กําหนดค่าฐานข้อมูล SQL ในกิจกรรมการคัดลอก (ตัวอย่าง)
บทความนี้สรุปวิธีการใช้กิจกรรมการคัดลอกในไปป์ไลน์ข้อมูลเพื่อคัดลอกข้อมูลจากและไปยังฐานข้อมูล SQL
การกําหนดค่าที่ได้รับการสนับสนุน
สําหรับการกําหนดค่าของแต่ละแท็บภายใต้กิจกรรมการคัดลอก ให้ไปที่ส่วนต่อไปนี้ตามลําดับ
- ทั่วไปเกี่ยวกับ
- แหล่งข้อมูลของ
- ปลายทางของ
- การแมป
- การตั้งค่า
ทั่วไป
โปรดดูคําแนะนํา การตั้งค่า ทั่วไปของ
ที่มา
คุณสมบัติต่อไปนี้ได้รับการสนับสนุนสําหรับฐานข้อมูล SQL ภายใต้แท็บ Source ของกิจกรรมการคัดลอก

คุณสมบัติต่อไปนี้ ที่จําเป็น :
การเชื่อมต่อ : เลือกฐานข้อมูล SQL ที่มีอยู่ อ้างอิงถึงขั้นตอนในบทความ นี้
ใช้ คิวรี : คุณสามารถเลือกตารางคิวรี หรือ Stored Procedure รายการต่อไปนี้อธิบายถึงการกําหนดค่าของแต่ละการตั้งค่า:ตาราง : ระบุชื่อของฐานข้อมูล SQL เพื่ออ่านข้อมูล เลือกตารางที่มีอยู่จากรายการดรอปดาวน์ หรือเลือก Enter ด้วยตนเองเพื่อป้อนชื่อสคีมาและชื่อตาราง
คิวรี : ระบุคิวรี SQL แบบกําหนดเองเพื่ออ่านข้อมูล ตัวอย่างคือ
select * from MyTableหรือเลือกไอคอนดินสอเพื่อแก้ไขในตัวแก้ไขโค้ด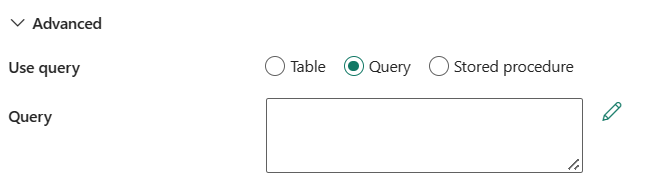
Stored Procedure: เลือกกระบวนงานที่เก็บไว้จากรายการดรอปดาวน์

ภายใต้ ขั้นสูง คุณสามารถระบุเขตข้อมูลต่อไปนี้:
หมดเวลาคิวรี (นาที): ระบุการหมดเวลาสําหรับการดําเนินการคําสั่งแบบสอบถาม ค่าเริ่มต้นคือ 120 นาที ถ้าพารามิเตอร์ถูกตั้งค่าสําหรับคุณสมบัตินี้ ค่าที่อนุญาตคือ timespan เช่น "02:00:00" (120 นาที)
ภาพหน้าจอ

ระดับการแยก : ระบุลักษณะการทํางานของการล็อคธุรกรรมสําหรับแหล่งข้อมูล SQL ค่าที่อนุญาตคือ:ผูกมัดการอ่าน
อ่าน ที่ไม่ได้ผูกมัดการอ่านที่ทําซ้ําได้ แบบอนุกรมได้ หรือ สแนปช็อต โปรดดูสําหรับรายละเอียดเพิ่มเติม ภาพหน้าจอ
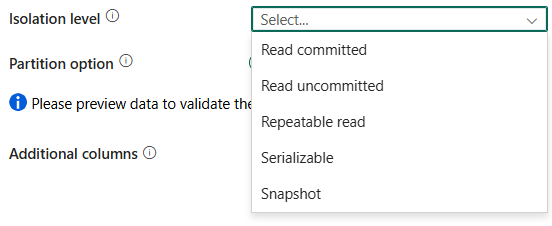
ตัวเลือกพาร์ติชัน: ระบุตัวเลือกการแบ่งพาร์ติชันข้อมูลที่ใช้ในการโหลดข้อมูลจากฐานข้อมูล SQL ค่าที่อนุญาตคือ: ไม่มี (ค่าเริ่มต้น), พาร์ติชันจริงของตารางและ ช่วงไดนามิก เมื่อเปิดใช้งานตัวเลือกพาร์ติชัน (นั่นคือไม่ ไม่มี) ระดับความขนานในการโหลดข้อมูลจากฐานข้อมูล SQL พร้อมกันจะถูกควบคุมโดย องศาของการคัดลอกแบบขนาน ในแท็บการตั้งค่ากิจกรรมการคัดลอก
ไม่มี: เลือกการตั้งค่านี้เพื่อไม่ใช้พาร์ติชัน
พาร์ติชันจริง ของตาราง: เมื่อใช้พาร์ติชันจริง คอลัมน์และกลไกของพาร์ติชันจะถูกกําหนดโดยอัตโนมัติโดยยึดตามข้อกําหนดตารางจริงของคุณ
