การตรวจหาความผิดปกติแบบหลากหลายรูปแบบ
สําหรับข้อมูลทั่วไปเกี่ยวกับการตรวจหาสิ่งผิดปกติที่หลากหลายในตัวแสดงเวลาจริง โปรดดู ภาพรวมการตรวจหาสิ่งผิดปกติที่หลากหลายใน Microsoft Fabric ในบทช่วยสอนนี้ คุณจะใช้ข้อมูลตัวอย่างเพื่อฝึกแบบจําลองการตรวจหาสิ่งผิดปกติที่หลากหลายโดยใช้กลไก Spark ใน Python notebook จากนั้นคุณทํานายความผิดปกติโดยใช้แบบจําลองที่ได้รับการฝึกกับข้อมูลใหม่โดยใช้กลไก Eventhouse สองสามขั้นตอนแรกจะตั้งค่าสภาพแวดล้อมของคุณ และขั้นตอนต่อไปนี้จะฝึกแบบจําลองและทํานายความผิดปกติ
ข้อกำหนดเบื้องต้น
- พื้นที่ทํางานที่มีความจุที่เปิดใช้งาน Microsoft Fabric
- บทบาทของผู้ดูแลระบบ ผู้สนับสนุน หรือสมาชิกในพื้นที่ทํางาน ระดับสิทธิ์นี้จําเป็นในการสร้างรายการ เช่น สภาพแวดล้อม
- คลังเหตุการณ์ในพื้นที่ทํางานของคุณที่มีฐานข้อมูล
- ดาวน์โหลดข้อมูลตัวอย่างจากที่เก็บ GitHub
- ดาวน์โหลดสมุดบันทึกจาก GitHub repo
ส่วนที่ 1- เปิดใช้งานความพร้อมใช้งานของ OneLake
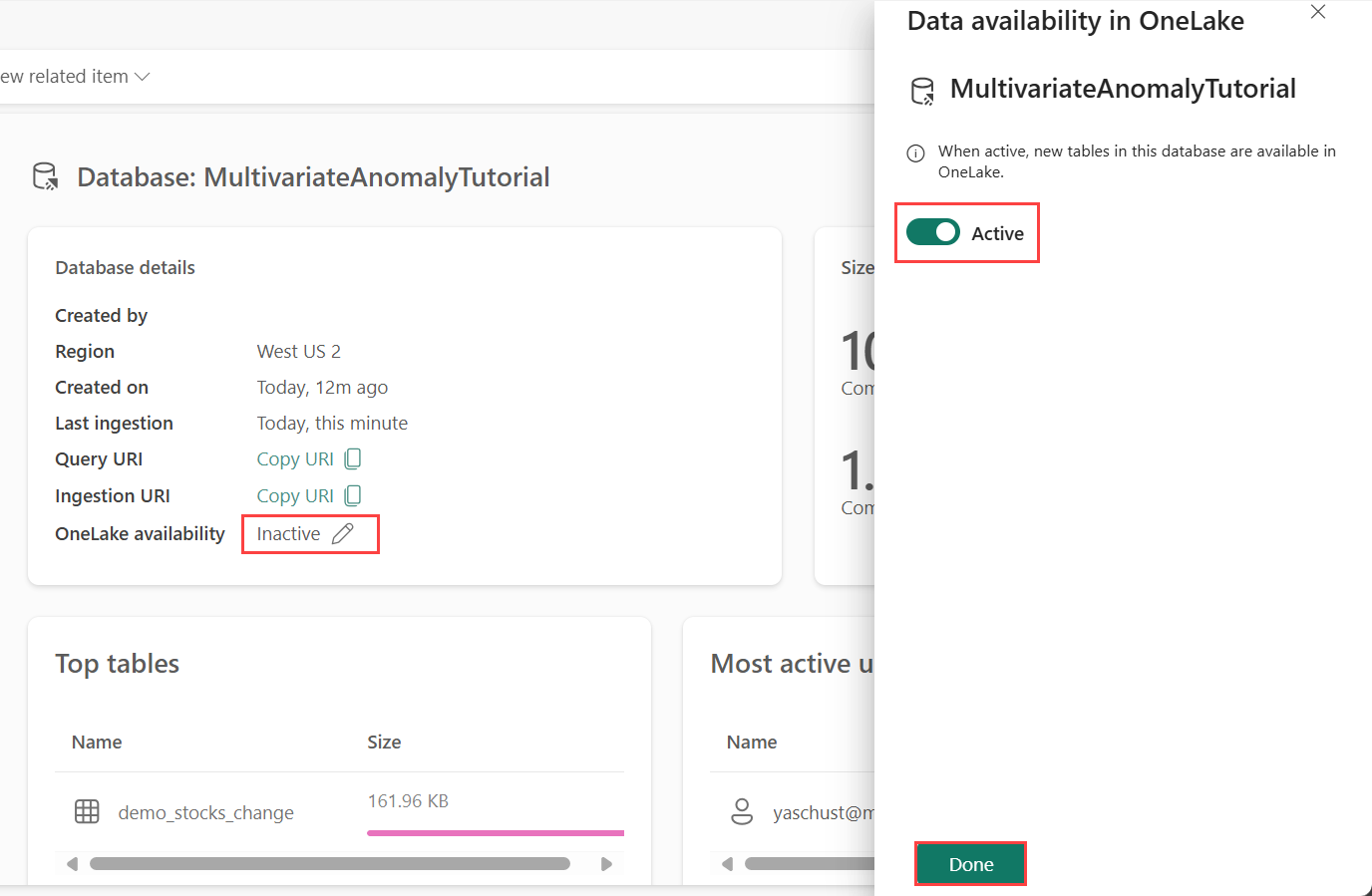
ต้อง เปิดใช้งาน ความพร้อมใช้งาน OneLake ก่อนที่คุณจะได้รับข้อมูลใน Eventhouse ขั้นตอนนี้มีความสําคัญ เนื่องจากเป็นการเปิดใช้งานข้อมูลที่คุณนําเข้าเพื่อให้พร้อมใช้งานใน OneLake ในขั้นตอนถัดไป คุณเข้าถึงข้อมูลเดียวกันนี้จาก Spark Notebook ของคุณเพื่อฝึกแบบจําลอง
