แบบจําลองการเรียนรู้ของเครื่องใน Microsoft Fabric
แบบจําลองการเรียนรู้ของเครื่องเป็นไฟล์ที่ได้รับการฝึกฝนเพื่อจดจํารูปแบบบางประเภท คุณฝึกแบบจําลองผ่านชุดข้อมูลและคุณให้ข้อมูลด้วยอัลกอริทึมที่ใช้เพื่อเหตุผลและเรียนรู้จากชุดข้อมูลนั้น หลังจากที่คุณฝึกแบบจําลองแล้ว คุณสามารถใช้เพื่อหาเหตุผลในข้อมูลที่ไม่เคยเห็นมาก่อน และทําการคาดการณ์เกี่ยวกับข้อมูลนั้นได้
ใน MLflow แบบจําลองการเรียนรู้ของเครื่องสามารถมีหลายรุ่นแบบจําลองได้ ที่นี่ แต่ละเวอร์ชันสามารถแสดงการทําซ้ําแบบจําลอง ในบทความนี้ คุณจะได้เรียนรู้วิธีการโต้ตอบกับแบบจําลอง ML เพื่อติดตามและเปรียบเทียบเวอร์ชันแบบจําลอง
สร้างแบบจําลองการเรียนรู้ของเครื่อง
ใน MLflow แบบจําลองการเรียนรู้ของเครื่องมีรูปแบบบรรจุภัณฑ์มาตรฐาน รูปแบบนี้อนุญาตให้ใช้แบบจําลองเหล่านั้นในเครื่องมือปลายทางต่าง ๆ รวมถึงการอนุมานชุดบน Apache Spark รูปแบบกําหนดหลักทั่วไปเพื่อบันทึกแบบจําลองใน "รสชาติ" ที่แตกต่างกันที่เครื่องมือปลายทางที่แตกต่างกันสามารถเข้าใจได้
คุณสามารถสร้างแบบจําลองการเรียนรู้ของเครื่องได้โดยตรงจาก Fabric UI นอกจากนี้ MLflow API ยังสามารถสร้างแบบจําลองได้โดยตรง
หากต้องการสร้างแบบจําลองการเรียนรู้ของเครื่องจาก UI คุณสามารถ:
- สร้างพื้นที่ทํางานวิทยาศาสตร์ข้อมูลใหม่ หรือเลือกพื้นที่ทํางานวิทยาศาสตร์ข้อมูลที่มีอยู่
- สร้างพื้นที่ทํางานใหม่หรือเลือกพื้นที่ทํางานที่มีอยู่
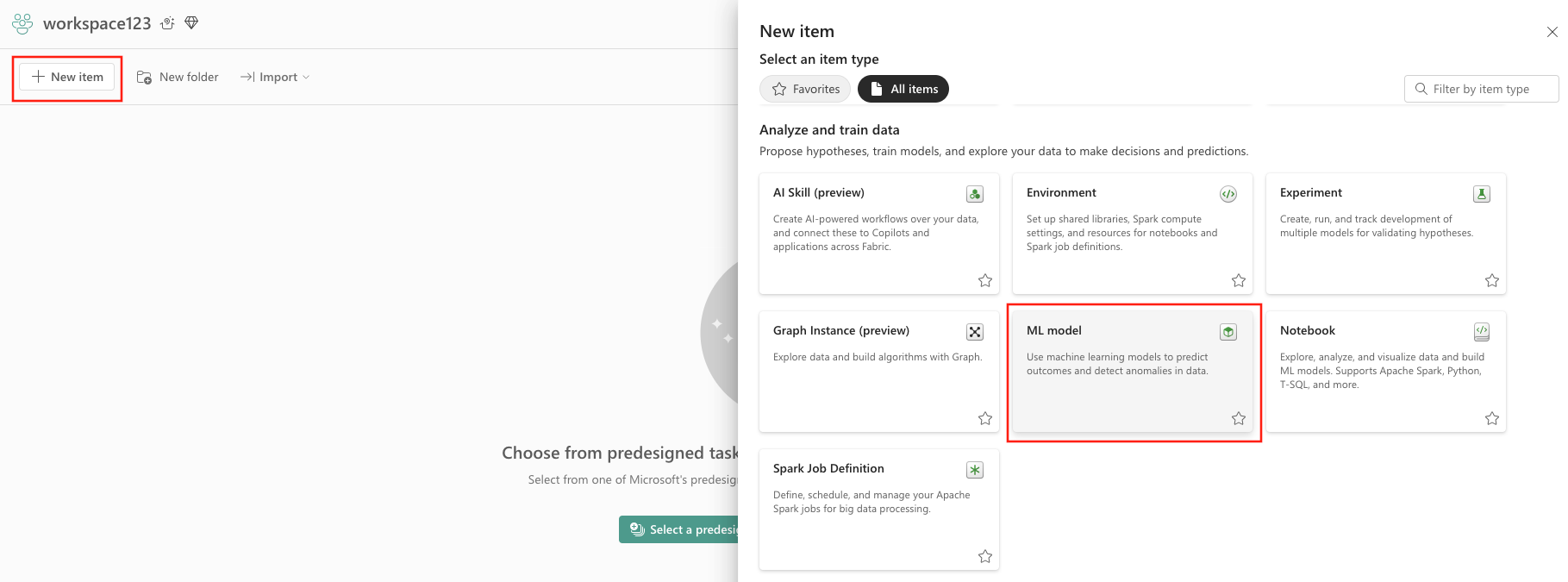
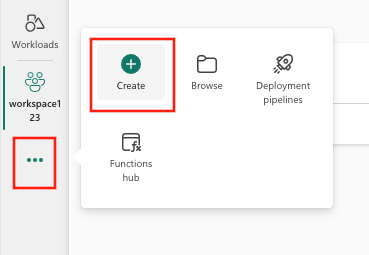
- คุณสามารถสร้างรายการใหม่ผ่านพื้นที่ทํางาน หรือโดยใช้ สร้าง ได้
- พื้นที่:
- เลือกพื้นที่ทํางานของคุณ
- เลือก รายการใหม่
- เลือก แบบจําลอง ML ภายใต้ วิเคราะห์และฝึกข้อมูล
- สร้างปุ่ม:
- เลือก สร้างซึ่งสามารถพบได้ใน ... จากเมนูแนวตั้ง
- เลือก
แบบจําลอง ML ภายใต้วิทยาศาสตร์ข้อมูล 
- เลือก สร้างซึ่งสามารถพบได้ใน ... จากเมนูแนวตั้ง
- พื้นที่:
- หลังจากการสร้างแบบจําลอง คุณสามารถเริ่มเพิ่มเวอร์ชันแบบจําลองเพื่อติดตามเมตริกและพารามิเตอร์การเรียกใช้ได้ ลงทะเบียนหรือบันทึกการเรียกใช้การทดสอบไปยังแบบจําลองที่มีอยู่



