สูตรอาหาร: บริการ Azure AI - การตรวจหาสิ่งผิดปกติที่หลากหลาย
สูตรนี้แสดงให้เห็นว่าคุณสามารถใช้บริการ SynapseML และ Azure AI บน Apache Spark สําหรับการตรวจหาสิ่งผิดปกติที่หลากหลายได้อย่างไร การตรวจหาสิ่งผิดปกติแบบหลากหลายรูปแบบช่วยให้สามารถตรวจหาสิ่งผิดปกติระหว่างตัวแปรหรืออนุกรมเวลาจํานวนมากโดยคํานึงถึงความสัมพันธ์ทั้งหมดและการขึ้นต่อกันระหว่างตัวแปรที่แตกต่างกัน ในสถานการณ์นี้ เราใช้ SynapseML เพื่อฝึกแบบจําลองสําหรับการตรวจหาสิ่งผิดปกติที่หลากหลายโดยใช้บริการ Azure AI และจากนั้นเราใช้แบบจําลองเพื่ออนุมานความผิดปกติที่หลากหลายภายในชุดข้อมูลที่ประกอบด้วยการวัดผลแบบสังเคราะห์จากเซ็นเซอร์ IoT สามตัว
สำคัญ
ตั้งแต่วันที่ 20 กันยายน 2023 คุณจะไม่สามารถสร้างทรัพยากรตัวตรวจหาสิ่งผิดปกติใหม่ได้ บริการตัวตรวจจับสิ่งผิดปกติจะถูกยกเลิกในวันที่ 1 ตุลาคม 2026
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับตัวตรวจจับสิ่งผิดปกติของ Azure AI โปรดดู ที่หน้าเอกสารประกอบนี้
ข้อกำหนดเบื้องต้น
- การสมัครใช้งาน Azure - สร้างฟรีหนึ่งรายการ
- แนบสมุดบันทึกของคุณเข้ากับเลคเฮ้าส์ ทางด้านซ้าย เลือก เพิ่ม เพื่อเพิ่มเลคเฮาส์ที่มีอยู่หรือสร้างเลคเฮ้าส์
ตั้งค่า
ทําตามคําแนะนําเพื่อสร้าง Anomaly Detector ทรัพยากรโดยใช้พอร์ทัล Azure หรืออีกวิธีหนึ่งคือ คุณยังสามารถใช้ Azure CLI เพื่อสร้างทรัพยากรนี้
หลังจากที่คุณตั้งค่า Anomaly Detectorคุณสามารถสํารวจวิธีการจัดการข้อมูลของแบบฟอร์มต่างๆ ได้ แค็ตตาล็อกของบริการภายใน Azure AI มีหลายตัวเลือก: วิสัยทัศน์, คําพูด, ภาษา, การค้นหาบนเว็บ, การตัดสินใจ, การแปลและตัวแสดงเอกสาร
สร้างทรัพยากรตัวตรวจหาความผิดปกติ
- ในพอร์ทัล Azure เลือก สร้าง ในกลุ่มทรัพยากรของคุณ จากนั้นพิมพ์ ตัวตรวจหาสิ่งผิดปกติ เลือกทรัพยากรตัวตรวจหาความผิดปกติ
- ตั้งชื่อทรัพยากร และใช้ภูมิภาคเดียวกันกับกลุ่มทรัพยากรที่เหลือของคุณ ใช้ตัวเลือกเริ่มต้นสําหรับส่วนที่เหลือ จากนั้นเลือก ตรวจสอบ + สร้าง แล้วเลือก สร้าง
- เมื่อสร้างทรัพยากรตัวตรวจจับสิ่งผิดปกติแล้ว ให้เปิดและเลือก
Keys and Endpointsแผงในการนําทางด้านซ้าย คัดลอกคีย์สําหรับทรัพยากรตัวตรวจหาสิ่งผิดปกติลงในANOMALY_API_KEYตัวแปรสภาพแวดล้อม หรือเก็บไว้ในanomalyKeyตัวแปร