จากพื้นที่ทํางานของคุณ เลือกอีเวนต์เฮ้าส์ที่คุณสร้างขึ้นในข้อกําหนดเบื้องต้น เลือกฐานข้อมูลที่คุณต้องการจัดเก็บข้อมูลของคุณ
ในบานหน้าต่าง รายละเอียดฐานข้อมูล ให้สลับปุ่ม ความพร้อมใช้งาน OneLake เพื่อ
ส่วนที่ 2- เปิดใช้งานปลั๊กอิน KQL Python
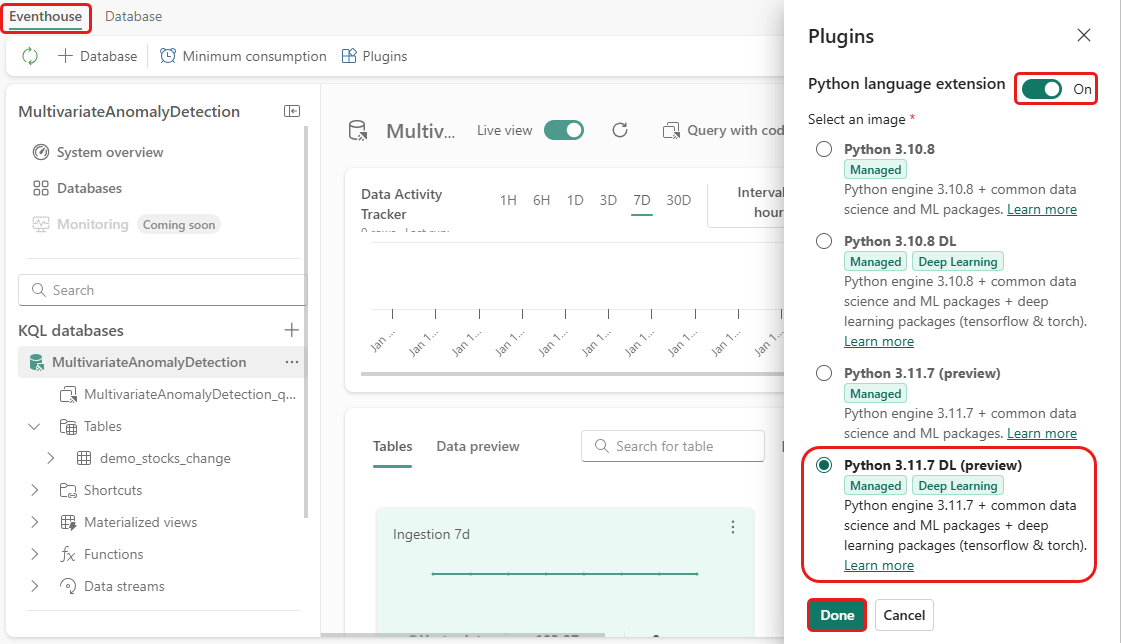
ในขั้นตอนนี้ คุณเปิดใช้งานปลั๊กอิน python ใน Eventhouse ของคุณ ขั้นตอนนี้จําเป็นสําหรับการ เรียกใช้รหัส Python ทํานายความผิดปกติ ในชุดคิวรี KQL สิ่งสําคัญคือการเลือกรูปภาพที่ถูกต้องที่มีแพคเกจ time-series-anomaly-detector
ในหน้าจออีเวนต์เฮ้าส์ เลือก Eventhouse>ปลั๊กอิน จากริบบิ้น
ในบานหน้าต่าง ปลั๊กอิน ให้สลับส่วนขยายภาษา Python เป็นเปิด
เลือก Python 3.11.7 DL (ตัวอย่าง)
เลือก เสร็จสิ้น

ส่วนที่ 3- สร้างสภาพแวดล้อม Spark
ในขั้นตอนนี้ คุณสร้างสภาพแวดล้อม Spark เพื่อเรียกใช้ Python notebook ที่ฝึกแบบจําลองการตรวจหาสิ่งผิดปกติที่หลากหลายโดยใช้กลไก Spark สําหรับข้อมูลเพิ่มเติมเกี่ยวกับการสร้างสภาพแวดล้อม ดูสร้างและจัดการสภาพแวดล้อม
จากพื้นที่ทํางานของคุณ ให้เลือก
+ รายการใหม่ จากนั้นสภาพแวดล้อม 
ใส่ชื่อ MVAD_ENV สําหรับสภาพแวดล้อม จากนั้นเลือก สร้าง
จากแท็บ Home ของสภาพแวดล้อม ให้เลือก รันไทม์>1.2 (Spark 3.4, Delta 2.4)
