บทช่วยสอนส่วนที่ 3: ฝึกและลงทะเบียนแบบจําลองการเรียนรู้ของเครื่อง
ในบทช่วยสอนนี้ คุณจะได้เรียนรู้วิธีการฝึกแบบจําลองการเรียนรู้ของเครื่องหลายแบบเพื่อเลือกแบบจําลองที่ดีที่สุดเพื่อคาดการณ์ว่าลูกค้าธนาคารรายใดมีแนวโน้มที่จะลาออก
ในบทช่วยสอนนี้ คุณจะ:
- ฝึกแบบจําลองฟอเรสต์แบบสุ่มและ LightGBM
- ใช้การรวมแบบเนทีฟของ Microsoft Fabric กับเฟรมเวิร์ก MLflow เพื่อบันทึกแบบจําลองการเรียนรู้ของเครื่องที่ได้รับการฝึกแล้ว เมตริกที่ใช้ hyperaparameters และเมตริกการประเมินผล
- ลงทะเบียนแบบจําลองการเรียนรู้ของเครื่องที่ได้รับการฝึกแล้ว
- ประเมินประสิทธิภาพของแบบจําลองการเรียนรู้ของเครื่องที่ได้รับการฝึกบนชุดข้อมูลการตรวจสอบความถูกต้อง
MLflow เป็นแพลตฟอร์มโอเพนซอร์ส (Open Source)สําหรับการจัดการวงจรชีวิตการเรียนรู้ของเครื่องด้วยคุณลักษณะต่าง ๆ เช่น การติดตาม แบบจําลอง และรีจิสทรีแบบจําลอง MLflow ได้รวมเข้ากับประสบการณ์ Fabric Data Science ในแบบดั้งเดิม
ข้อกำหนดเบื้องต้น
รับการสมัครใช้งาน Microsoft Fabric หรือลงทะเบียนเพื่อทดลองใช้งาน Microsoft Fabric ฟรี
ลงชื่อเข้าใช้ Microsoft Fabric
ใช้ตัวสลับประสบการณ์การใช้งานที่ด้านล่างซ้ายของหน้าหลักของคุณเพื่อเปลี่ยนเป็น Fabric

นี่คือส่วนที่ 3 จาก 5 ในชุดบทช่วยสอน เมื่อต้องการทําบทช่วยสอนนี้ให้เสร็จสมบูรณ์ ก่อนอื่นให้ทําให้เสร็จสมบูรณ์:
- ส่วนที่ 1: นําเข้าข้อมูลลงใน Microsoft Fabric lakehouse โดยใช้ Apache Spark
- ส่วนที่ 2: สํารวจและแสดงข้อมูลด้วยภาพโดยใช้สมุดบันทึก Microsoft Fabric เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับข้อมูล
ติดตามพร้อมกับในสมุดบันทึก
3-train-evaluate.ipynb คือสมุดบันทึกที่มาพร้อมกับบทช่วยสอนนี้
เมื่อต้องการเปิดสมุดบันทึกที่มาพร้อมกับบทช่วยสอนนี้ ให้ทําตามคําแนะนําใน เตรียมระบบของคุณสําหรับบทช่วยสอนวิทยาศาสตร์ข้อมูล การนําเข้าสมุดบันทึกไปยังพื้นที่ทํางานของคุณ
ถ้าคุณต้องการคัดลอกและวางรหัสจากหน้านี้แทน คุณสามารถสร้าง สมุดบันทึกใหม่ได้
ตรวจสอบให้แน่ใจว่าแนบ lakehouse เข้ากับสมุดบันทึก ก่อนที่คุณจะเริ่มเรียกใช้รหัส
สำคัญ
แนบเลคเฮ้าส์เดียวกับที่คุณใช้ในส่วนที่ 1 และตอนที่ 2
ติดตั้งไลบรารีแบบกําหนดเอง
สําหรับสมุดบันทึกนี้ คุณจะติดตั้ง การเรียนรู้ที่ไม่สมดุล (นําเข้าเป็น imblearn) โดยใช้%pip install Imbalanced-learn เป็นไลบรารีสําหรับเทคนิคการสุ่มตัวอย่างมากเกินไปสังเคราะห์ (SMOTE) ซึ่งจะใช้เมื่อจัดการกับชุดข้อมูลที่ไม่สมดุล เคอร์เนล PySpark จะเริ่มต้นใหม่หลังจาก %pip installดังนั้นคุณจะต้องติดตั้งไลบรารีก่อนที่คุณจะเรียกใช้เซลล์อื่นๆ
