How to generate chat completions with Azure AI model inference
Important
Items marked (preview) in this article are currently in public preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
This article explains how to use chat completions API with models deployed to Azure AI model inference in Azure AI services.
Prerequisites
To use chat completion models in your application, you need:
An Azure subscription. If you're using GitHub Models, you can upgrade your experience and create an Azure subscription in the process. Read Upgrade from GitHub Models to Azure AI model inference if that's your case.
An Azure AI services resource. For more information, see Create an Azure AI Services resource.
The endpoint URL and key.

A chat completions model deployment. If you don't have one read Add and configure models to Azure AI services to add a chat completions model to your resource.
Install the Azure AI inference package for Python with the following command:
pip install -U azure-ai-inference
Use chat completions
First, create the client to consume the model. The following code uses an endpoint URL and key that are stored in environment variables.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="mistral-large-2407"
)
If you have configured the resource to with Microsoft Entra ID support, you can use the following code snippet to create a client.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.identity import DefaultAzureCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="mistral-large-2407"
)
Create a chat completion request
The following example shows how you can create a basic chat completions request to the model.
from azure.ai.inference.models import SystemMessage, UserMessage
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
)
Note
Some models don't support system messages (role="system"). When you use the Azure AI model inference API, system messages are translated to user messages, which is the closest capability available. This translation is offered for convenience, but it's important for you to verify that the model is following the instructions in the system message with the right level of confidence.
The response is as follows, where you can see the model's usage statistics:
print("Response:", response.choices[0].message.content)
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Inspect the usage section in the response to see the number of tokens used for the prompt, the total number of tokens generated, and the number of tokens used for the completion.
Stream content
By default, the completions API returns the entire generated content in a single response. If you're generating long completions, waiting for the response can take many seconds.
You can stream the content to get it as it's being generated. Streaming content allows you to start processing the completion as content becomes available. This mode returns an object that streams back the response as data-only server-sent events. Extract chunks from the delta field, rather than the message field.
To stream completions, set stream=True when you call the model.
result = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
temperature=0,
top_p=1,
max_tokens=2048,
stream=True,
)
To visualize the output, define a helper function to print the stream.
def print_stream(result):
"""
Prints the chat completion with streaming.
"""
import time
for update in result:
if update.choices:
print(update.choices[0].delta.content, end="")
You can visualize how streaming generates content:
print_stream(result)
Explore more parameters supported by the inference client
Explore other parameters that you can specify in the inference client. For a full list of all the supported parameters and their corresponding documentation, see Azure AI Model Inference API reference.
from azure.ai.inference.models import ChatCompletionsResponseFormatText
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
presence_penalty=0.1,
frequency_penalty=0.8,
max_tokens=2048,
stop=["<|endoftext|>"],
temperature=0,
top_p=1,
response_format={ "type": ChatCompletionsResponseFormatText() },
)
Some models don't support JSON output formatting. You can always prompt the model to generate JSON outputs. However, such outputs are not guaranteed to be valid JSON.
If you want to pass a parameter that isn't in the list of supported parameters, you can pass it to the underlying model using extra parameters. See Pass extra parameters to the model.
Create JSON outputs
Some models can create JSON outputs. Set response_format to json_object to enable JSON mode and guarantee that the message the model generates is valid JSON. You must also instruct the model to produce JSON yourself via a system or user message. Also, the message content might be partially cut off if finish_reason="length", which indicates that the generation exceeded max_tokens or that the conversation exceeded the max context length.
from azure.ai.inference.models import ChatCompletionsResponseFormatJSON
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant that always generate responses in JSON format, using."
" the following format: { ""answer"": ""response"" }."),
UserMessage(content="How many languages are in the world?"),
],
response_format={ "type": ChatCompletionsResponseFormatJSON() }
)
Pass extra parameters to the model
The Azure AI Model Inference API allows you to pass extra parameters to the model. The following code example shows how to pass the extra parameter logprobs to the model.
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
model_extras={
"logprobs": True
}
)
Before you pass extra parameters to the Azure AI model inference API, make sure your model supports those extra parameters. When the request is made to the underlying model, the header extra-parameters is passed to the model with the value pass-through. This value tells the endpoint to pass the extra parameters to the model. Use of extra parameters with the model doesn't guarantee that the model can actually handle them. Read the model's documentation to understand which extra parameters are supported.
Use tools
Some models support the use of tools, which can be an extraordinary resource when you need to offload specific tasks from the language model and instead rely on a more deterministic system or even a different language model. The Azure AI Model Inference API allows you to define tools in the following way.
The following code example creates a tool definition that is able to look from flight information from two different cities.
from azure.ai.inference.models import FunctionDefinition, ChatCompletionsFunctionToolDefinition
flight_info = ChatCompletionsFunctionToolDefinition(
function=FunctionDefinition(
name="get_flight_info",
description="Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters={
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates",
},
"destination_city": {
"type": "string",
"description": "The flight destination city",
},
},
"required": ["origin_city", "destination_city"],
},
)
)
tools = [flight_info]
In this example, the function's output is that there are no flights available for the selected route, but the user should consider taking a train.
def get_flight_info(loc_origin: str, loc_destination: str):
return {
"info": f"There are no flights available from {loc_origin} to {loc_destination}. You should take a train, specially if it helps to reduce CO2 emissions."
}
Note
Cohere models require a tool's responses to be a valid JSON content formatted as a string. When constructing messages of type Tool, ensure the response is a valid JSON string.
Prompt the model to book flights with the help of this function:
messages = [
SystemMessage(
content="You are a helpful assistant that help users to find information about traveling, how to get"
" to places and the different transportations options. You care about the environment and you"
" always have that in mind when answering inqueries.",
),
UserMessage(
content="When is the next flight from Miami to Seattle?",
),
]
response = client.complete(
messages=messages, tools=tools, tool_choice="auto"
)
You can inspect the response to find out if a tool needs to be called. Inspect the finish reason to determine if the tool should be called. Remember that multiple tool types can be indicated. This example demonstrates a tool of type function.
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
print("Finish reason:", response.choices[0].finish_reason)
print("Tool call:", tool_calls)
To continue, append this message to the chat history:
messages.append(
response_message
)
Now, it's time to call the appropriate function to handle the tool call. The following code snippet iterates over all the tool calls indicated in the response and calls the corresponding function with the appropriate parameters. The response is also appended to the chat history.
import json
from azure.ai.inference.models import ToolMessage
for tool_call in tool_calls:
# Get the tool details:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments.replace("\'", "\""))
tool_call_id = tool_call.id
print(f"Calling function `{function_name}` with arguments {function_args}")
# Call the function defined above using `locals()`, which returns the list of all functions
# available in the scope as a dictionary. Notice that this is just done as a simple way to get
# the function callable from its string name. Then we can call it with the corresponding
# arguments.
callable_func = locals()[function_name]
function_response = callable_func(**function_args)
print("->", function_response)
# Once we have a response from the function and its arguments, we can append a new message to the chat
# history. Notice how we are telling to the model that this chat message came from a tool:
messages.append(
ToolMessage(
tool_call_id=tool_call_id,
content=json.dumps(function_response)
)
)
View the response from the model:
response = client.complete(
messages=messages,
tools=tools,
)
Apply content safety
The Azure AI model inference API supports Azure AI content safety. When you use deployments with Azure AI content safety turned on, inputs and outputs pass through an ensemble of classification models aimed at detecting and preventing the output of harmful content. The content filtering system detects and takes action on specific categories of potentially harmful content in both input prompts and output completions.
The following example shows how to handle events when the model detects harmful content in the input prompt and content safety is enabled.
from azure.ai.inference.models import AssistantMessage, UserMessage, SystemMessage
try:
response = client.complete(
messages=[
SystemMessage(content="You are an AI assistant that helps people find information."),
UserMessage(content="Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."),
]
)
print(response.choices[0].message.content)
except HttpResponseError as ex:
if ex.status_code == 400:
response = ex.response.json()
if isinstance(response, dict) and "error" in response:
print(f"Your request triggered an {response['error']['code']} error:\n\t {response['error']['message']}")
else:
raise
raise
Tip
To learn more about how you can configure and control Azure AI content safety settings, check the Azure AI content safety documentation.
Use chat completions with images
Some models can reason across text and images and generate text completions based on both kinds of input. In this section, you explore the capabilities of Some models for vision in a chat fashion:
Important
Some models support only one image for each turn in the chat conversation and only the last image is retained in context. If you add multiple images, it results in an error.
To see this capability, download an image and encode the information as base64 string. The resulting data should be inside of a data URL:
from urllib.request import urlopen, Request
import base64
image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg"
image_format = "jpeg"
request = Request(image_url, headers={"User-Agent": "Mozilla/5.0"})
image_data = base64.b64encode(urlopen(request).read()).decode("utf-8")
data_url = f"data:image/{image_format};base64,{image_data}"
Visualize the image:
import requests
import IPython.display as Disp
Disp.Image(requests.get(image_url).content)

Now, create a chat completion request with the image:
from azure.ai.inference.models import TextContentItem, ImageContentItem, ImageUrl
response = client.complete(
messages=[
SystemMessage("You are a helpful assistant that can generate responses based on images."),
UserMessage(content=[
TextContentItem(text="Which conclusion can be extracted from the following chart?"),
ImageContentItem(image=ImageUrl(url=data_url))
]),
],
temperature=0,
top_p=1,
max_tokens=2048,
)
The response is as follows, where you can see the model's usage statistics:
print(f"{response.choices[0].message.role}:\n\t{response.choices[0].message.content}\n")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Important
Items marked (preview) in this article are currently in public preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
This article explains how to use chat completions API with models deployed to Azure AI model inference in Azure AI services.
Prerequisites
To use chat completion models in your application, you need:
An Azure subscription. If you're using GitHub Models, you can upgrade your experience and create an Azure subscription in the process. Read Upgrade from GitHub Models to Azure AI model inference if that's your case.
An Azure AI services resource. For more information, see Create an Azure AI Services resource.
The endpoint URL and key.
A chat completions model deployment. If you don't have one read Add and configure models to Azure AI services to add a chat completions model to your resource.
Install the Azure Inference library for JavaScript with the following command:
npm install @azure-rest/ai-inference
Use chat completions
First, create the client to consume the model. The following code uses an endpoint URL and key that are stored in environment variables.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL)
);
If you have configured the resource to with Microsoft Entra ID support, you can use the following code snippet to create a client.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new DefaultAzureCredential()
);
Create a chat completion request
The following example shows how you can create a basic chat completions request to the model.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
Note
Some models don't support system messages (role="system"). When you use the Azure AI model inference API, system messages are translated to user messages, which is the closest capability available. This translation is offered for convenience, but it's important for you to verify that the model is following the instructions in the system message with the right level of confidence.
The response is as follows, where you can see the model's usage statistics:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log("Response: ", response.body.choices[0].message.content);
console.log("Model: ", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Inspect the usage section in the response to see the number of tokens used for the prompt, the total number of tokens generated, and the number of tokens used for the completion.
Stream content
By default, the completions API returns the entire generated content in a single response. If you're generating long completions, waiting for the response can take many seconds.
You can stream the content to get it as it's being generated. Streaming content allows you to start processing the completion as content becomes available. This mode returns an object that streams back the response as data-only server-sent events. Extract chunks from the delta field, rather than the message field.
To stream completions, use .asNodeStream() when you call the model.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
}).asNodeStream();
You can visualize how streaming generates content:
var stream = response.body;
if (!stream) {
stream.destroy();
throw new Error(`Failed to get chat completions with status: ${response.status}`);
}
if (response.status !== "200") {
throw new Error(`Failed to get chat completions: ${response.body.error}`);
}
var sses = createSseStream(stream);
for await (const event of sses) {
if (event.data === "[DONE]") {
return;
}
for (const choice of (JSON.parse(event.data)).choices) {
console.log(choice.delta?.content ?? "");
}
}
Explore more parameters supported by the inference client
Explore other parameters that you can specify in the inference client. For a full list of all the supported parameters and their corresponding documentation, see Azure AI Model Inference API reference.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
presence_penalty: "0.1",
frequency_penalty: "0.8",
max_tokens: 2048,
stop: ["<|endoftext|>"],
temperature: 0,
top_p: 1,
response_format: { type: "text" },
}
});
Some models don't support JSON output formatting. You can always prompt the model to generate JSON outputs. However, such outputs are not guaranteed to be valid JSON.
If you want to pass a parameter that isn't in the list of supported parameters, you can pass it to the underlying model using extra parameters. See Pass extra parameters to the model.
Create JSON outputs
Some models can create JSON outputs. Set response_format to json_object to enable JSON mode and guarantee that the message the model generates is valid JSON. You must also instruct the model to produce JSON yourself via a system or user message. Also, the message content might be partially cut off if finish_reason="length", which indicates that the generation exceeded max_tokens or that the conversation exceeded the max context length.
var messages = [
{ role: "system", content: "You are a helpful assistant that always generate responses in JSON format, using."
+ " the following format: { \"answer\": \"response\" }." },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
response_format: { type: "json_object" }
}
});
Pass extra parameters to the model
The Azure AI Model Inference API allows you to pass extra parameters to the model. The following code example shows how to pass the extra parameter logprobs to the model.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
headers: {
"extra-params": "pass-through"
},
body: {
messages: messages,
logprobs: true
}
});
Before you pass extra parameters to the Azure AI model inference API, make sure your model supports those extra parameters. When the request is made to the underlying model, the header extra-parameters is passed to the model with the value pass-through. This value tells the endpoint to pass the extra parameters to the model. Use of extra parameters with the model doesn't guarantee that the model can actually handle them. Read the model's documentation to understand which extra parameters are supported.
Use tools
Some models support the use of tools, which can be an extraordinary resource when you need to offload specific tasks from the language model and instead rely on a more deterministic system or even a different language model. The Azure AI Model Inference API allows you to define tools in the following way.
The following code example creates a tool definition that is able to look from flight information from two different cities.
const flight_info = {
name: "get_flight_info",
description: "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters: {
type: "object",
properties: {
origin_city: {
type: "string",
description: "The name of the city where the flight originates",
},
destination_city: {
type: "string",
description: "The flight destination city",
},
},
required: ["origin_city", "destination_city"],
},
}
const tools = [
{
type: "function",
function: flight_info,
},
];
In this example, the function's output is that there are no flights available for the selected route, but the user should consider taking a train.
function get_flight_info(loc_origin, loc_destination) {
return {
info: "There are no flights available from " + loc_origin + " to " + loc_destination + ". You should take a train, specially if it helps to reduce CO2 emissions."
}
}
Note
Cohere models require a tool's responses to be a valid JSON content formatted as a string. When constructing messages of type Tool, ensure the response is a valid JSON string.
Prompt the model to book flights with the help of this function:
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
tool_choice: "auto"
}
});
You can inspect the response to find out if a tool needs to be called. Inspect the finish reason to determine if the tool should be called. Remember that multiple tool types can be indicated. This example demonstrates a tool of type function.
const response_message = response.body.choices[0].message;
const tool_calls = response_message.tool_calls;
console.log("Finish reason: " + response.body.choices[0].finish_reason);
console.log("Tool call: " + tool_calls);
To continue, append this message to the chat history:
messages.push(response_message);
Now, it's time to call the appropriate function to handle the tool call. The following code snippet iterates over all the tool calls indicated in the response and calls the corresponding function with the appropriate parameters. The response is also appended to the chat history.
function applyToolCall({ function: call, id }) {
// Get the tool details:
const tool_params = JSON.parse(call.arguments);
console.log("Calling function " + call.name + " with arguments " + tool_params);
// Call the function defined above using `window`, which returns the list of all functions
// available in the scope as a dictionary. Notice that this is just done as a simple way to get
// the function callable from its string name. Then we can call it with the corresponding
// arguments.
const function_response = tool_params.map(window[call.name]);
console.log("-> " + function_response);
return function_response
}
for (const tool_call of tool_calls) {
var tool_response = tool_call.apply(applyToolCall);
messages.push(
{
role: "tool",
tool_call_id: tool_call.id,
content: tool_response
}
);
}
View the response from the model:
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
}
});
Apply content safety
The Azure AI model inference API supports Azure AI content safety. When you use deployments with Azure AI content safety turned on, inputs and outputs pass through an ensemble of classification models aimed at detecting and preventing the output of harmful content. The content filtering system detects and takes action on specific categories of potentially harmful content in both input prompts and output completions.
The following example shows how to handle events when the model detects harmful content in the input prompt and content safety is enabled.
try {
var messages = [
{ role: "system", content: "You are an AI assistant that helps people find information." },
{ role: "user", content: "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills." },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
console.log(response.body.choices[0].message.content);
}
catch (error) {
if (error.status_code == 400) {
var response = JSON.parse(error.response._content);
if (response.error) {
console.log(`Your request triggered an ${response.error.code} error:\n\t ${response.error.message}`);
}
else
{
throw error;
}
}
}
Tip
To learn more about how you can configure and control Azure AI content safety settings, check the Azure AI content safety documentation.
Use chat completions with images
Some models can reason across text and images and generate text completions based on both kinds of input. In this section, you explore the capabilities of Some models for vision in a chat fashion:
Important
Some models support only one image for each turn in the chat conversation and only the last image is retained in context. If you add multiple images, it results in an error.
To see this capability, download an image and encode the information as base64 string. The resulting data should be inside of a data URL:
const image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
const image_format = "jpeg";
const response = await fetch(image_url, { headers: { "User-Agent": "Mozilla/5.0" } });
const image_data = await response.arrayBuffer();
const image_data_base64 = Buffer.from(image_data).toString("base64");
const data_url = `data:image/${image_format};base64,${image_data_base64}`;
Visualize the image:
const img = document.createElement("img");
img.src = data_url;
document.body.appendChild(img);
Now, create a chat completion request with the image:
var messages = [
{ role: "system", content: "You are a helpful assistant that can generate responses based on images." },
{ role: "user", content:
[
{ type: "text", text: "Which conclusion can be extracted from the following chart?" },
{ type: "image_url", image:
{
url: data_url
}
}
]
}
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
temperature: 0,
top_p: 1,
max_tokens: 2048,
}
});
The response is as follows, where you can see the model's usage statistics:
console.log(response.body.choices[0].message.role + ": " + response.body.choices[0].message.content);
console.log("Model:", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Important
Items marked (preview) in this article are currently in public preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
This article explains how to use chat completions API with models deployed to Azure AI model inference in Azure AI services.
Prerequisites
To use chat completion models in your application, you need:
An Azure subscription. If you're using GitHub Models, you can upgrade your experience and create an Azure subscription in the process. Read Upgrade from GitHub Models to Azure AI model inference if that's your case.
An Azure AI services resource. For more information, see Create an Azure AI Services resource.
The endpoint URL and key.
A chat completions model deployment. If you don't have one read Add and configure models to Azure AI services to add a chat completions model to your resource.
Add the Azure AI inference package to your project:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.1</version> </dependency>If you are using Entra ID, you also need the following package:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>Import the following namespace:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
Use chat completions
First, create the client to consume the model. The following code uses an endpoint URL and key that are stored in environment variables.
If you have configured the resource to with Microsoft Entra ID support, you can use the following code snippet to create a client.
Create a chat completion request
The following example shows how you can create a basic chat completions request to the model.
Note
Some models don't support system messages (role="system"). When you use the Azure AI model inference API, system messages are translated to user messages, which is the closest capability available. This translation is offered for convenience, but it's important for you to verify that the model is following the instructions in the system message with the right level of confidence.
The response is as follows, where you can see the model's usage statistics:
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Inspect the usage section in the response to see the number of tokens used for the prompt, the total number of tokens generated, and the number of tokens used for the completion.
Stream content
By default, the completions API returns the entire generated content in a single response. If you're generating long completions, waiting for the response can take many seconds.
You can stream the content to get it as it's being generated. Streaming content allows you to start processing the completion as content becomes available. This mode returns an object that streams back the response as data-only server-sent events. Extract chunks from the delta field, rather than the message field.
You can visualize how streaming generates content:
Explore more parameters supported by the inference client
Explore other parameters that you can specify in the inference client. For a full list of all the supported parameters and their corresponding documentation, see Azure AI Model Inference API reference. Some models don't support JSON output formatting. You can always prompt the model to generate JSON outputs. However, such outputs are not guaranteed to be valid JSON.
