hive Metastore and the tables/views, reversed applies too.
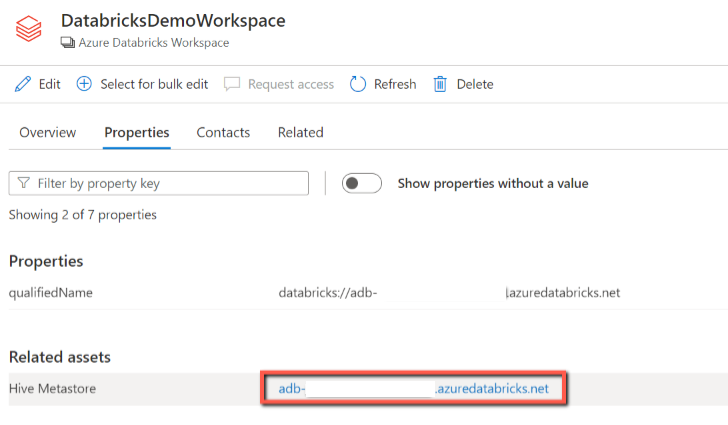
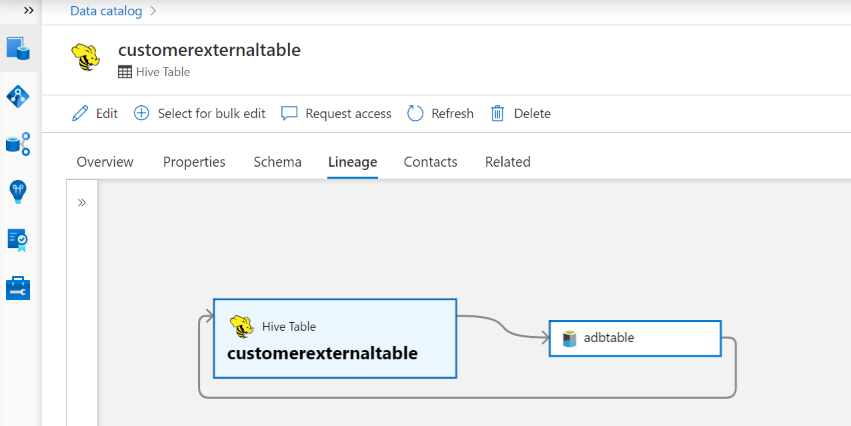
Lineage
Refer to the supported capabilities section on the supported Azure Databricks scenarios. For more information about lineage in general, see data lineage and lineage user guide.
Go to the Hive table/view asset -> lineage tab, you can see the asset relationship when applicable. For relationship between table and external storage assets, you see Hive table asset and the storage asset are directly connected bi-directionally, as they mutually impact each other. If you use mount point in create table statement, you need to provide the mount point information in scan settings to extract such relationship.
Next steps
Now that you've registered your source, use the following guides to learn more about Microsoft Purview and your data: