รายงานการเรียกเก็บเงินและการใช้งานสําหรับ Apache Spark ใน Microsoft Fabric
นําไปใช้กับ:✅ วิศวกรข้อมูลและวิทยาศาสตร์ข้อมูลใน Microsoft Fabric
บทความนี้อธิบายการใช้ประโยชน์การคํานวณและการรายงานสําหรับ ApacheSpark ซึ่งให้พลังปริมาณงาน Fabric วิศวกรข้อมูล และวิทยาศาสตร์ใน Microsoft Fabric การใช้งานการคํานวณรวมถึงการดําเนินการของเลคเฮ้าส์ เช่น การแสดงตัวอย่างตาราง การโหลดไปยังเดลต้า สมุดบันทึกทํางานจากอินเทอร์เฟซ การเรียกใช้ตามกําหนดเวลา การเรียกใช้ที่ถูกทริกเกอร์โดยขั้นตอนสมุดบันทึกในไปป์ไลน์ และการเรียกใช้ข้อกําหนดงาน Apache Spark
เช่นเดียวกับประสบการณ์อื่น ๆ ใน Microsoft Fabric วิศวกรข้อมูลยังใช้ความจุที่เชื่อมโยงกับพื้นที่ทํางานเพื่อเรียกใช้งานเหล่านี้และค่าใช้จ่ายความจุโดยรวมของคุณจะปรากฏในพอร์ทัล Azure ภายใต้การสมัครใช้งาน Microsoft Cost Management ของคุณ หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ Fabric Billing โปรดดู ทําความเข้าใจเกี่ยวกับการเรียกเก็บเงิน Azure ของคุณบนความจุ Fabric
ความจุผ้า
คุณสามารถซื้อความจุ Fabric จาก Azure โดยการระบุโดยใช้การสมัครใช้งาน Azure ขนาดของความจุจะกําหนดจํานวนกําลังการประมวลผลที่พร้อมใช้งาน สําหรับ Apache Spark สําหรับ Fabric ทุก CU ที่ซื้อจะแปลเป็น Apache Spark VCores 2 ตัวอย่างเช่น ถ้าคุณซื้อความจุ Fabric F128 สิ่งนี้แปลเป็น 256 SparkVCores ความจุ Fabric จะถูกแชร์ทั่วทั้งพื้นที่ทํางานที่เพิ่มเข้ามา และที่การคํานวณ Apache Spark ทั้งหมดได้รับอนุญาตให้ใช้ร่วมกันในทุกงานที่ส่งมาจากพื้นที่ทํางานทั้งหมดที่เชื่อมโยงกับความจุ หากต้องการทําความเข้าใจเกี่ยวกับ SKU ที่แตกต่างกัน การจัดสรรแกนและการควบคุมปริมาณบน Spark โปรดดู ขีดจํากัดภาวะพร้อมกันและการจัดคิวใน Apache Spark สําหรับ Microsoft Fabric
การกําหนดค่าการคํานวณ Spark และความจุที่ซื้อ