คุณยังสามารถสร้างแบบจําลองการเรียนรู้ของเครื่องได้โดยตรงจากประสบการณ์การเขียนของคุณด้วย mlflow.register_model() API ถ้าไม่มีแบบจําลองการเรียนรู้ของเครื่องที่ลงทะเบียนที่มีชื่อที่ระบุอยู่ API จะสร้างโดยอัตโนมัติ
import mlflow
model_uri = "runs:/{}/model-uri-name".format(run.info.run_id)
mv = mlflow.register_model(model_uri, "model-name")
print("Name: {}".format(mv.name))
print("Version: {}".format(mv.version))
จัดการเวอร์ชันภายในแบบจําลองการเรียนรู้ของเครื่อง
แบบจําลองการเรียนรู้ของเครื่องประกอบด้วยคอลเลกชันของเวอร์ชันแบบจําลองสําหรับการติดตามและการเปรียบเทียบที่ง่ายดาย ภายในแบบจําลอง นักวิทยาศาสตร์ข้อมูลสามารถนําทางในแบบจําลองในเวอร์ชันต่างๆ เพื่อสํารวจพารามิเตอร์และเมตริกพื้นฐานได้ นักวิทยาศาสตร์ข้อมูลยังสามารถทําการเปรียบเทียบในแบบจําลองในเวอร์ชันต่างๆ เพื่อระบุว่าแบบจําลองที่ใหม่กว่าอาจให้ผลลัพธ์ที่ดีกว่าหรือไม่
ติดตามแบบจําลองการเรียนรู้ของเครื่อง
เวอร์ชันแบบจําลองการเรียนรู้ของเครื่องแสดงถึงแบบจําลองแต่ละแบบที่ลงทะเบียนไว้สําหรับการติดตาม
![]()
แต่ละรุ่นแบบจําลองประกอบด้วยข้อมูลต่อไปนี้:
- เวลาที่สร้าง: วันที่และเวลาของการสร้างแบบจําลอง
- ชื่อการเรียกใช้ : ตัวระบุสําหรับการเรียกใช้การทดสอบที่ใช้ในการสร้างรุ่นแบบจําลองเฉพาะนี้
- Hyperparameters: Hyperparameters จะถูกบันทึกเป็นคู่ค่าคีย์ ทั้งคีย์และค่าเป็นสตริง
- เมตริก: เรียกใช้เมตริกที่บันทึกไว้เป็นคู่ค่าคีย์ ค่าเป็นตัวเลข
- Schema/ลายเซ็น: คําอธิบายของอินพุทและเอาต์พุตแบบจําลอง
- บันทึกไฟล์: ไฟล์บันทึกในรูปแบบใด ๆ ตัวอย่างเช่น คุณสามารถบันทึกรูปภาพ สภาพแวดล้อม แบบจําลอง และไฟล์ข้อมูล
- Tags: เมตาดาต้าเป็นคู่ค่าคีย์ที่จะเรียกใช้
ใช้แท็กกับแบบจําลองการเรียนรู้ของเครื่อง