ช่วงไดนามิก: เมื่อใช้คิวรีที่เปิดใช้งานแบบขนาน พารามิเตอร์พาร์ติชันช่วง (
?DfDynamicRangePartitionCondition) เป็นสิ่งจําเป็น คิวรีตัวอย่าง:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionConditionชื่อคอลัมน์พาร์ติชัน: ระบุชื่อของคอลัมน์ต้นทางในชนิดจํานวนเต็ม หรือชนิด วันที่/วันที่เวลา (
int,smallint,bigint,date,smalldatetime,datetime,datetime2หรือdatetimeoffset) ที่ใช้โดยการกําหนดพาร์ติชันช่วงสําหรับสําเนาแบบขนาน ถ้าไม่ได้ระบุ ดัชนีหรือคีย์หลักของตารางจะถูกตรวจสอบโดยอัตโนมัติ และใช้เป็นคอลัมน์พาร์ติชันถ้าคุณใช้คิวรีเพื่อดึงข้อมูลต้นทาง
?DfDynamicRangePartitionConditionhook ในส่วนคําสั่ง WHERE ตัวอย่างเช่น ดูส่วน สําเนาแบบขนานจากฐานข้อมูล SQL Partitionที่ผูกไว้ด้านบน : ระบุค่าสูงสุดของคอลัมน์พาร์ติชันสําหรับการแยกช่วงพาร์ติชัน ค่านี้ใช้เพื่อตัดสินใจว่าจะดําเนินการแบ่งพาร์ติชัน ไม่ใช่สําหรับการกรองแถวในตาราง แถวทั้งหมดในตารางหรือผลลัพธ์คิวรีจะถูกแบ่งพาร์ติชันและคัดลอก ถ้าไม่ได้ระบุ คัดลอกกิจกรรมจะตรวจหาค่าโดยอัตโนมัติ ตัวอย่างเช่น ดูส่วน สําเนา
แบบขนานจากฐานข้อมูล SQL Partition ที่ผูกไว้ต่ํากว่า: ระบุค่าต่ําสุดของคอลัมน์พาร์ติชันสําหรับการแยกช่วงพาร์ติชัน ค่านี้ใช้เพื่อตัดสินใจว่าจะดําเนินการแบ่งพาร์ติชัน ไม่ใช่สําหรับการกรองแถวในตาราง แถวทั้งหมดในตารางหรือผลลัพธ์คิวรีจะถูกแบ่งพาร์ติชันและคัดลอก ถ้าไม่ได้ระบุ คัดลอกกิจกรรมจะตรวจหาค่าโดยอัตโนมัติ ตัวอย่างเช่น ดูส่วน สําเนา
แบบขนานจากฐานข้อมูล SQL
คอลัมน์เพิ่มเติม: เพิ่มคอลัมน์ข้อมูลเพิ่มเติมเพื่อจัดเก็บเส้นทางสัมพัทธ์หรือค่าคงที่ของไฟล์ต้นฉบับ นิพจน์ได้รับการสนับสนุนสําหรับอย่างหลัง สําหรับข้อมูลเพิ่มเติม ไปที่ เพิ่มคอลัมน์เพิ่มเติมในระหว่างการคัดลอก


จุดหมาย
คุณสมบัติต่อไปนี้ได้รับการสนับสนุนสําหรับฐานข้อมูล SQL ภายใต้แท็บ ปลายทาง
ภาพหน้าจอ 
คุณสมบัติต่อไปนี้ ที่จําเป็น :
การเชื่อมต่อ : เลือกฐานข้อมูล SQL ที่มีอยู่ อ้างอิงถึงขั้นตอนในบทความ นี้
ตัวเลือก ตาราง
: เลือกจาก ใช้ ที่มีอยู่ หรือตาราง สร้างอัตโนมัติ ถ้าคุณเลือก ใช้ที่มีอยู่ :
- ตาราง : ระบุชื่อของฐานข้อมูล SQL เพื่อเขียนข้อมูล เลือกตารางที่มีอยู่จากรายการดรอปดาวน์ หรือเลือก Enter ด้วยตนเองเพื่อป้อนชื่อสคีมาและชื่อตาราง