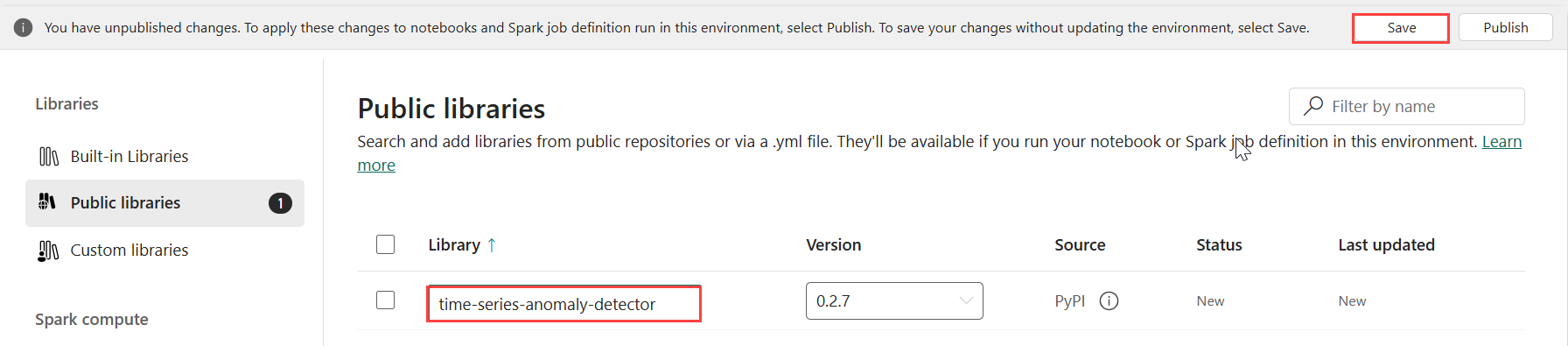
ภายใต้ ไลบรารี เลือก ไลบรารีสาธารณะ
เลือกเพิ่มจาก PyPI
ในกล่องค้นหา ให้ป้อน time-series-anomaly-detector เวอร์ชันจะเติมด้วยเวอร์ชันล่าสุดโดยอัตโนมัติ บทช่วยสอนนี้ถูกสร้างขึ้นโดยใช้เวอร์ชัน 0.3.2
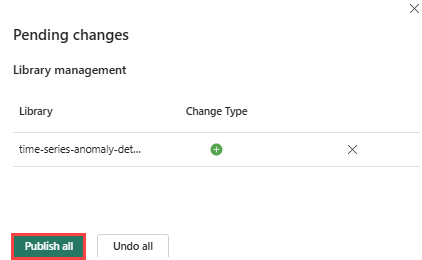
เลือก บันทึก
เลือก แท็บ หน้าแรก ในสภาพแวดล้อม
เลือก ไอคอน เผยแพร่ จากริบบอน

เลือก เผยแพร่ทั้งหมด ขั้นตอนนี้อาจใช้เวลาหลายนาทีในการดําเนินการให้เสร็จสมบูรณ์


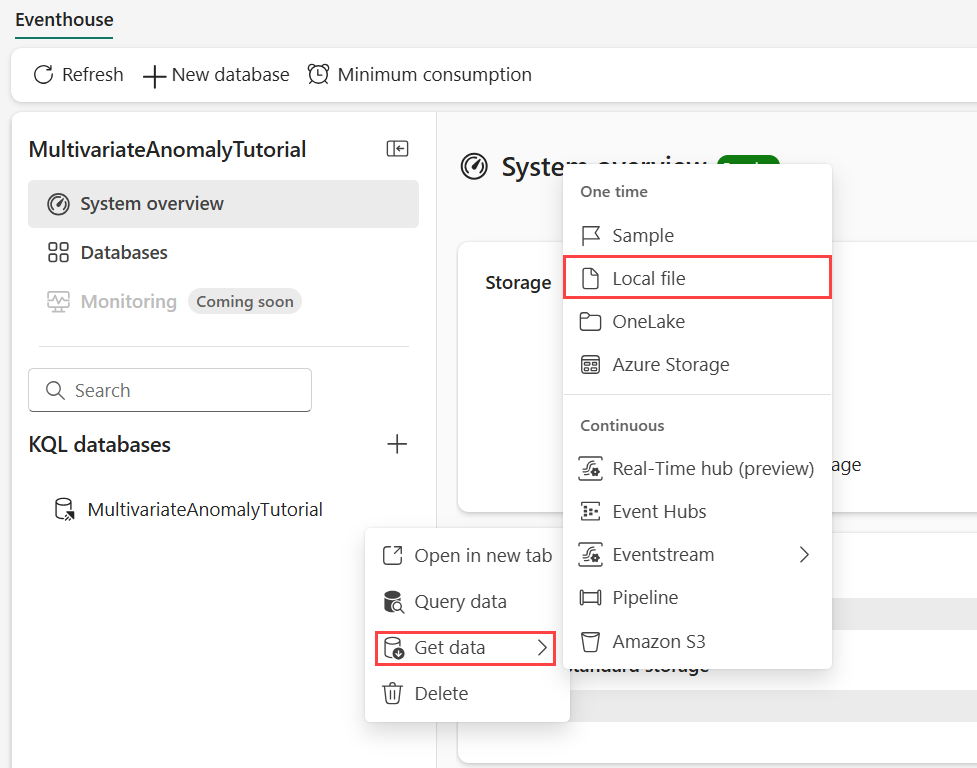
ส่วนที่ 4- รับข้อมูลลงในอีเวนต์เฮ้าส์
วางเมาส์เหนือฐานข้อมูล KQL ที่คุณต้องการจัดเก็บข้อมูลของคุณ เลือก เมนูเพิ่มเติม [...]>รับข้อมูล>ไฟล์ภายในเครื่อง
เลือก + ตาราง ใหม่ และใส่ demo_stocks_change เป็นชื่อตาราง
ในกล่องโต้ตอบการอัปโหลดข้อมูล เลือก เรียกดูไฟล์ และอัปโหลดไฟล์ข้อมูลตัวอย่างที่ดาวน์โหลดใน ข้อกําหนดเบื้องต้น
เลือก ถัดไป
ในส่วน ตรวจสอบข้อมูล ให้สลับ แถวแรก เป็นส่วนหัวของคอลัมน์เป็น เปิด
เลือก เสร็จสิ้น
เมื่อข้อมูลถูกอัปโหลด เลือกปิด
ส่วนที่ 5- คัดลอกเส้นทาง OneLake ไปยังตาราง
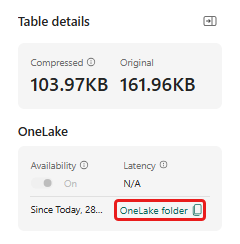
