วิธีการสร้างพูล Spark แบบกําหนดเองใน Microsoft Fabric
ในเอกสารนี้ เราจะอธิบายวิธีการสร้างพูล Apache Spark แบบกําหนดเองใน Microsoft Fabric สําหรับปริมาณงานการวิเคราะห์ของคุณ กลุ่ม Apache Spark ช่วยให้ผู้ใช้สามารถสร้างสภาพแวดล้อมการคํานวณที่ปรับแต่งตามความต้องการเฉพาะของพวกเขา เพื่อให้มั่นใจถึงประสิทธิภาพสูงสุดและการใช้งานทรัพยากร
คุณระบุโหนดต่ําสุดและสูงสุดสําหรับการปรับขนาดอัตโนมัติ ระบบได้รับและถอนโหนดแบบไดนามิกเมื่อข้อกําหนดการคํานวณของงานเปลี่ยนแปลง ซึ่งส่งผลให้มีการปรับขนาดและประสิทธิภาพการทํางานที่มีประสิทธิภาพ การจัดสรรแบบไดนามิกของผู้ปฏิบัติการในพูล Spark ยังช่วยบรรเทาความจําเป็นสําหรับการกําหนดค่าเครื่องปฏิบัติการด้วยตนเองได้อีกด้วย แต่ระบบจะปรับจํานวนของตัวดําเนินการทั้งนี้ขึ้นอยู่กับปริมาณข้อมูลและความต้องการคํานวณระดับงาน กระบวนการนี้ช่วยให้คุณสามารถมุ่งเน้นไปที่ปริมาณงานของคุณโดยไม่ต้องกังวลเกี่ยวกับการปรับประสิทธิภาพให้เหมาะสมและการจัดการทรัพยากร
โน้ต
หากต้องการสร้างพูล Spark แบบกําหนดเอง คุณต้องมีสิทธิการเข้าถึงของผู้ดูแลระบบในพื้นที่ทํางาน ผู้ดูแลระบบความจุต้องเปิดใช้งานตัวเลือก