การแท็ก MLflow สําหรับเวอร์ชันแบบจําลองช่วยให้ผู้ใช้สามารถแนบเมตาดาต้าแบบกําหนดเองกับรุ่นเฉพาะของแบบจําลองที่ลงทะเบียนไว้ในรีจิสทรีแบบจําลอง MLflow แท็กเหล่านี้ จัดเก็บเป็นคู่คีย์-ค่า ช่วยในการจัดระเบียบ ติดตาม และแยกความแตกต่างระหว่างรุ่นแบบจําลอง ทําให้ง่ายต่อการจัดการวงจรชีวิตแบบจําลอง แท็กสามารถใช้เพื่อแสดงวัตถุประสงค์ของแบบจําลอง สภาพแวดล้อมการปรับใช้ หรือข้อมูลอื่น ๆ ที่เกี่ยวข้อง การอํานวยความสะดวกในการจัดการแบบจําลองที่มีประสิทธิภาพมากขึ้นและการตัดสินใจภายในทีม
รหัสนี้สาธิตวิธีการฝึกแบบจําลอง RandomForestRegressor โดยใช้ Scikit-learn บันทึกแบบจําลองและพารามิเตอร์ด้วย MLflow จากนั้นลงทะเบียนแบบจําลองในรีจิสทรีแบบจําลอง MLflow ด้วยแท็กแบบกําหนดเอง แท็กเหล่านี้ให้เมตาดาต้าที่มีประโยชน์ เช่น ชื่อโครงการ ทีม และไตรมาสของโครงการ ทําให้ง่ายต่อการจัดการและติดตามเวอร์ชันแบบจําลอง
import mlflow.sklearn
from mlflow.models import infer_signature
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
# Generate synthetic regression data
X, y = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
# Model parameters
params = {"n_estimators": 3, "random_state": 42}
# Model tags for MLflow
model_tags = {
"project_name": "grocery-forecasting",
"store_dept": "produce",
"team": "stores-ml",
"project_quarter": "Q3-2023"
}
# Log MLflow entities
with mlflow.start_run() as run:
# Train the model
model = RandomForestRegressor(**params).fit(X, y)
# Infer the model signature
signature = infer_signature(X, model.predict(X))
# Log parameters and the model
mlflow.log_params(params)
mlflow.sklearn.log_model(model, artifact_path="sklearn-model", signature=signature)
# Register the model with tags
model_uri = f"runs:/{run.info.run_id}/sklearn-model"
model_version = mlflow.register_model(model_uri, "RandomForestRegressionModel", tags=model_tags)
# Output model registration details
print(f"Model Name: {model_version.name}")
print(f"Model Version: {model_version.version}")
หลังจากใช้แท็กแล้วคุณสามารถดูได้โดยตรงบนหน้ารายละเอียดเวอร์ชันแบบจําลอง นอกจากนี้ แท็กสามารถเพิ่ม อัปเดต หรือลบออกจากเพจนี้ได้ทุกเมื่อ