ตรวจสอบให้แน่ใจว่าคุณเลือกตาราง demo_stocks_change ในบานหน้าต่างรายละเอียดตาราง ให้เลือกโฟลเดอร์ OneLake เพื่อคัดลอกเส้นทาง OneLake ไปยังคลิปบอร์ดของคุณ บันทึกข้อความที่คัดลอกนี้ในตัวแก้ไขข้อความเพื่อใช้ในขั้นตอนถัดไป
ส่วนที่ 6- เตรียมสมุดบันทึก
เลือกพื้นที่ทํางานของคุณ
เลือก นําเข้า, สมุดบันทึก แล้วเลือก จากคอมพิวเตอร์เครื่องนี้
เลือก อัปโหลด และเลือกสมุดบันทึกที่คุณดาวน์โหลดใน ข้อกําหนดเบื้องต้น
หลังจากอัปโหลดสมุดบันทึกแล้ว คุณสามารถค้นหาและเปิดสมุดบันทึกของคุณได้จากพื้นที่ทํางานของคุณ
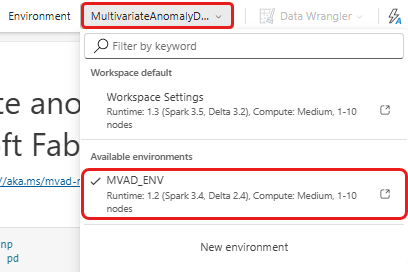
จากริบบอนด้านบนสุด เลือกรายการดรอปดาวน์ค่าเริ่มต้นของพื้นที่ทํางาน และเลือกสภาพแวดล้อมที่คุณสร้างในขั้นตอนก่อนหน้า
ส่วนที่ 7- เรียกใช้สมุดบันทึก
นําเข้าแพคเกจมาตรฐาน
import numpy as np import pandas as pdSpark ต้องมี ABFSS URI เพื่อเชื่อมต่อกับที่เก็บข้อมูล OneLake อย่างปลอดภัย ดังนั้นขั้นตอนถัดไปจะกําหนดฟังก์ชันนี้เพื่อแปลง OneLake URI เป็น ABFSS URI
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uriแทนที่ตัวแทน OneLakeTableURI ของคุณด้วย OneLake URI ของคุณที่คัดลอกจาก Part 5- คัดลอกเส้นทาง OneLake ไปยังตาราง เพื่อโหลดตาราง demo_stocks_change ลงในดาต้าเฟรมของ pandas
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]เรียกใช้เซลล์ต่อไปนี้เพื่อเตรียมกรอบข้อมูลการฝึกและการคาดเดา
