Reliability in Azure Communications Gateway
Azure Communications Gateway ensures your service is reliable by using Azure redundancy mechanisms and SIP-specific retry behavior. Your network must meet specific requirements to ensure service availability.
Azure Communications Gateway's redundancy model
Production Azure Communications Gateway deployments (also called standard deployments) consist of three separate regions: a management region and two service regions. Lab deployments consist of one management region and one service region.
This article describes the two different region types and their distinct redundancy models. It covers both regional reliability with availability zones and cross-region reliability with disaster recovery. For a more detailed overview of reliability in Azure, see Azure reliability.
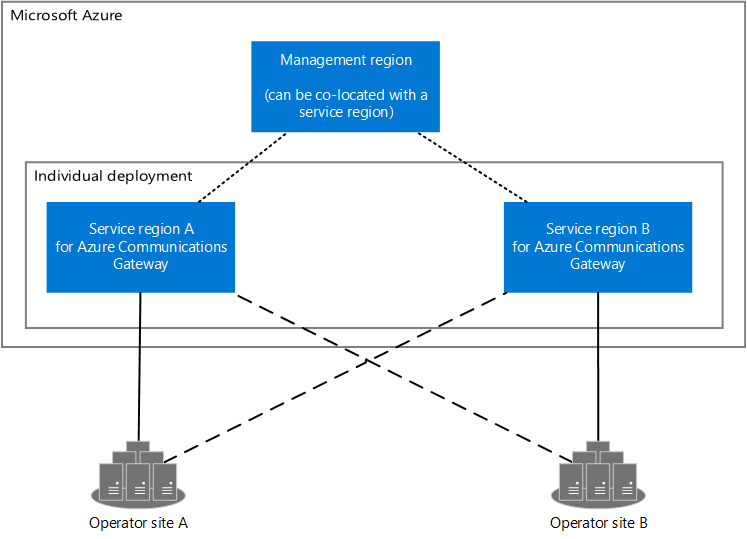
Diagram showing two operator sites and the Azure regions for Azure Communications Gateway. Azure Communications Gateway has two service regions and one management region. The service regions connect to the management region and to the operator sites. The management region can be colocated with a service region.
Service regions
Service regions contain the voice and API infrastructure used for handling traffic between your network and your chosen communications services.
Production Azure Communications Gateway deployments have two service regions that are deployed in an active-active mode (as required by the Operator Connect and Teams Phone Mobile programs). Fast failover between the service regions is provided at the infrastructure/IP level and at the application (SIP/RTP/HTTP) level.
The service regions also contain the infrastructure for Azure Communications Gateway's Provisioning API.
Tip
Production deployments must always have two service regions, even if one of the service regions chosen is in a single-region Azure Geography (for example, Qatar). If you choose a single-region Azure Geography, choose a second Azure region in a different Azure Geography.
The service regions are identical in operation and provide resiliency to both Zone and Regional failures. Each service region can carry 100% of the traffic using the Azure Communications Gateway instance. As such, end-users should still be able to make and receive calls successfully during any Zone or Regional downtime.
Lab deployments have one service region.
Call routing requirements
Azure Communications Gateway offers a 'successful redial' redundancy model: calls handled by failing peers are terminated, but new calls are routed to healthy peers. This model mirrors the redundancy model provided by Microsoft Teams.
For production deployments, we expect your network to have two geographically redundant sites. Each site should be paired with an Azure Communications Gateway region. The redundancy model relies on cross-connectivity between your network and Azure Communications Gateway service regions.
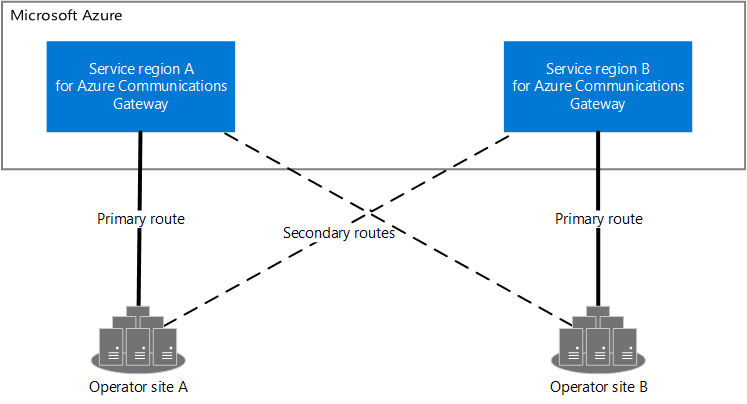
Diagram of two operator sites (operator site A and operator site B) and two service regions (service region A and service region B). Operator site A has a primary route to service region A and a secondary route to service region B. Operator site B has a primary route to service region B and a secondary route to service region A.