ถ้าคุณเลือก สร้างตารางโดยอัตโนมัติ:
- Table: จะสร้างตาราง (หากไม่มีอยู่) ใน schema ต้นทางโดยอัตโนมัติ ซึ่งไม่ได้รับการรองรับเมื่อใช้ Stored Procedure เป็นลักษณะการทํางานในการเขียน
ภายใต้ ขั้นสูง คุณสามารถระบุเขตข้อมูลต่อไปนี้:
ลักษณะการทํางานการเขียน: กําหนดลักษณะการทํางานการเขียนเมื่อแหล่งข้อมูลคือไฟล์จากที่เก็บข้อมูลตามไฟล์ คุณสามารถเลือก แทรก, Upsert หรือ Stored Procedureได้

แทรก: เลือกตัวเลือกนี้หากข้อมูลต้นฉบับของคุณมีการแทรก
Upsert : เลือกตัวเลือกนี้หากข้อมูลต้นฉบับของคุณมีการแทรกและการอัปเดตทั้ง
ใช้ TempDB: ระบุว่าจะใช้ตารางชั่วคราวส่วนกลางหรือตารางจริงเป็นตารางชั่วคราวสําหรับ upsert ตามค่าเริ่มต้น บริการจะใช้ตารางชั่วคราวส่วนกลางเป็นตารางชั่วคราวและเลือกกล่องกาเครื่องหมายนี้ไว้
ถ้าคุณเขียนข้อมูลจํานวนมากลงในฐานข้อมูล SQL ให้ยกเลิกการเลือกสิ่งนี้และระบุชื่อ Schema ภายใต้ซึ่ง Data Factory จะสร้างตารางการแสดงข้อมูลเพื่อโหลดข้อมูลอัพสตรีมและล้างข้อมูลอัตโนมัติเมื่อเสร็จสิ้น ตรวจสอบให้แน่ใจว่าผู้ใช้มีสิทธิ์ในการสร้างตารางในฐานข้อมูล และแก้ไขสิทธิ์บน Schema ถ้าไม่ได้ระบุ จะใช้ตารางชั่วคราวส่วนกลางเป็นสเตจจิ้ง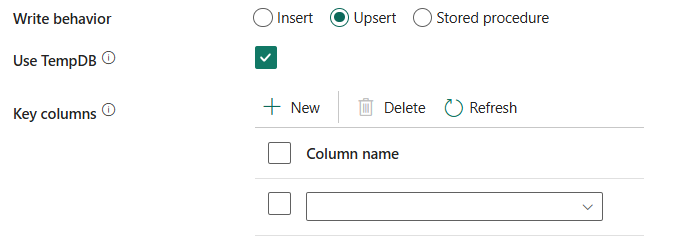
เลือกสคีมา DB ของผู้ใช้: เมื่อไม่ได้เลือก ใช้ TempDB ให้ระบุชื่อ Schema ภายใต้ซึ่ง Data Factory จะสร้างตารางจัดเตรียมเพื่อโหลดข้อมูลต้นทางและล้างข้อมูลโดยอัตโนมัติเมื่อเสร็จสิ้น ตรวจสอบให้แน่ใจว่า คุณมีสิทธิ์ในการสร้างตารางในฐานข้อมูล และแก้ไขสิทธิ์บน Schema
โน้ต
คุณต้องมีสิทธิ์ในการสร้างและลบตาราง ตามค่าเริ่มต้น ตารางระหว่างกลางจะแชร์สคีมาเดียวกันกับตารางปลายทาง
ภาพหน้าจอ
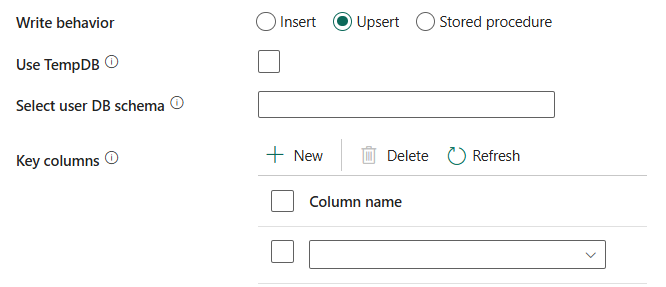
คอลัมน์ คีย์: เลือกคอลัมน์ที่จะใช้เพื่อกําหนดว่าแถวจากต้นทางตรงกับแถวจากปลายทางหรือไม่
ชื่อ Stored Procedure: เลือกกระบวนงานที่เก็บไว้จากรายการดรอปดาวน์
ล็อคแทรกตารางจํานวนมาก : เลือก ใช่ หรือ ไม่มี ใช้การตั้งค่านี้เพื่อปรับปรุงประสิทธิภาพการคัดลอกในระหว่างการดําเนินการแทรกจํานวนมากในตารางที่ไม่มีดัชนีจากหลายไคลเอ็นต์ สําหรับข้อมูลเพิ่มเติม ไปที่ การแทรกจํานวนมาก (Transact-SQL)
สคริปต์ก่อนคัดลอก: ระบุสคริปต์สําหรับกิจกรรมการคัดลอกที่จะดําเนินการก่อนที่จะเขียนข้อมูลลงในตารางปลายทางในการเรียกใช้แต่ละครั้ง คุณสามารถใช้คุณสมบัตินี้ในการล้างข้อมูลที่โหลดไว้ล่วงหน้า