หมายเหตุ
การคาดการณ์จริงจะเรียกใช้ข้อมูลโดย Eventhouse ในส่วน ที่ 9- ทํานายความผิดปกติในชุดคิวรี kql ในสถานการณ์การผลิต ถ้าคุณกําลังสตรีมข้อมูลไปยัง eventhouse การคาดการณ์จะทําบนข้อมูลการสตรีมใหม่ สําหรับวัตถุประสงค์ของบทช่วยสอน ชุดข้อมูลถูกแยกตามวันที่เป็นสองส่วนสําหรับการฝึกอบรมและการคาดการณ์ นี่คือการจําลองข้อมูลในอดีตและข้อมูลการสตรีมใหม่
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')เรียกใช้เซลล์เพื่อฝึกแบบจําลองและบันทึกในรีจิสทรีแบบจําลอง Fabric MLflow
import mlflow from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name="mvad_5_stocks_model", )เรียกใช้เซลล์ต่อไปนี้เพื่อแยกเส้นทางแบบจําลองที่ลงทะเบียนเพื่อใช้สําหรับการคาดการณ์โดยใช้ Sandbox ของ Kusto Python
mi = mlflow.search_registered_models(filter_string="name='mvad_5_stocks_model'")[0] model_abfss = mi.latest_versions[0].source print(model_abfss)คัดลอก URI ของแบบจําลองจากผลลัพธ์เซลล์สุดท้ายสําหรับการใช้งานในขั้นตอนถัดไป
ส่วนที่ 8- ตั้งค่าคิวรี KQL ของคุณ
สําหรับข้อมูลทั่วไป ดู สร้างคิวรี KQL
- จากพื้นที่ทํางานของคุณ เลือก +รายการใหม่>ชุดคิวรี KQL
- ป้อนชื่อ MultivariateAnomalyDetectionTutorialจากนั้นเลือก สร้าง