Apache Spark compute สําหรับ Fabric มีตัวเลือกสองตัวเลือกในการคํานวณการกําหนดค่า
กลุ่มเริ่มต้น: กลุ่มค่าเริ่มต้นเหล่านี้เป็นวิธีที่ง่ายและรวดเร็วในการใช้ Spark บนแพลตฟอร์ม Microsoft Fabric ภายในไม่กี่วินาที คุณสามารถใช้เซสชัน Spark ได้ทันที แทนที่จะรอให้ Spark ตั้งค่าโหนดให้คุณ ซึ่งช่วยให้คุณทําสิ่งต่างๆ ได้มากขึ้นด้วยข้อมูลและรับข้อมูลเชิงลึกได้รวดเร็วยิ่งขึ้น เมื่อถึงเวลาสําหรับการเรียกเก็บเงินและปริมาณการใช้ความจุ คุณจะถูกเรียกเก็บเงินเมื่อคุณเริ่มดําเนินการโน้ตบุ๊คหรือข้อกําหนดงาน Spark หรือการทํางานของ lakehouse คุณจะไม่ถูกเรียกเก็บเงินสําหรับเวลาที่คลัสเตอร์ไม่ได้ใช้งานในพูล
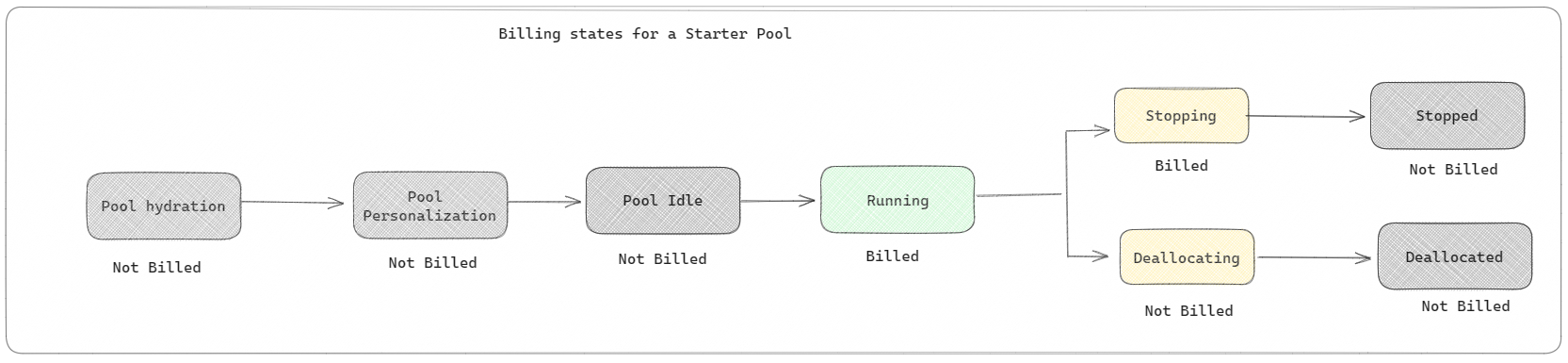
ตัวอย่างเช่น ถ้าคุณส่งงานสมุดบันทึกไปยังพูลตัวเริ่มต้น คุณจะถูกเรียกเก็บเงินเฉพาะช่วงเวลาที่เซสชันของสมุดบันทึกทํางานอยู่ เวลาที่เรียกเก็บเงินไม่รวมเวลาที่ไม่ได้ใช้งานหรือเวลาที่ใช้ในการปรับแต่งเซสชันด้วยบริบท Spark เพื่อทําความเข้าใจเพิ่มเติมเกี่ยวกับการกําหนดค่าพูล Starter ที่ยึดตาม Fabric Capacity SKU ที่ซื้อ ไปที่ การกําหนดค่ากลุ่ม Starter โดยยึดตามความจุ Fabric
Spark pools: ต่อไปนี้คือกลุ่มแบบกําหนดเอง ที่ซึ่งคุณสามารถปรับแต่งขนาดของทรัพยากรที่คุณต้องการสําหรับงานการวิเคราะห์ข้อมูลของคุณ คุณสามารถตั้งชื่อกลุ่ม Spark ของคุณ และเลือกจํานวนและขนาดโหนด (เครื่องที่ทํางาน) ได้ คุณยังสามารถบอก Spark ถึงวิธีปรับจํานวนโหนดโดยขึ้นอยู่กับว่าคุณมีการทํางานมากน้อยเพียงใด การสร้างสระว่ายน้ํา Spark นั้นฟรี คุณจ่ายเมื่อคุณเรียกใช้งาน Spark บนพูลเท่านั้น จากนั้น Spark จะตั้งค่าโหนดให้คุณ
- ขนาดและจํานวนของโหนดที่คุณสามารถมีในพูล Spark แบบกําหนดเองของคุณขึ้นอยู่กับความจุ Microsoft Fabric ของคุณ คุณสามารถใช้ Spark VCores เหล่านี้เพื่อสร้างโหนดที่มีขนาดแตกต่างกันสําหรับพูล Spark แบบกําหนดเองของคุณ ตราบใดที่จํานวนรวมของ Spark VCores ไม่เกิน 128