เขียนการหมดเวลาของชุดงาน: ระบุเวลารอสําหรับการดําเนินการแทรกชุดงานเพื่อเสร็จสิ้นก่อนที่จะหมดเวลา ค่าที่อนุญาตคือช่วงเวลา ค่าเริ่มต้นคือ "00:30:00" (30 นาที)
เขียนขนาดชุดงาน: ระบุจํานวนแถวที่จะแทรกลงในตาราง SQL ต่อชุดงาน ค่าที่อนุญาตคือจํานวนเต็ม (จํานวนแถว) ตามค่าเริ่มต้น บริการจะกําหนดขนาดของชุดงานที่เหมาะสมแบบไดนามิกตามขนาดของแถว
การเชื่อมต่อพร้อมกันสูงสุด: ระบุขีดจํากัดสูงสุดของการเชื่อมต่อที่เกิดขึ้นพร้อมกันที่สร้างไปยังที่เก็บข้อมูลในระหว่างการเรียกใช้กิจกรรม ระบุค่าเมื่อคุณต้องการจํากัดการเชื่อมต่อที่เกิดขึ้นพร้อมกันเท่านั้น


การทําแผนที่
สําหรับการกําหนดค่าแท็บ Mapping ถ้าคุณไม่ได้ใช้ฐานข้อมูล SQL ที่มีตารางสร้างอัตโนมัติเป็นปลายทางของคุณ ไปที่ การแมป
ถ้าคุณนําฐานข้อมูล SQL ที่มีตารางสร้างอัตโนมัติเป็นปลายทางของคุณ ยกเว้นการกําหนดค่าใน แมปคุณสามารถแก้ไขชนิดของคอลัมน์ปลายทางของคุณได้ หลังจากเลือก นําเข้า schemaคุณสามารถระบุชนิดคอลัมน์ในปลายทางของคุณได้
ตัวอย่างเช่น ชนิดของคอลัมน์ ID ในแหล่งข้อมูลจะเป็นค่าเป็นข้อความ และคุณสามารถเปลี่ยนเป็นชนิดเลขทศนิยมเมื่อแมปไปยังคอลัมน์ปลายทาง

การตั้งค่า
สําหรับการกําหนดค่าแท็บ การตั้งค่า ให้ไปที่ กําหนดค่าการตั้งค่าอื่น ๆ ของคุณภายใต้แท็บ การตั้งค่า
สําเนาแบบขนานจากฐานข้อมูล SQL
ตัวเชื่อมต่อฐานข้อมูล SQL ในกิจกรรมการคัดลอกมีพาร์ติชันข้อมูลที่มีอยู่ภายในเพื่อคัดลอกข้อมูลแบบขนาน คุณสามารถค้นหาตัวเลือกการแบ่งพาร์ติชันข้อมูลได้ที่แท็บ Source ของกิจกรรมการคัดลอกได้
เมื่อคุณเปิดใช้งานการคัดลอกพาร์ติชัน กิจกรรมการคัดลอกจะเรียกใช้คิวรีแบบขนานกับแหล่งฐานข้อมูล SQL ของคุณเพื่อโหลดข้อมูลตามพาร์ติชัน ระดับขนานจะถูกควบคุมโดย องศาของการคัดลอกแบบขนาน ในแท็บการตั้งค่ากิจกรรมการคัดลอก ตัวอย่างเช่น ถ้าคุณตั้งค่า ระดับ ของการคัดลอกแบบขนาน ถึงสี่ บริการจะสร้างและเรียกใช้คิวรีสี่รายการพร้อมๆ กันโดยยึดตามตัวเลือกและการตั้งค่าพาร์ติชันที่ระบุของคุณ และแต่ละคิวรีจะดึงข้อมูลบางส่วนจากฐานข้อมูล SQL ของคุณ
ขอแนะนําให้คุณเปิดใช้งานสําเนาแบบขนานกับการแบ่งพาร์ติชันข้อมูลโดยเฉพาะอย่างยิ่งเมื่อคุณโหลดข้อมูลจํานวนมากจากฐานข้อมูล SQL ของคุณ ต่อไปนี้คือการกําหนดค่าที่แนะนําสําหรับสถานการณ์ที่แตกต่างกัน เมื่อคัดลอกข้อมูลลงในที่เก็บข้อมูลตามไฟล์ ขอแนะนําให้เขียนไปยังโฟลเดอร์เป็นหลายไฟล์ (ระบุชื่อโฟลเดอร์เท่านั้น) ซึ่งในกรณีนี้ประสิทธิภาพการทํางานจะดีกว่าการเขียนไปยังไฟล์เดียว