- ในหน้าต่างฮับข้อมูล OneLake ให้เลือกฐานข้อมูล KQL ที่คุณจัดเก็บข้อมูล
- เลือก เชื่อมต่อ
ส่วนที่ 9- คาดการณ์ความผิดปกติในชุดคิวรี KQL
เรียกใช้คิวรี '.create-or-alter' ต่อไปนี้เพื่อกําหนดฟังก์ชัน
predict_fabric_mvad_fl()จัดเก็บไว้:.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }เรียกใช้คิวรีการคาดการณ์ต่อไปนี้ แทน URI แบบจําลองผลลัพธ์ด้วย URI ที่คัดลอกในตอนท้ายของ ขั้นตอนที่ 7
คิวรีตรวจพบความผิดปกติที่หลากหลายในหุ้นห้ารายการ ตามแบบจําลองที่ได้รับการฝึกและแสดงผลลัพธ์เป็น
anomalychartจุดที่ผิดปกติจะแสดงบนหุ้นตัวแรก (AAPL) แม้ว่าจะแสดงถึงความผิดปกติที่หลากหลาย (กล่าวคือ ความผิดปกติของการเปลี่ยนแปลงร่วมกันของหุ้นห้าตัวในวันที่ระบุ)let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
แผนภูมิที่เกิดความผิดปกติควรมีลักษณะเหมือนกับรูปภาพต่อไปนี้:

ล้างแหล่งข้อมูล
เมื่อคุณเสร็จสิ้นบทช่วยสอน คุณสามารถลบทรัพยากรที่คุณสร้างขึ้นเพื่อหลีกเลี่ยงค่าใช้จ่ายอื่น ๆ เกิดขึ้น เมื่อต้องการลบทรัพยากร ให้ทําตามขั้นตอนเหล่านี้:
- เรียกดูโฮมเพจพื้นที่ทํางานของคุณ
- ลบสภาพแวดล้อมที่สร้างขึ้นในบทช่วยสอนนี้
- ลบสมุดบันทึกที่สร้างขึ้นในบทช่วยสอนนี้
- ลบ Eventhouse หรือ ฐานข้อมูล ที่ใช้ในบทช่วยสอนนี้
- ลบคิวรี KQL ที่สร้างขึ้นในบทช่วยสอนนี้