คุณจะเข้าถึง SMOTE โดยใช้ imblearn ไลบรารี ติดตั้งเดี๋ยวนี้โดยใช้ความสามารถในการติดตั้งในบรรทัด (เช่น %pip, ) %conda
# Install imblearn for SMOTE using pip
%pip install imblearn
สำคัญ
เรียกใช้การติดตั้งนี้ในแต่ละครั้งที่คุณเริ่มสมุดบันทึกใหม่
เมื่อคุณติดตั้งไลบรารีในสมุดบันทึก จะพร้อมใช้งานเฉพาะในช่วงระยะเวลาของเซสชันสมุดบันทึกเท่านั้น และจะไม่อยู่ในพื้นที่ทํางาน ถ้าคุณเริ่มสมุดบันทึกใหม่ คุณจะต้องติดตั้งไลบรารีอีกครั้ง
ถ้าคุณมีไลบรารีที่คุณใช้บ่อย และคุณต้องการทําให้ไลบรารีพร้อมใช้งานสําหรับสมุดบันทึกทั้งหมดในพื้นที่ทํางานของคุณ คุณสามารถใช้ สภาพแวดล้อม Fabric สําหรับวัตถุประสงค์นั้นได้ คุณสามารถสร้างสภาพแวดล้อม ติดตั้งไลบรารีในนั้น จากนั้น ผู้ดูแลระบบ พื้นที่ทํางานของคุณสามารถแนบสภาพแวดล้อมเข้ากับพื้นที่ทํางานเป็นสภาพแวดล้อมเริ่มต้น สําหรับข้อมูลเพิ่มเติมเกี่ยวกับการตั้งค่าสภาพแวดล้อมเป็นค่าเริ่มต้นของพื้นที่ทํางาน ดูที่ผู้ดูแลระบบตั้งค่าไลบรารีเริ่มต้นสําหรับพื้นที่ทํางาน
สําหรับข้อมูลเกี่ยวกับการโยกย้ายไลบรารีพื้นที่ทํางานที่มีอยู่และคุณสมบัติ Spark ไปยังสภาพแวดล้อม ให้ดู โยกย้ายไลบรารีพื้นที่ทํางานและคุณสมบัติ Spark ไปยังสภาพแวดล้อมเริ่มต้น
โหลดข้อมูล
ก่อนที่จะฝึกแบบจําลองการเรียนรู้ของเครื่องใดๆ คุณต้องโหลดตาราง delta จากเลคเฮ้าส์เพื่ออ่านข้อมูลที่ได้รับการทําความสะอาดที่คุณสร้างขึ้นในสมุดบันทึกก่อนหน้า
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
สร้างการทดลองสําหรับการติดตามและบันทึกแบบจําลองโดยใช้ MLflow
ส่วนนี้สาธิตวิธีการสร้างการทดลอง ระบุแบบจําลองการเรียนรู้ของเครื่องและพารามิเตอร์การฝึกอบรม ตลอดจนเมตริกการให้คะแนน ฝึกแบบจําลองการเรียนรู้ของเครื่อง บันทึกและบันทึกแบบจําลองที่ได้รับการฝึกอบรมสําหรับการใช้งานในภายหลัง
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment" # MLflow experiment name
การขยายความสามารถในการบันทึกอัตโนมัติของ MLflow การล็อกอัตโนมัติทํางานโดยการจับค่าของพารามิเตอร์อินพุตและเมตริกเอาต์พุตของแบบจําลองการเรียนรู้ของเครื่องตามที่ได้รับการฝึกโดยอัตโนมัติ ข้อมูลนี้จะถูกบันทึกไปยังพื้นที่ทํางานของคุณ ซึ่งสามารถเข้าถึงและแสดงภาพได้โดยใช้ API ของ MLflow หรือการทดลองที่สอดคล้องกันในพื้นที่ทํางานของคุณ
การทดลองทั้งหมดที่มีชื่อที่เกี่ยวข้องจะถูกบันทึกและคุณจะสามารถติดตามพารามิเตอร์และเมตริกประสิทธิภาพได้ เมื่อต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ autologging ดู Autologging ใน Microsoft Fabric
ตั้งค่าข้อกําหนดการทดลองและการบันทึกอัตโนมัติ
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