| บทภาพยนตร์ | การตั้งค่าที่แนะนํา |
|---|---|
| โหลดทั้งหมดจากตารางขนาดใหญ่ ที่มีพาร์ติชันจริง |
ตัวเลือกพาร์ติชัน: พาร์ติชันจริงของตาราง ในระหว่างการดําเนินการ บริการจะตรวจหาพาร์ติชันจริงโดยอัตโนมัติ และคัดลอกข้อมูลตามพาร์ติชัน เมื่อต้องการตรวจสอบว่าตารางของคุณมีพาร์ติชันจริงหรือไม่คุณสามารถอ้างอิงถึง คิวรีนี้ |
| โหลดทั้งหมดจากตารางขนาดใหญ่ โดยไม่มีพาร์ติชันจริง ในขณะที่มีคอลัมน์จํานวนเต็มหรือวันที่เวลาสําหรับการแบ่งพาร์ติชันข้อมูล |
ตัวเลือกพาร์ติชัน: พาร์ติชันช่วงไดนามิก คอลัมน์ Partition (ไม่บังคับ): ระบุคอลัมน์ที่ใช้ในการแบ่งพาร์ติชันข้อมูล ถ้าไม่ได้ระบุ จะใช้คอลัมน์ดัชนีหรือคีย์หลัก Partition สูงสุดและ พาร์ติชันที่ผูกไว้ต่ํากว่า (ไม่บังคับ): ระบุถ้าคุณต้องการกําหนดการใช้งานพาร์ติชัน ซึ่งไม่ใช่สําหรับการกรองแถวในตาราง แถวทั้งหมดในตารางจะถูกแบ่งพาร์ติชันและคัดลอก ถ้าไม่ได้ระบุ คัดลอกกิจกรรมอัตโนมัติตรวจพบค่า และอาจใช้เวลานานขึ้นอยู่กับค่า MIN และ MAX ขอแนะนําให้ระบุขอบเขตด้านบนและขอบเขตด้านล่าง ตัวอย่างเช่น ถ้าคอลัมน์พาร์ติชัน "ID" ของคุณมีค่าตั้งแต่ 1 ถึง 100 และคุณตั้งค่าต่ําสุดที่ผูกเป็น 20 และขีดจํากัดสูงสุดเป็น 80 พร้อมกับการคัดลอกแบบขนานเป็น 4 บริการจะดึงข้อมูลโดย 4 พาร์ติชัน - ID ในช่วง <=20, [21, 50], [51, 80] และ >=81 ตามลําดับ |
| โหลดข้อมูลจํานวนมากโดยใช้คิวรีแบบกําหนดเอง โดยไม่มีพาร์ติชันจริง ในขณะที่มีคอลัมน์จํานวนเต็มหรือวันที่/วันที่เวลาสําหรับการแบ่งพาร์ติชันข้อมูล |
ตัวเลือกพาร์ติชัน: พาร์ติชันช่วงไดนามิก คิวรี : SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>คอลัมน์ Partition : ระบุคอลัมน์ที่ใช้ในการแบ่งพาร์ติชันข้อมูล Partition สูงสุดและ พาร์ติชันที่ผูกไว้ต่ํากว่า (ไม่บังคับ): ระบุถ้าคุณต้องการกําหนดการใช้งานพาร์ติชัน ซึ่งไม่ใช่สําหรับการกรองแถวในตาราง แถวทั้งหมดในผลลัพธ์คิวรีจะถูกแบ่งพาร์ติชันและคัดลอก ถ้าไม่ได้ระบุ คัดลอกกิจกรรมจะตรวจหาค่าโดยอัตโนมัติ ตัวอย่างเช่น ถ้าคอลัมน์พาร์ติชัน "ID" ของคุณมีค่าตั้งแต่ 1 ถึง 100 และคุณตั้งค่าขีดจํากัดล่างเป็น 20 และขีดจํากัดบนเป็น 80 พร้อมกับการคัดลอกแบบขนานเป็น 4 บริการจะดึงข้อมูลตามพาร์ติชัน 4 พาร์ติชัน- ID ในช่วง <=20, [21, 50], [51, 80], และ >=81 ตามลําดับ ต่อไปนี้คือตัวอย่างคิวรีเพิ่มเติมสําหรับสถานการณ์ที่แตกต่างกัน: • คิวรีทั้งตาราง: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• คิวรีจากตารางที่มีการเลือกคอลัมน์และตัวกรองส่วนคําสั่งที่เพิ่มเติม: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>•คิวรีพร้อมคิวรีย่อย: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• คิวรีพร้อมพาร์ติชันในคิวรี่ย่อย: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
แนวทางปฏิบัติที่ดีที่สุดในการโหลดข้อมูลด้วยตัวเลือกพาร์ติชัน:
- เลือกคอลัมน์ที่โดดเด่นเป็นคอลัมน์พาร์ติชัน (เช่นคีย์หลักหรือคีย์ที่ไม่ซ้ํากัน) เพื่อหลีกเลี่ยงการบิดเบือนข้อมูล
- ถ้าตารางมีพาร์ติชันที่มีอยู่ภายใน ให้ใช้ตัวเลือกพาร์ติชัน พาร์ติชันจริงของ ตารางเพื่อให้ได้ประสิทธิภาพการทํางานที่ดีขึ้น
คิวรีตัวอย่างเพื่อตรวจสอบพาร์ติชันจริง
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
ถ้าตารางมีพาร์ติชันจริง คุณจะเห็น "HasPartition" เป็น "yes" ดังต่อไปนี้

ข้อมูลสรุปของตาราง
ตารางต่อไปนี้ประกอบด้วยข้อมูลเพิ่มเติมเกี่ยวกับกิจกรรมการคัดลอกในฐานข้อมูล SQL
ที่มา
| ชื่อ | คำอธิบาย | ค่า | ต้องระบุ | คุณสมบัติสคริปต์ JSON |
|---|---|---|---|---|
| การเชื่อมต่อ |
การเชื่อมต่อของคุณไปยังที่เก็บข้อมูลต้นทาง | < > การเชื่อมต่อของคุณ | ใช่ | การเชื่อมต่อ |
| ใช้ คิวรี | วิธีการอ่านข้อมูล ใช้ ตาราง |
• ตาราง • คิวรี • Stored Procedure |
ใช่ | / |
| ชื่อแผนการ |
ชื่อของเค้าร่าง | < > ชื่อ Schema ของคุณ | ไม่ใช่ | schema |
| ชื่อตาราง |
ชื่อของตาราง | < ชื่อตารางของคุณ > | ไม่ใช่ | โต๊ะ |
| คิวรี |
ระบุคิวรี SQL แบบกําหนดเองเพื่ออ่านข้อมูล ตัวอย่างเช่น: SELECT * FROM MyTable |
< > คิวรี SQL | ไม่ใช่ | sqlReaderQuery |
| ชื่อ Stored Procedure | ชื่อของกระบวนงานที่เก็บไว้ | < ชื่อกระบวนงานที่เก็บไว้ของคุณ > | ไม่ใช่ | sqlReaderStoredProcedureName |
| หมดเวลาคิวรี (นาที) | การหมดเวลาสําหรับการดําเนินการคําสั่งคิวรี ค่าเริ่มต้นคือ 120 นาที ถ้าพารามิเตอร์ถูกตั้งค่าสําหรับคุณสมบัตินี้ ค่าที่อนุญาตคือ timespan เช่น "02:00:00" (120 นาที) | timespan | ไม่ใช่ | queryTimeout |
| ระดับการแยก |
ระบุลักษณะการทํางานของการล็อคธุรกรรมสําหรับแหล่งข้อมูล SQL | • ยอมรับการอ่าน •อ่านไม่ได้ผูกมัด •ทําซ้ําอ่าน • Serializable •ภาพถ่าย |