- สระว่ายน้ํา Spark มีการเรียกเก็บเงินเช่นสระว่ายน้ําเริ่มต้น คุณไม่จ่ายสําหรับพูล Spark แบบกําหนดเองที่คุณสร้างขึ้น เว้นแต่ว่าคุณมีเซสชัน Spark ที่ใช้งานอยู่ ที่สร้างขึ้นสําหรับการเรียกใช้งานสมุดบันทึกหรือข้อกําหนดงาน Spark คุณจะถูกเรียกเก็บเงินสําหรับระยะเวลาการเรียกใช้งานของคุณเท่านั้น คุณจะไม่ถูกเรียกเก็บเงินสําหรับขั้นตอนต่าง ๆ เช่น การสร้างคลัสเตอร์และการจัดสรรหลังจากงานเสร็จสมบูรณ์
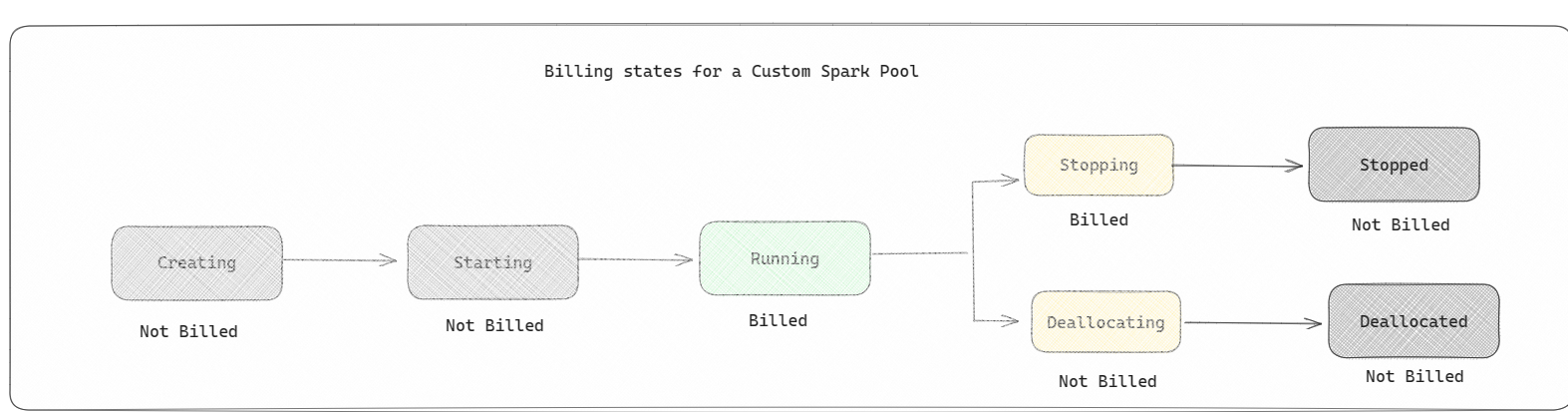
ตัวอย่างเช่น ถ้าคุณส่งงานสมุดบันทึกไปยังพูล Spark แบบกําหนดเอง คุณจะถูกเรียกเก็บเงินสําหรับระยะเวลาเมื่อเซสชันทํางานเท่านั้น การเรียกเก็บเงินสําหรับเซสชันสมุดบันทึกนั้นจะหยุดลงเมื่อเซสชัน Spark หยุดหรือหมดอายุ คุณจะไม่ถูกเรียกเก็บเงินสําหรับเวลาที่ใช้ในการรับอินสแตนซ์คลัสเตอร์จากระบบคลาวด์หรือสําหรับเวลาที่ใช้ในการเตรียมใช้งานบริบท Spark เพื่อทําความเข้าใจเพิ่มเติมเกี่ยวกับการกําหนดค่าพูล Spark ที่ยึดตาม Fabric Capacity SKU ที่ซื้อ ไปที่ การกําหนดค่าพูลที่ยึดตามความจุ Fabric


หมายเหตุ
ระยะเวลาหมดอายุของเซสชันเริ่มต้นสําหรับกลุ่ม Starter และ Spark Pools ที่คุณสร้างจะถูกตั้งค่าเป็น 20 นาที ถ้าคุณไม่ได้ใช้พูล Spark ของคุณเป็นเวลา 2 นาทีหลังจากเซสชันของคุณหมดอายุ พูล Spark ของคุณจะถูกจัดสรร เมื่อต้องการหยุดเซสชันและการเรียกเก็บเงินหลังจากเสร็จสิ้นการดําเนินการสมุดบันทึกของคุณก่อนช่วงเวลาหมดอายุของเซสชัน คุณสามารถคลิกปุ่มหยุดเซสชันจากเมนูหน้าแรกของสมุดบันทึกหรือไปที่หน้าฮับการตรวจสอบและหยุดเซสชันได้
การรายงานการใช้งานของ Spark compute
แอปเมตริกความจุของ Microsoft Fabric ช่วยให้สามารถมองเห็นการใช้งานความจุสําหรับปริมาณงาน Fabric ทั้งหมดในที่เดียว ผู้ดูแลระบบความจุใช้เพื่อตรวจสอบประสิทธิภาพของปริมาณงานและการใช้งานเมื่อเปรียบเทียบกับความจุที่ซื้อ