นําเข้า scikit-learn และ LightGBM
ด้วยข้อมูลของคุณคุณจะสามารถกําหนดแบบจําลองการเรียนรู้ของเครื่องได้แล้ว คุณจะใช้แบบจําลองฟอเรสต์แบบสุ่มและ LightGBM ในสมุดบันทึกนี้ ใช้ scikit-learn และ lightgbm เพื่อใช้แบบจําลองภายในโค้ดไม่กี่บรรทัด
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
เตรียมการฝึกอบรม การตรวจสอบความถูกต้อง และการทดสอบชุดข้อมูล
train_test_splitใช้ฟังก์ชันจาก scikit-learn เพื่อแยกข้อมูลลงในการฝึกอบรม การตรวจสอบความถูกต้อง และชุดการทดสอบ
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
บันทึกข้อมูลทดสอบไปยังตาราง Delta
บันทึกข้อมูลทดสอบไปยังตาราง Delta สําหรับการใช้งานในสมุดบันทึกถัดไป
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
นํา SMOTE ไปใช้กับข้อมูลการฝึกเพื่อสังเคราะห์ตัวอย่างใหม่สําหรับคลาสรอง
การสํารวจข้อมูลในส่วนที่ 2 แสดงให้เห็นว่าจุดข้อมูลทั้งหมด 10,000 จุดที่สอดคล้องกับลูกค้า 10,000 ราย มีลูกค้าเพียง 2,037 ราย (ประมาณ 20%) ออกจากธนาคาร ซึ่งแสดงว่าชุดข้อมูลไม่สมดุลอย่างมาก ปัญหาเกี่ยวกับการจัดประเภทแบบไม่สมดุลคือมีตัวอย่างน้อยเกินไปของคลาสน้อยสําหรับแบบจําลองเพื่อเรียนรู้ขอบเขตการตัดสินใจอย่างมีประสิทธิภาพ SMOTE เป็นวิธีที่ใช้กันอย่างแพร่หลายที่สุดในการสังเคราะห์ตัวอย่างใหม่สําหรับคลาสรอง เรียนรู้เพิ่มเติมเกี่ยวกับ SMOTE ที่นี่และที่นี่
เคล็ดลับ
โปรดทราบว่า SMOTE ควรนําไปใช้กับชุดข้อมูลการฝึกอบรมเท่านั้น คุณต้องออกจากชุดข้อมูลทดสอบในการกระจายแบบไม่สมดุลเดิมเพื่อรับประมาณการที่ถูกต้องว่าแบบจําลองการเรียนรู้ของเครื่องจะดําเนินการกับข้อมูลเดิมอย่างไรซึ่งแสดงถึงสถานการณ์ในการผลิต
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
เคล็ดลับ
คุณสามารถละเว้นข้อความเตือน MLflow ที่ปรากฏขึ้นเมื่อคุณเรียกใช้เซลล์นี้
ถ้าคุณเห็น ข้อความ ModuleNotFoundError แสดงว่าคุณไม่ได้เรียกใช้เซลล์แรกในสมุดบันทึกนี้ ซึ่งจะติดตั้ง imblearn ไลบรารี คุณจําเป็นต้องติดตั้งไลบรารีนี้ทุกครั้งที่คุณเริ่มสมุดบันทึกใหม่ ย้อนกลับและเรียกใช้เซลล์ทั้งหมดใหม่โดยเริ่มต้นด้วยเซลล์แรกในสมุดบันทึกนี้
การฝึกแบบจําลอง
- ฝึกแบบจําลองโดยใช้ฟอเรสต์แบบสุ่มที่มีความลึกสูงสุด 4 และ 4 คุณสมบัติ
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- ฝึกแบบจําลองโดยใช้ Random Forest ที่มีความลึกสูงสุด 8 และ 6 คุณสมบัติ
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
- ฝึกแบบจําลองโดยใช้ LightGBM
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
วัตถุทดลองสําหรับการติดตามประสิทธิภาพของแบบจําลอง