ไม่ใช่ | isolationLevel: • ReadCommitted • ReadUncommitted •ทําซ้ําได้อ่าน • Serializable •ภาพถ่าย |
| ตัวเลือกพาร์ติชัน |
ตัวเลือกการแบ่งพาร์ติชันข้อมูลที่ใช้ในการโหลดข้อมูลจากฐานข้อมูล SQL | •ไม่มีใคร • พาร์ติชันจริงของตาราง •ช่วงไดนามิก |
ไม่ใช่ | partitionOption: • PhysicalPartitionsOfTable • DynamicRange |
| ชื่อคอลัมน์พาร์ติชัน |
ชื่อของคอลัมน์ต้นทางในจํานวนเต็ม หรือชนิด วันที่/วันที่เวลา (int, smallint, bigint, date, smalldatetime, datetimedatetime2หรือ datetimeoffset) ที่ใช้โดยการกําหนดพาร์ติชันในช่วงสําหรับสําเนาคู่ขนาน ถ้าไม่ได้ระบุ ดัชนีหรือคีย์หลักของตารางจะถูกตรวจสอบโดยอัตโนมัติ และใช้เป็นคอลัมน์พาร์ติชัน ถ้าคุณใช้คิวรีเพื่อดึงข้อมูลต้นทาง ?DfDynamicRangePartitionCondition hook ในส่วนคําสั่ง WHERE |
< ชื่อคอลัมน์พาร์ติชันของคุณ > | ไม่ใช่ | partitionColumnName |
| ขอบเขตบนของพาร์ติชัน | ค่าสูงสุดของคอลัมน์พาร์ติชันสําหรับการแยกช่วงพาร์ติชัน ค่านี้ใช้เพื่อตัดสินใจว่าจะดําเนินการแบ่งพาร์ติชัน ไม่ใช่สําหรับการกรองแถวในตาราง แถวทั้งหมดในตารางหรือผลลัพธ์คิวรีจะถูกแบ่งพาร์ติชันและคัดลอก ถ้าไม่ได้ระบุ คัดลอกกิจกรรมจะตรวจหาค่าโดยอัตโนมัติ | < > ขอบเขตบนของพาร์ติชันของคุณ | ไม่ใช่ | partitionUpperBound |
| ผูกพาร์ติชันที่ต่ํากว่า | ค่าต่ําสุดของคอลัมน์พาร์ติชันสําหรับการแยกช่วงพาร์ติชัน ค่านี้ใช้เพื่อตัดสินใจว่าจะดําเนินการแบ่งพาร์ติชัน ไม่ใช่สําหรับการกรองแถวในตาราง แถวทั้งหมดในตารางหรือผลลัพธ์คิวรีจะถูกแบ่งพาร์ติชันและคัดลอก ถ้าไม่ได้ระบุ คัดลอกกิจกรรมจะตรวจหาค่าโดยอัตโนมัติ | < > ที่ผูกไว้ต่ํากว่าพาร์ติชันของคุณ | ไม่ใช่ | partitionLowerBound |
| คอลัมน์เพิ่มเติม | เพิ่มคอลัมน์ข้อมูลเพิ่มเติมเพื่อจัดเก็บเส้นทางสัมพัทธ์หรือค่าคงที่ของไฟล์ต้นฉบับ นิพจน์ได้รับการสนับสนุนสําหรับอย่างหลัง | •ชื่อ •ค่า |
ไม่ใช่ | additionalColumns: •ชื่อ •ค่า |
จุดหมาย
| ชื่อ | คำอธิบาย | ค่า | ต้องระบุ | คุณสมบัติสคริปต์ JSON |
|---|---|---|---|---|
| การเชื่อมต่อ |
การเชื่อมต่อของคุณไปยังที่เก็บข้อมูลปลายทาง | < > การเชื่อมต่อของคุณ | ใช่ | การเชื่อมต่อ |
| ตัวเลือกตาราง |
ตารางข้อมูลปลายทางของคุณ เลือกจาก ใช้ ที่มีอยู่ หรือ ตารางสร้างอัตโนมัติ | • ใช้ที่มีอยู่ • สร้างตารางอัตโนมัติ |