Lab deployments must connect to one site in your network.
Each Azure Communications Gateway service region provides an SRV record. This record contains all the SIP peers providing SBC functionality (for routing calls to communications services) within the region. This SRV record can point to any IP address in the /28 IP range provided to you by your onboarding team.
If your Azure Communications Gateway includes Mobile Control Point (MCP), each service region provides an extra SRV record for MCP. Each per-region MCP record contains MCP within the region at top priority and MCP in the other region at a lower priority.
Each site in your network must:
- Send traffic to its local Azure Communications Gateway service region by default.
- Locate Azure Communications Gateway peers within a region using DNS SRV, as outlined in RFC 3263.
- Make a DNS SRV lookup on the domain name for the service region's connection to your network, using
_sip._tls.<regional-FQDN-from-portal>. Replace<regional-FQDN-from-portal>with the per-region FQDNs from the Hostname fields on the Overview page for your resource in the Azure portal. For example, if your deployment usescommsgw.azure.comdomain names, look up_sip._tls.pstn-region1.<deployment-id>.commsgw.azure.comfor the first region. - If the SRV lookup returns multiple targets, use the weight and priority of each target to select a single target.
- Make a DNS SRV lookup on the domain name for the service region's connection to your network, using
- Send new calls to available Azure Communications Gateway peers.
- Be able to receive traffic from any IP address in each of the IP ranges associated with your Azure Communications Gateway.
When your network routes calls to Azure Communications Gateway's SIP peers for SBC function, it must:
- Use SIP OPTIONS (or a combination of OPTIONS and SIP traffic) to monitor the availability of the Azure Communications Gateway SIP peers.
- Retry INVITEs that received 408 responses, 503 responses or 504 responses or did not receive responses, by rerouting them to other available peers in the local site. Hunt to the other service region (defined by the other region's SRV record) only if all peers in the local service region have failed.
- Never retry calls that receive error responses other than 408, 503 and 504.
If your Azure Communications Gateway deployment includes integrated Mobile Control Point (MCP), your network must do as follows for MCP:
- Detect when MCP in a region is unavailable, mark the targets for that region's SRV record as unavailable, and retry periodically to determine when the region is available again. MCP doesn't respond to SIP OPTIONS.
- Handle 5xx responses from MCP according to your organization's policy. For example, you could retry the request, or you could allow the call to continue without passing through Azure Communications Gateway and into Microsoft Phone System.
The details of this routing behavior are specific to your network. You must agree them with your onboarding team during your integration project.
Management regions
Management regions contain the infrastructure used for the ordering, monitoring, and billing of Azure Communications Gateway. All infrastructure within these regions is deployed in a zonally redundant manner, meaning that all data is automatically replicated across each Availability Zone within the region. All critical configuration data is also replicated to each of the Service Regions to ensure the proper functioning of the service during an Azure region failure.
Availability zone support
Azure availability zones are at least three physically separate groups of datacenters within each Azure region. Datacenters within each zone are equipped with independent power, cooling, and networking infrastructure. In the case of a local zone failure, availability zones are designed so that if the one zone is affected, regional services, capacity, and high availability are supported by the remaining two zones.
Failures can range from software and hardware failures to events such as earthquakes, floods, and fires. Tolerance to failures is achieved with redundancy and logical isolation of Azure services. For more detailed information on availability zones in Azure, see Regions and availability zones.
Azure availability zones-enabled services are designed to provide the right level of reliability and flexibility. They can be configured in two ways. They can be either zone redundant, with automatic replication across zones, or zonal, with instances pinned to a specific zone. You can also combine these approaches. For more information on zonal vs. zone-redundant architecture, see Recommendations for using availability zones and regions.
