What is Apache Spark™ in HDInsight on AKS? (Preview)
Note
We will retire Azure HDInsight on AKS on January 31, 2025. Before January 31, 2025, you will need to migrate your workloads to Microsoft Fabric or an equivalent Azure product to avoid abrupt termination of your workloads. The remaining clusters on your subscription will be stopped and removed from the host.
Only basic support will be available until the retirement date.
Important
This feature is currently in preview. The Supplemental Terms of Use for Microsoft Azure Previews include more legal terms that apply to Azure features that are in beta, in preview, or otherwise not yet released into general availability. For information about this specific preview, see Azure HDInsight on AKS preview information. For questions or feature suggestions, please submit a request on AskHDInsight with the details and follow us for more updates on Azure HDInsight Community.
Apache Spark™ is a parallel processing framework that supports in-memory processing to boost the performance of big-data analytic applications.
Apache Spark™ provides primitives for in-memory cluster computing. A Spark job can load and cache data into memory and query it repeatedly. In-memory computing is faster than disk-based applications, such as Hadoop, which shares data through Hadoop distributed file system (HDFS). Apache Spark allows integration with the Scala and Python programming languages to let you manipulate distributed data sets like local collections. There's no need to structure everything as map and reduce operations.
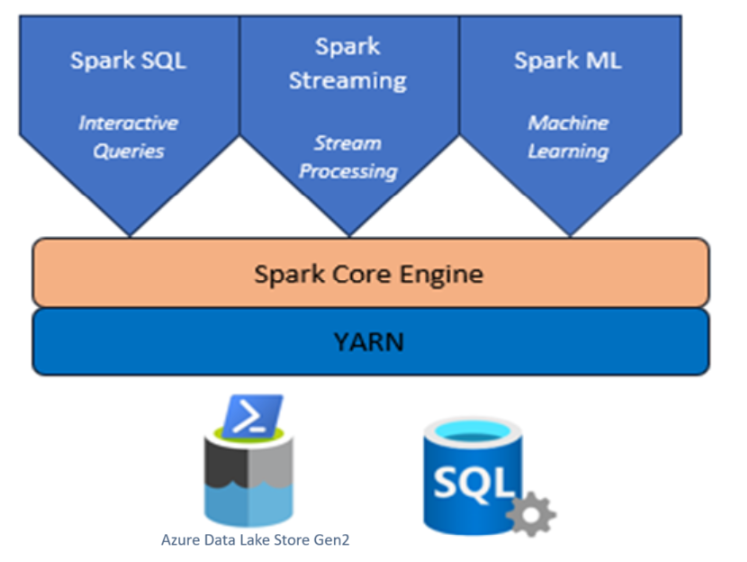
Apache Spark cluster with HDInsight on AKS
Azure HDInsight is a managed, full-spectrum, open-source analytics service for enterprises.
Apache Spark™ in Azure HDInsight on AKS is the managed spark service in Microsoft Azure. With Apache Spark in Azure HDInsight on AKS, you can store and process your data all within Azure. Spark clusters in HDInsight are compatible with or Azure Data Lake Storage Gen2, allows you to apply Spark processing on your existing data stores.
The Apache Spark framework for HDInsight on AKS enables fast data analytics and cluster computing using in-memory processing. Jupyter Notebook lets you interact with your data, combine code with markdown text, and do simple visualizations.
Apache Spark on AKS in HDInsight composed of multiple components as pods.
Cluster Controllers
Cluster controllers are responsible for installing and managing respective service. Various controllers are installed and managed in a Spark cluster.
Apache Spark service components
Zookeeper service: A three node Zookeeper cluster, serves as distributed coordinator or High Availability storage for other services.
Yarn service: Hadoop Yarn cluster, Spark jobs would be scheduled in the cluster as Yarn applications.
Client Interfaces: Apache Spark clusters in HDInsight on AKS, provides various client interfaces. Livy Server, Jupyter Notebook, Spark History Server, provides Spark services to HDInsight on AKS users.
Reference
- Apache, Apache Spark, Spark, and associated open source project names are trademarks of the Apache Software Foundation (ASF).