ใช่ | schema โต๊ะ |
| ลักษณะการทํางานของการเขียน |
กําหนดลักษณะการทํางานของการเขียนเมื่อแหล่งข้อมูลคือไฟล์จากที่เก็บข้อมูลตามไฟล์ | •สอด •Upsert •ขั้นตอนการจัดเก็บ |
ไม่ใช่ | writeBehavior: •สอด •upsert • sqlWriterStoredProcedureName |
| ล็อคการแทรกตารางจํานวนมาก |
ใช้การตั้งค่านี้เพื่อปรับปรุงประสิทธิภาพการคัดลอกในระหว่างการดําเนินการแทรกจํานวนมากในตารางที่ไม่มีดัชนีจากหลายไคลเอ็นต์ | ใช่หรือไม่ (ค่าเริ่มต้น) | ไม่ใช่ | sqlWriterUseTableLock: จริง หรือ เท็จ (ค่าเริ่มต้น) |
| ใช้ TempDB | ไม่ว่าจะใช้ตารางชั่วคราวสากลหรือตารางทางกายภาพเป็นตารางชั่วคราวสําหรับ upsert | เลือกแล้ว (ค่าเริ่มต้น) หรือยกเลิกการเลือก | ไม่ใช่ | useTempDB: จริง (ค่าเริ่มต้น) หรือ เท็จ |
| คอลัมน์คีย์ |
เลือกคอลัมน์ที่จะใช้เพื่อกําหนดว่าแถวจากต้นทางตรงกับแถวจากปลายทางหรือไม่ | < > คอลัมน์คีย์ของคุณ | ไม่ใช่ | คีย์ |
| ชื่อ Stored Procedure | คุณสมบัตินี้คือชื่อของกระบวนงานที่เก็บไว้ที่อ่านข้อมูลจากตารางต้นทาง คําสั่ง SQL สุดท้ายต้องเป็นคําสั่ง SELECT ใน Stored Procedure | > ชื่อกระบวนงานที่เก็บไว้ < | ไม่ใช่ | sqlWriterStoredProcedureName |
| สคริปต์ก่อนคัดลอก |
สคริปต์สําหรับคัดลอกกิจกรรมเพื่อดําเนินการก่อนเขียนข้อมูลลงในตารางปลายทางในการเรียกใช้แต่ละครั้ง คุณสามารถใช้คุณสมบัตินี้ในการล้างข้อมูลที่โหลดไว้ล่วงหน้า |
> สคริปต์ก่อนคัดลอก < (สตริง) |
ไม่ใช่ | preCopyScript |
| เขียน หมดเวลาของชุดงาน | เวลารอสําหรับชุดงานที่แทรกการดําเนินงานเพื่อเสร็จสิ้นก่อนที่จะหมดเวลา ค่าที่อนุญาตคือช่วงเวลา ค่าเริ่มต้นคือ "00:30:00" (30 นาที) | timespan | ไม่ใช่ | writeBatchTimeout |
| เขียน ขนาดของชุดงาน | จํานวนแถวที่จะแทรกลงในตาราง SQL ต่อชุดงาน ตามค่าเริ่มต้น บริการจะกําหนดขนาดของชุดงานที่เหมาะสมแบบไดนามิกตามขนาดของแถว | จํานวนแถว <> (จํานวนเต็ม) |
ไม่ใช่ | writeBatchSize |
| การเชื่อมต่อพร้อมกันสูงสุด |
ขีดจํากัดสูงสุดของการเชื่อมต่อพร้อมกันที่สร้างขึ้นกับที่เก็บข้อมูลในระหว่างการเรียกใช้กิจกรรม ระบุค่าเมื่อคุณต้องการจํากัดการเชื่อมต่อที่เกิดขึ้นพร้อมกันเท่านั้น |
<ขีดจํากัดสูงสุดของ> การเชื่อมต่อพร้อมกัน (จํานวนเต็ม) |
ไม่ใช่ | maxConcurrentConnections |
เนื้อหาที่เกี่ยวข้อง
- ภาพรวมของฐานข้อมูล SQL