ดำเนินการ OCR ในเอกสารหลายภาษา
การรู้จำอักขระด้วยแสง (OCR) ช่วยให้คุณค้นหาและดึงข้อความจากรูปภาพหรือหน้าจอ
แม้ว่าสถานการณ์ส่วนใหญ่ต้องการให้คุณจัดการข้อความในภาษาใดภาษาหนึ่ง แต่ก็มีบางกรณีที่แหล่งข้อมูลมีหลายภาษา
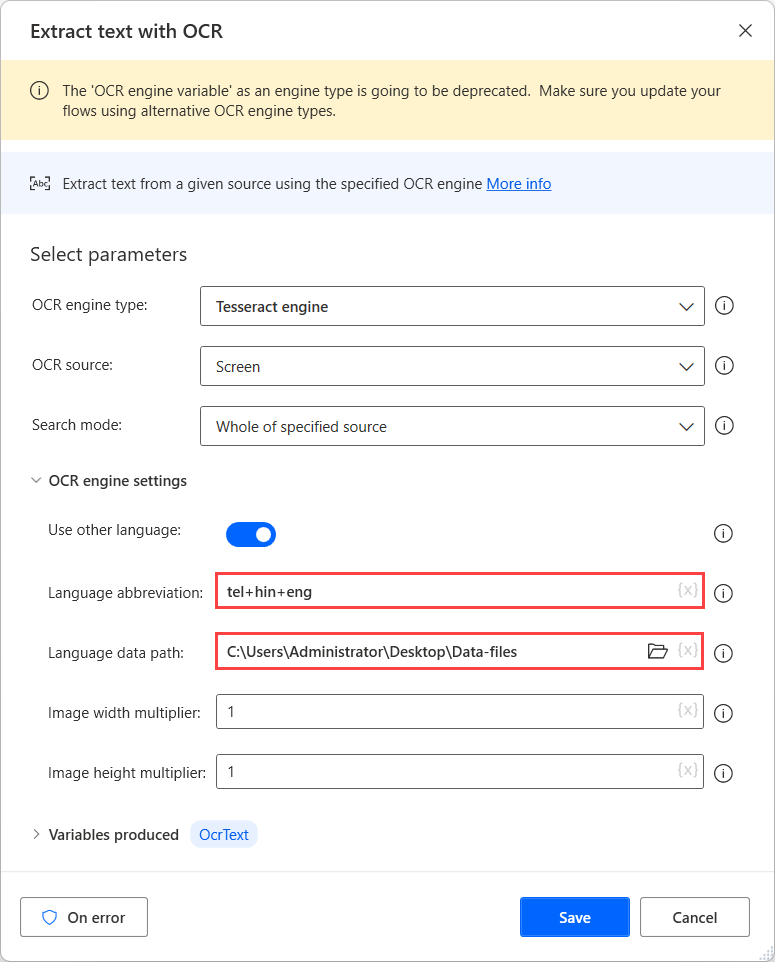
ในการดำเนินการ OCR บนแหล่งที่มาเหล่านี้ ให้ใช้โปรแกรม Tesseract ในการดำเนินการ OCR ที่เกี่ยวข้องและเปิดใช้งานตัวเลือก ใช้ภาษาอื่น ในการตั้งค่าโปรแกรม
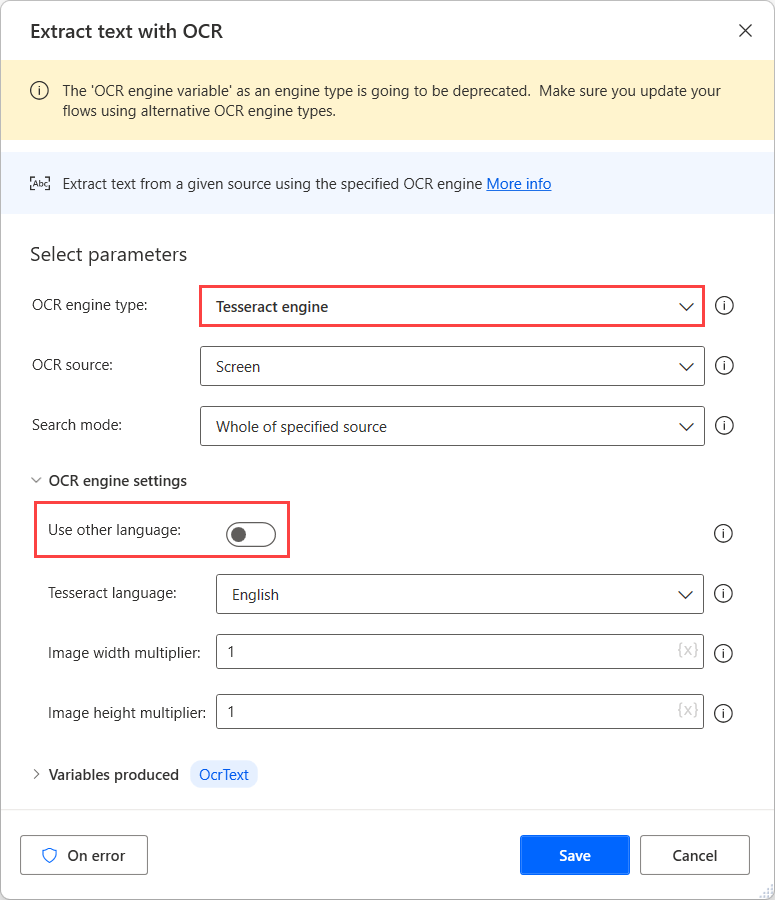
เมื่อเปิดใช้งานตัวเลือก ใช้ภาษาอื่น การดำเนินการจะแสดงการตั้งค่าเพิ่มเติมสองรายการ: ฟิลด์ ตัวย่อภาษา และ พาธข้อมูลภาษา