เปรียบเทียบและกรองแบบจําลองการเรียนรู้ของเครื่อง
เพื่อเปรียบเทียบและประเมินคุณภาพของเวอร์ชันแบบจําลองการเรียนรู้ของเครื่อง คุณสามารถเปรียบเทียบพารามิเตอร์ เมตริก และเมตาดาต้าระหว่างเวอร์ชันที่เลือกได้
เปรียบเทียบแบบจําลองการเรียนรู้ของเครื่องด้วยภาพ
คุณสามารถเปรียบเทียบการเรียกใช้ภายในแบบจําลองที่มีอยู่ได้ด้วยตา การเปรียบเทียบวิชวลช่วยให้การนําทางระหว่างและการเรียงลําดับในหลายเวอร์ชันเป็นเรื่องง่าย

เพื่อเปรียบเทียบการเรียกใช้ คุณสามารถ:
- เลือกแบบจําลองการเรียนรู้ของเครื่องที่มีอยู่ที่มีหลายเวอร์ชัน
- เลือกแท็บ มุมมอง จากนั้นนําทางไปยังรายการ แบบจําลอง มุมมอง คุณยังสามารถเลือกตัวเลือก ดูรายการแบบจําลอง ได้โดยตรงจากมุมมองรายละเอียด
- คุณสามารถกําหนดคอลัมน์ภายในตารางได้ ขยาย กําหนดคอลัมน์ บานหน้าต่างเอง จากนั้น คุณสามารถเลือกคุณสมบัติ เมตริก แท็ก และ hyperparameters ที่คุณต้องการดูได้
- สุดท้าย คุณสามารถเลือกหลายเวอร์ชันเพื่อเปรียบเทียบผลลัพธ์ในบานหน้าต่างการเปรียบเทียบเมตริก จากบานหน้าต่างนี้ คุณสามารถกําหนดแผนภูมิที่มีการเปลี่ยนแปลงชื่อเรื่องแผนภูมิ ชนิดการแสดงภาพ แกน X แกน Y และอื่น ๆ ได้
เปรียบเทียบแบบจําลองการเรียนรู้ของเครื่องโดยใช้ MLflow API
นักวิทยาศาสตร์ข้อมูลยังสามารถใช้ MLflow เพื่อค้นหาในหลายแบบจําลองที่บันทึกไว้ภายในพื้นที่ทํางานได้ ไปที่เอกสารประกอบ MLflow เพื่อสํารวจ MLflow API อื่น ๆ สําหรับการโต้ตอบแบบจําลอง
from pprint import pprint
client = MlflowClient()
for rm in client.list_registered_models():
pprint(dict(rm), indent=4)
ใช้แบบจําลองการเรียนรู้ของเครื่อง
เมื่อคุณฝึกแบบจําลองบนชุดข้อมูล คุณสามารถนําแบบจําลองนั้นไปใช้กับข้อมูลที่ไม่เคยเห็นเพื่อสร้างการคาดการณ์ เราเรียกเทคนิคการใช้แบบจําลองนี้ การให้คะแนน หรือ การอนุมาน สําหรับข้อมูลเพิ่มเติมเกี่ยวกับการให้คะแนนแบบจําลอง Microsoft Fabric โปรดดูส่วนถัดไป
เนื้อหาที่เกี่ยวข้อง
- เรียนรู้เกี่ยวกับ การทดลอง MLflow