สร้างทรัพยากรบัญชีเก็บข้อมูล
เมื่อต้องการบันทึกข้อมูลระดับกลาง คุณจําเป็นต้องสร้างบัญชีที่เก็บข้อมูล Azure Blob ภายในบัญชีที่เก็บข้อมูล ให้สร้างคอนเทนเนอร์สําหรับการจัดเก็บข้อมูลระดับกลาง สร้างบันทึกย่อของชื่อคอนเทนเนอร์ และคัดลอกสายอักขระการเชื่อมต่อไปยังคอนเทนเนอร์นั้น คุณจะต้องใช้ข้อมูลในภายหลังเพื่อเติม containerName ตัวแปรและ BLOB_CONNECTION_STRING ตัวแปรสภาพแวดล้อม
ป้อนคีย์บริการของคุณ
มาเริ่มต้นด้วยการตั้งค่าตัวแปรสภาพแวดล้อมสําหรับคีย์บริการของเรา เซลล์ถัดไปตั้งค่า ANOMALY_API_KEY และ BLOB_CONNECTION_STRING ตัวแปรสภาพแวดล้อมโดยยึดตามค่าที่จัดเก็บไว้ใน Azure Key Vault ของเรา ถ้าคุณกําลังเรียกใช้บทช่วยสอนนี้ในสภาพแวดล้อมของคุณเอง ตรวจสอบให้แน่ใจว่าคุณได้ตั้งค่าตัวแปรสภาพแวดล้อมเหล่านี้ก่อนที่คุณจะดําเนินการต่อ
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
ในตอนนี้ เรามาอ่านANOMALY_API_KEYตัวแปรสภาพแวดล้อม และ BLOB_CONNECTION_STRING และตั้งค่าcontainerNameตัวแปร และlocation
# An Anomaly Dectector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
ก่อนอื่นเราเชื่อมต่อกับบัญชีเก็บข้อมูลของเราเพื่อให้เครื่องตรวจจับสิ่งผิดปกติสามารถบันทึกผลลัพธ์ระดับกลางได้ที่นั่น:
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
ลองนําเข้ามอดูลที่จําเป็นทั้งหมด
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.cognitive import *
ตอนนี้ เรามาอ่านข้อมูลตัวอย่างของเราใน Spark DataFrame กัน
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
ขณะนี้เราสามารถสร้างวัตถุ estimator ซึ่งใช้เพื่อฝึกแบบจําลองของเราได้ เราระบุเวลาเริ่มต้นและสิ้นสุดสําหรับข้อมูลการฝึก นอกจากนี้เรายังระบุคอลัมน์อินพุตที่จะใช้และชื่อของคอลัมน์ที่มีการประทับเวลา สุดท้ายเราระบุจํานวนจุดข้อมูลที่จะใช้ในหน้าต่างบานเลื่อนการตรวจหาสิ่งผิดปกติ และเราตั้งค่าสายอักขระการเชื่อมต่อเป็นบัญชีที่เก็บข้อมูล Azure Blob
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
ตอนนี้เราได้สร้าง estimatorให้พอดีกับข้อมูล:
model = estimator.fit(df)