การเรียกใช้การทดสอบจะถูกบันทึกไว้ในอาร์ติแฟกตการทดลองที่สามารถพบได้จากพื้นที่ทํางานโดยอัตโนมัติ โดยชื่อจะถูกตั้งชื่อตามชื่อที่ใช้สําหรับการตั้งค่าการทดลอง แบบจําลองการเรียนรู้ของเครื่องที่ได้รับการฝึกทั้งหมด การเรียกใช้ เมตริกประสิทธิภาพ และพารามิเตอร์แบบจําลองจะถูกบันทึกไว้
วิธีดูการทดลองของคุณ:
บนแผงด้านซ้าย ให้เลือกพื้นที่ทํางานของคุณ
ที่ด้านบนขวา กรองให้แสดงเฉพาะการทดลอง เพื่อให้ง่ายต่อการค้นหาการทดลองที่คุณกําลังค้นหา
ค้นหาและเลือกชื่อการทดสอบ ในกรณีนี้คือ การทดสอบการเลิกใช้บริการธนาคาร หากคุณไม่เห็นการทดสอบในพื้นที่ทํางานของคุณ ให้รีเฟรชเบราว์เซอร์ของคุณ



ประเมินประสิทธิภาพของแบบจําลองที่ได้รับการฝึกบนชุดข้อมูลการตรวจสอบความถูกต้อง
เมื่อทําเสร็จแล้วด้วยการฝึกอบรมแบบจําลองการเรียนรู้ของเครื่อง คุณสามารถประเมินประสิทธิภาพของแบบจําลองที่ได้รับการฝึกแล้วได้สองวิธี
เปิดการทดลองที่บันทึกไว้จากพื้นที่ทํางาน โหลดแบบจําลองการเรียนรู้ของเครื่อง และจากนั้นประเมินประสิทธิภาพของแบบจําลองที่โหลดบนชุดข้อมูลการตรวจสอบความถูกต้อง
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBMประเมินประสิทธิภาพของแบบจําลองการเรียนรู้ของเครื่องที่ได้รับการฝึกโดยตรงบนชุดข้อมูลการตรวจสอบความถูกต้อง
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
ทั้งนี้ขึ้นอยู่กับความชอบของคุณ วิธีการอย่างใดอย่างหนึ่งก็เป็นเรื่องที่ดีและควรมีประสิทธิภาพการทํางานที่เหมือนกัน ในสมุดบันทึกนี้ คุณจะเลือกวิธีแรกเพื่อแสดงให้เห็นถึงความสามารถในการบันทึกอัตโนมัติของ MLflow ใน Microsoft Fabric ได้ดียิ่งขึ้น
แสดงค่าบวก/ค่าลบจริง/เท็จโดยใช้เมทริกซ์ความสับสน
ถัดไป คุณจะพัฒนาสคริปต์เพื่อลงจุดเมทริกซ์ความสับสนเพื่อประเมินความถูกต้องของการจัดประเภทโดยใช้ชุดข้อมูลการตรวจสอบความถูกต้อง เมทริกซ์ความสับสนสามารถลงจุดได้โดยใช้เครื่องมือ SynapseML เช่นกัน ซึ่งแสดงในตัวอย่างการตรวจจับการฉ้อโกงที่พร้อมใช้งานที่นี่
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
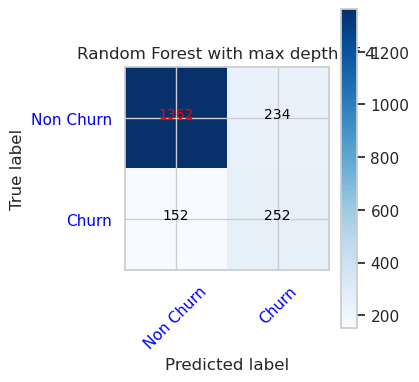
- เมทริกซ์ความสับสนสําหรับตัวจําแนกประเภทฟอเรสต์แบบสุ่มที่มีความลึกสูงสุด 4 และ 4 คุณสมบัติ
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
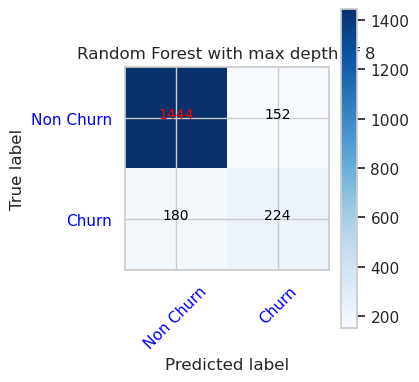
- เมทริกซ์ความสับสนสําหรับตัวจําแนกประเภทฟอเรสต์แบบสุ่มที่มีความลึกสูงสุด 8 และ 6 คุณสมบัติ
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
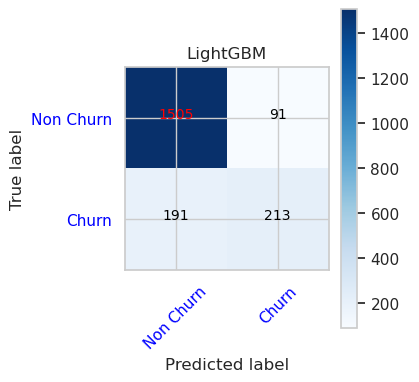
- เมทริกซ์ความสับสนสําหรับ LightGBM
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()