เมื่อคุณติดตั้งแอปแล้ว ให้เลือกประเภทรายการ สมุดบันทึก,เลคเฮ้าส์,ข้อกําหนดงานของ Spark จากรายการดรอปดาวน์ เลือกรายการ: ใน ตอนนี้คุณสามารถปรับเปลี่ยนแผนภูมิ ริบบอนเมตริกหลายรายการเป็นกรอบเวลาที่ต้องการเพื่อทําความเข้าใจการใช้งานจากหน่วยข้อมูลที่เลือกทั้งหมดเหล่านี้
การดําเนินการที่เกี่ยวข้องกับ Spark ทั้งหมดจะถูกจัดประเภทเป็น การทํางานแบบเบื้องหลัง การใช้ความจุจาก Spark จะแสดงภายใต้สมุดบันทึก ข้อกําหนดงาน Spark หรือเลคเฮ้าส์ และรวมด้วยชื่อการดําเนินการและรายการ ตัวอย่างเช่น: ถ้าคุณเรียกใช้งานสมุดบันทึก คุณสามารถดูการเรียกใช้สมุดบันทึก CUs ที่ใช้โดยสมุดบันทึก (Total Spark VCores/2 เป็น 1 CU ให้ 2 Spark VCores) ระยะเวลาของงานในรายงาน
 เมื่อต้องการทําความเข้าใจเพิ่มเติมเกี่ยวกับการรายงานการใช้งานความจุ Spark ดู ตรวจสอบปริมาณการใช้ความจุ Apache Spark
เมื่อต้องการทําความเข้าใจเพิ่มเติมเกี่ยวกับการรายงานการใช้งานความจุ Spark ดู ตรวจสอบปริมาณการใช้ความจุ Apache Spark
ตัวอย่างการเรียกเก็บเงิน
พิจารณาสถานการณ์ต่อไปนี้
มีความจุ C1 ที่โฮสต์ Fabric Workspace W1 และพื้นที่ทํางานนี้มี Lakehouse LH1 และ Notebook NB1
- การทํางานของ Spark ใดๆ ที่สมุดบันทึก (NB1) หรือ lakehouse(LH1) ดําเนินการจะมีรายงานเทียบกับความจุ C1
ขยายตัวอย่างนี้ไปยังสถานการณ์ที่มีความจุ C2 อื่นซึ่งโฮสต์ Fabric Workspace W2 และสมมติว่าพื้นที่ทํางานนี้มีข้อกําหนดงาน Spark (SJD1) และ Lakehouse (LH2)
- ถ้าข้อกําหนดงาน Spark (SDJ2) จากพื้นที่ทํางาน (W2) อ่านข้อมูลจาก lakehouse (LH1) การใช้งานจะถูกรายงานเทียบกับความจุ C2 ที่เกี่ยวข้องกับพื้นที่ทํางาน (W2) ที่โฮสต์รายการ
- ถ้าสมุดบันทึก (NB1) ดําเนินการอ่านจาก Lakehouse(LH2) การใช้ความจุจะถูกรายงานเทียบกับความจุ C1 ซึ่งจะขับเคลื่อนพื้นที่ทํางาน W1 ที่โฮสต์รายการสมุดบันทึก