สร้างพูล Spark แบบกําหนดเอง
เมื่อต้องสร้างหรือจัดการพูล Spark ที่เชื่อมโยงกับพื้นที่ทํางานของคุณ:
ไปยังพื้นที่ทํางานของคุณและเลือก การตั้งค่าพื้นที่ทํางาน
เลือกตัวเลือก วิศวกรรมข้อมูล/วิทยาศาสตร์
เพื่อขยายเมนู จากนั้นเลือก การตั้งค่า Spark 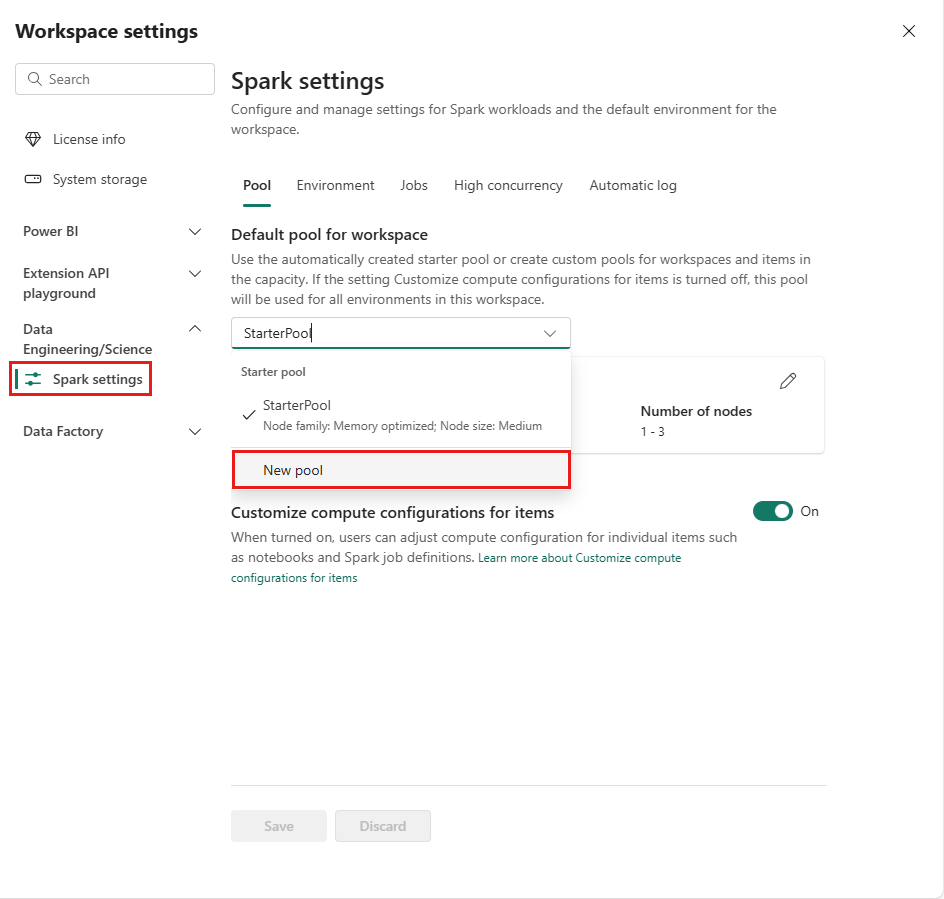
เลือกตัวเลือก
กลุ่มใหม่ ในหน้าจอ สร้างพูล ตั้งชื่อพูล Spark ของคุณ นอกจากนี้ยังเลือก โหนดแล้วเลือกขนาดโหนด จากขนาดที่มี ( ขนาดเล็ก ปานกลาง ขนาดใหญ่ X-Large และXX Large ) ตามความต้องการในการคํานวณปริมาณงานของคุณ 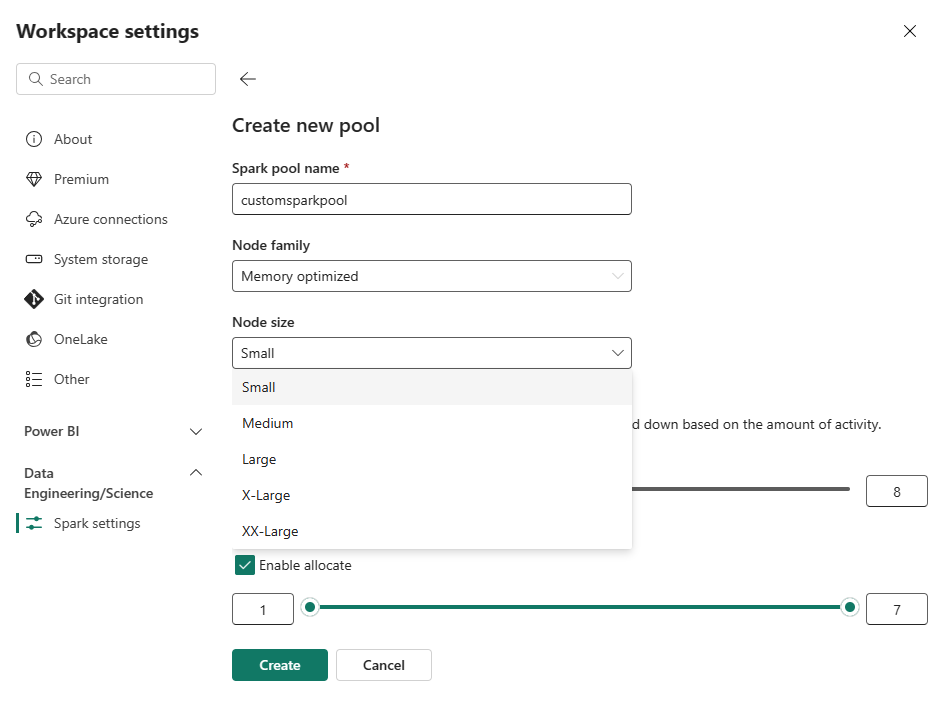
คุณสามารถตั้งค่าการกําหนดค่าโหนดต่ําสุดสําหรับกลุ่มข้อมูลของคุณเป็น 1 เนื่องจาก Fabric Spark มีความพร้อมใช้งานที่คืนค่าได้สําหรับคลัสเตอร์ที่มีโหนดเดียว คุณจึงไม่ต้องกังวลเกี่ยวกับความล้มเหลวของงาน การสูญเสียเซสชันระหว่างความล้มเหลว หรือการชําระเงินในการคํานวณสําหรับงาน Spark ที่มีขนาดเล็กกว่า
คุณสามารถเปิดใช้งานหรือปิดใช้งานการปรับขนาดอัตโนมัติสําหรับพูล Spark แบบกําหนดเองของคุณได้ เมื่อเปิดใช้งานการปรับขนาดอัตโนมัติ กลุ่มจะได้รับโหนดใหม่แบบไดนามิกจนถึงขีดจํากัดสูงสุดของโหนดที่ระบุโดยผู้ใช้ และจากนั้นเกษียณหลังจากการดําเนินการงาน คุณลักษณะนี้ช่วยให้แน่ใจว่ามีประสิทธิภาพการทํางานที่ดีขึ้นโดยการปรับทรัพยากรตามความต้องการของงาน คุณสามารถปรับขนาดโหนดได้ ซึ่งพอดีกับหน่วยความจุที่ซื้อเป็นส่วนหนึ่งของ SKU ความจุของ Fabric
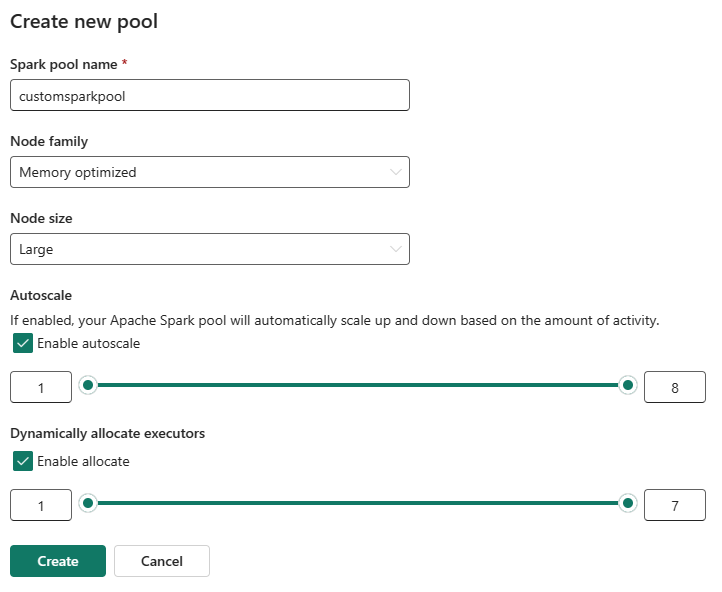
คุณยังสามารถเลือกเปิดใช้งานการจัดสรรผู้ปฏิบัติการแบบไดนามิกสําหรับพูล Spark ของคุณ ซึ่งจะกําหนดจํานวนเครื่องปฏิบัติการที่เหมาะสมที่สุดภายในขอบเขตสูงสุดที่ผู้ใช้ระบุโดยอัตโนมัติ คุณลักษณะนี้ปรับจํานวนของตัวดําเนินการที่ยึดตามปริมาณข้อมูล ส่งผลให้ประสิทธิภาพการทํางานและการใช้ทรัพยากรดียิ่งขึ้น

กลุ่มแบบกําหนดเองเหล่านี้มีระยะเวลาการจ่ายเงินอัตโนมัติตามค่าเริ่มต้น 2 นาที เมื่อถึงระยะเวลาการเผยแพร่อัตโนมัติ เซสชันจะหมดอายุ และคลัสเตอร์จะไม่ได้จัดสรร คุณจะถูกเรียกเก็บเงินตามจํานวนโหนดและระยะเวลาที่ใช้กลุ่ม Spark แบบกําหนดเอง
เนื้อหาที่เกี่ยวข้อง
- เรียนรู้เพิ่มเติมจาก Apache Spark เอกสารสาธารณะ
- เริ่มต้นใช้งานการตั้งค่าการดูแลระบบพื้นที่ทํางาน Spark ใน Microsoft Fabric