Zone down experience for service regions
During a zone-wide outage, calls handled by the affected zone are terminated, with a brief loss of capacity within the region until the service's self-healing rebalances underlying resources to healthy zones. This self-healing isn't dependent on zone restoration; it's expected that the Microsoft-managed service self-healing state compensates for a lost zone, using capacity from other zones. Traffic carrying resources are deployed in a zone-redundant manner but at the lowest scale traffic might be handled by a single resource. In this case, the failover mechanisms described in this article rebalance all traffic to the other service region while the resources that carry traffic are redeployed in a healthy zone.
Zone down experience for the management region
During a zone-wide outage, no action is required during zone recovery. The management region self-heals and rebalances itself to take advantage of the healthy zone automatically.
Disaster recovery: fallback to other regions
Disaster recovery (DR) is about recovering from high-impact events, such as natural disasters or failed deployments that result in downtime and data loss. Regardless of the cause, the best remedy for a disaster is a well-defined and tested DR plan and an application design that actively supports DR. Before you begin to think about creating your disaster recovery plan, see Recommendations for designing a disaster recovery strategy.
When it comes to DR, Microsoft uses the shared responsibility model. In a shared responsibility model, Microsoft ensures that the baseline infrastructure and platform services are available. At the same time, many Azure services don't automatically replicate data or fall back from a failed region to cross-replicate to another enabled region. For those services, you are responsible for setting up a disaster recovery plan that works for your workload. Most services that run on Azure platform as a service (PaaS) offerings provide features and guidance to support DR and you can use service-specific features to support fast recovery to help develop your DR plan.
This section describes the behavior of Azure Communications Gateway during a region-wide outage.
Disaster recovery: cross-region failover for service regions
During a region-wide outage, the failover mechanisms described in this article (OPTIONS polling and SIP retry on failure) will rebalance all call traffic to the other service region, maintaining availability. We'll start restoring regional redundancy. Restoring regional redundancy during extended downtime might require using other Azure regions. If we need to migrate a failed region to another region, we'll consult you before starting any migrations.
The SBC function in Azure Communications Gateway provides OPTIONS polling to allow your network to determine peer availability. For MCP, your network must be able to detect when MCP is unavailable, and retry periodically to determine when MCP is available again. MCP doesn't respond to SIP OPTIONS.
Provisioning API clients contact Azure Communications Gateway using the base domain name for your deployment. The DNS record for this domain has a time-to-live (TTL) of 60 seconds. When a region fails, Azure updates the DNS record to refer to another region, so clients making a new DNS lookup receive the details of the new region. We recommend ensuring that clients can make a new DNS lookup and retry a request 60 seconds after a timeout or a 5xx response.
Tip
Lab deployments don't offer cross-region failover (because they have only one service region).
Disaster recovery: cross-region failover for management regions
Voice traffic and provisioning through the Number Management Portal are unaffected by failures in the management region, because the corresponding Azure resources are hosted in service regions. Users of the Number Management Portal might need to sign in again.
Monitoring services might be temporarily unavailable until service has been restored. If the management region experiences extended downtime, we'll migrate the impacted resources to another available region.
Choosing management and service regions
A single deployment of Azure Communications Gateway is designed to handle your traffic within a geographic area. Deploy both service regions in a production deployment within the same geographic area (for example North America). This model ensures that latency on voice calls remains within the limits required by the Operator Connect and Teams Phone Mobile programs.
Consider the following points when you choose your service region locations:
- Select from the list of available Azure regions. You can see the Azure regions that can be selected as service regions on the Products by region page.
- Choose regions near to your own premises and the peering locations between your network and Microsoft to reduce call latency.
- Prefer regional pairs to minimize the recovery time if a multi-region outage occurs.
Choose a management region from the following list:
- East US
- West Central US
- West Europe
- UK South
- India Central
- Canada Central
- Australia East
Management regions can be colocated with service regions. We recommend choosing the management region nearest to your service regions.
Note
If you are enabling Azure Operator Call Protection Preview, the service region you select may not be the Azure region where supporting resources are deployed. See Azure Products by Region for the list of currently supported Azure Operator Call Protection service regions and speak to your onboarding team if you have any questions about which region is selected.
Service-level agreements
The reliability design described in this document is implemented by Microsoft and isn't configurable. For more information on the Azure Communications Gateway service-level agreements (SLAs), see the Azure Communications Gateway SLA.