ฟิลด์ ตัวย่อภาษา ระบุกับโปรแกรมว่าต้องค้นหาภาษาใดระหว่าง OCR ฟิลด์ พาธข้อมูลภาษา มีไฟล์ข้อมูลภาษา (.traineddata) ที่ใช้ในการฝึกอบรมโปรแกรม OCR
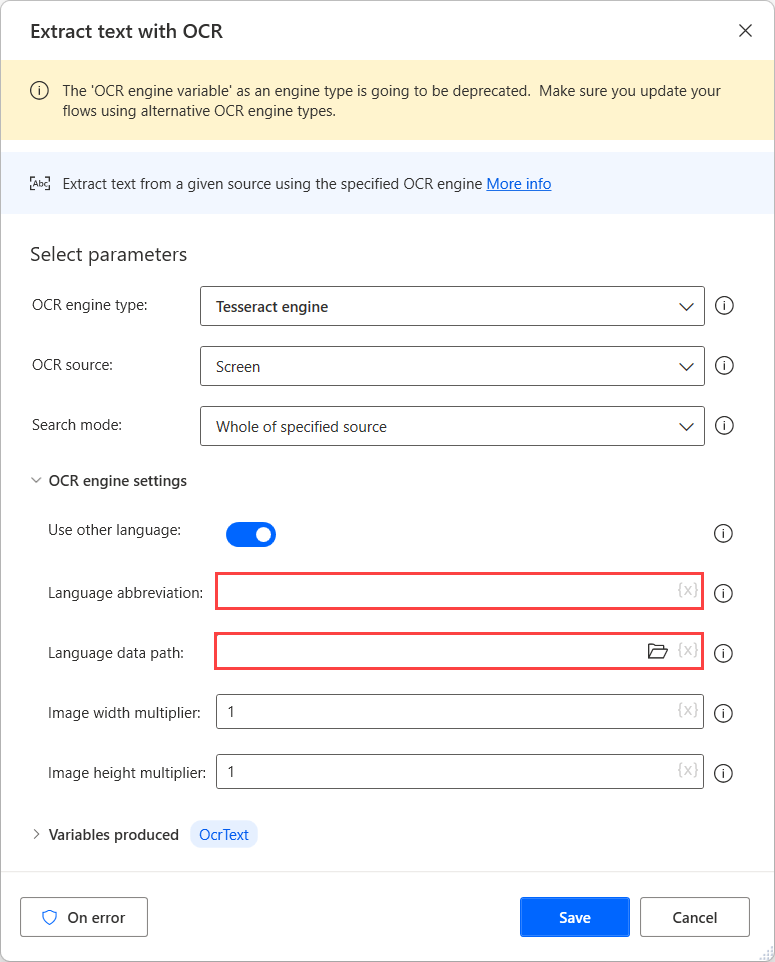
หลังจากดาวน์โหลดไฟล์ข้อมูลสำหรับภาษาที่ต้องการแล้ว ให้ย้ายไปยังโฟลเดอร์ทั่วไปเพื่อให้ใช้งานได้ภายใต้พาธเดียวกัน
จากนั้นเลือกโฟลเดอร์ที่สร้างขึ้นในฟิลด์ พาธข้อมูลภาษา และใส่รหัสภาษาที่เกี่ยวข้องในฟิลด์ ตัวย่อภาษา หากต้องการแยกรหัสภาษา ให้ใช้อักขระบวก (+)
หมายเหตุ
คุณสามารถค้นหารหัสภาษาที่มีอยู่ทั้งหมดได้ในแหล่งที่มาของไฟล์ข้อมูลภาษา ในตัวอย่างต่อไปนี้ รหัสที่ใช้แสดงถึงภาษาเตลูกู ฮินดี และอังกฤษ