```parameter
Once the training is done, we can now use the model for inference. The code in the next cell specifies the start and end times for the data we would like to detect the anomalies in.
```python
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
เมื่อเราเรียก .show(5) ในเซลล์ก่อนหน้า มันแสดงให้เราเห็นห้าแถวแรกใน dataframe ผลลัพธ์คือทั้งหมด null เนื่องจากไม่ได้อยู่ภายในหน้าต่างการอนุมาน
เมื่อต้องแสดงผลลัพธ์สําหรับข้อมูลอนุมานเท่านั้น ให้เลือกคอลัมน์ที่เราต้องการ จากนั้นเราสามารถเรียงลําดับแถวใน dataframe จากน้อยไปหามาก และกรองผลลัพธ์เพื่อแสดงเฉพาะแถวที่อยู่ในช่วงของการอนุมานหน้าต่างการอนุมานได้ ในกรณี inferenceEndTime ของเราเหมือนกับแถวสุดท้ายใน dataframe ดังนั้นสามารถเพิกเฉยได้
สุดท้าย เพื่อให้สามารถลงจุดผลลัพธ์ได้ดียิ่งขึ้น ให้แปลงกรอบข้อมูล Spark เป็นกรอบข้อมูล Pandas
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
contributorsจัดรูปแบบคอลัมน์ที่จัดเก็บคะแนนการสนับสนุนจากแต่ละเซนเซอร์ไปยังความผิดปกติที่ตรวจพบ เซลล์ถัดไปจัดรูปแบบข้อมูลนี้ และแยกคะแนนการสนับสนุนของแต่ละเซนเซอร์ลงในคอลัมน์ของตนเอง
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
เยี่ยม! ขณะนี้เรามีคะแนนการจัดสรรของเซ็นเซอร์ 1, 2 และ 3 ใน series_0คอลัมน์ , series_1และ series_2 ตามลําดับ
เรียกใช้เซลล์ถัดไปเพื่อลงจุดผลลัพธ์ พารามิเตอร์ minSeverity ระบุความรุนแรงต่ําสุดของความผิดปกติที่จะลงจุด
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
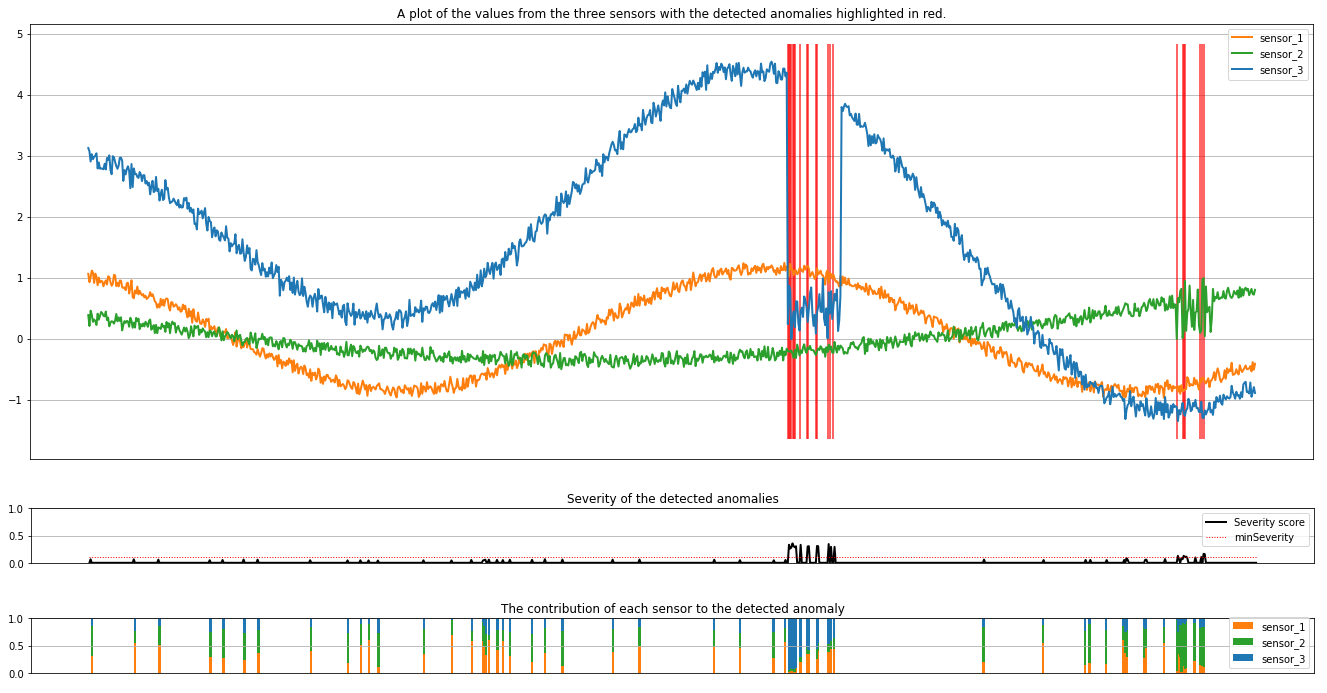
พล็อตแสดงข้อมูลดิบจากเซ็นเซอร์ (ภายในหน้าต่างการอนุมาน) เป็นสีส้ม สีเขียว และสีน้ําเงิน เส้นแนวตั้งสีแดงในรูปภาพแรกแสดงความผิดปกติที่ตรวจพบที่มีความรุนแรงมากกว่าหรือเท่ากับminSeverity
การลงจุดที่สองแสดงคะแนนความรุนแรงของสิ่งผิดปกติที่ตรวจพบทั้งหมด โดยมี minSeverity ค่าเกณฑ์ที่แสดงในบรรทัดสีแดงแบบจุด
ในตอนท้าย แผนภูมิสุดท้ายแสดงการสนับสนุนข้อมูลจากแต่ละเซนเซอร์ไปยังความผิดปกติที่ตรวจพบ ซึ่งช่วยให้เราวินิจฉัยและทําความเข้าใจสาเหตุที่เป็นไปได้มากที่สุดของแต่ละสิ่งผิดปกติ