If you want to pass a parameter that isn't in the list of supported parameters, you can pass it to the underlying model using extra parameters. See Pass extra parameters to the model.
Create JSON outputs
Some models can create JSON outputs. Set response_format to json_object to enable JSON mode and guarantee that the message the model generates is valid JSON. You must also instruct the model to produce JSON yourself via a system or user message. Also, the message content might be partially cut off if finish_reason="length", which indicates that the generation exceeded max_tokens or that the conversation exceeded the max context length.
Pass extra parameters to the model
The Azure AI Model Inference API allows you to pass extra parameters to the model. The following code example shows how to pass the extra parameter logprobs to the model.
Before you pass extra parameters to the Azure AI model inference API, make sure your model supports those extra parameters. When the request is made to the underlying model, the header extra-parameters is passed to the model with the value pass-through. This value tells the endpoint to pass the extra parameters to the model. Use of extra parameters with the model doesn't guarantee that the model can actually handle them. Read the model's documentation to understand which extra parameters are supported.
Use tools
Some models support the use of tools, which can be an extraordinary resource when you need to offload specific tasks from the language model and instead rely on a more deterministic system or even a different language model. The Azure AI Model Inference API allows you to define tools in the following way.
The following code example creates a tool definition that is able to look from flight information from two different cities.
In this example, the function's output is that there are no flights available for the selected route, but the user should consider taking a train.
Note
Cohere models require a tool's responses to be a valid JSON content formatted as a string. When constructing messages of type Tool, ensure the response is a valid JSON string.
Prompt the model to book flights with the help of this function:
You can inspect the response to find out if a tool needs to be called. Inspect the finish reason to determine if the tool should be called. Remember that multiple tool types can be indicated. This example demonstrates a tool of type function.
To continue, append this message to the chat history:
Now, it's time to call the appropriate function to handle the tool call. The following code snippet iterates over all the tool calls indicated in the response and calls the corresponding function with the appropriate parameters. The response is also appended to the chat history.
View the response from the model:
Apply content safety
The Azure AI model inference API supports Azure AI content safety. When you use deployments with Azure AI content safety turned on, inputs and outputs pass through an ensemble of classification models aimed at detecting and preventing the output of harmful content. The content filtering system detects and takes action on specific categories of potentially harmful content in both input prompts and output completions.
The following example shows how to handle events when the model detects harmful content in the input prompt and content safety is enabled.
Tip
To learn more about how you can configure and control Azure AI content safety settings, check the Azure AI content safety documentation.
Use chat completions with images
Some models can reason across text and images and generate text completions based on both kinds of input. In this section, you explore the capabilities of Some models for vision in a chat fashion:
Important
Some models support only one image for each turn in the chat conversation and only the last image is retained in context. If you add multiple images, it results in an error.
To see this capability, download an image and encode the information as base64 string. The resulting data should be inside of a data URL:
Visualize the image:
Now, create a chat completion request with the image:
The response is as follows, where you can see the model's usage statistics:
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Important
Items marked (preview) in this article are currently in public preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
This article explains how to use chat completions API with models deployed to Azure AI model inference in Azure AI services.
Prerequisites
To use chat completion models in your application, you need:
An Azure subscription. If you're using GitHub Models, you can upgrade your experience and create an Azure subscription in the process. Read Upgrade from GitHub Models to Azure AI model inference if that's your case.
An Azure AI services resource. For more information, see Create an Azure AI Services resource.
The endpoint URL and key.
A chat completions model deployment. If you don't have one read Add and configure models to Azure AI services to add a chat completions model to your resource.
Install the Azure AI inference package with the following command:
dotnet add package Azure.AI.Inference --prereleaseIf you are using Entra ID, you also need the following package:
dotnet add package Azure.Identity
Use chat completions
First, create the client to consume the model. The following code uses an endpoint URL and key that are stored in environment variables.
ChatCompletionsClient client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
);
If you have configured the resource to with Microsoft Entra ID support, you can use the following code snippet to create a client.
TokenCredential credential = new DefaultAzureCredential(includeInteractiveCredentials: true);
AzureAIInferenceClientOptions clientOptions = new AzureAIInferenceClientOptions();
BearerTokenAuthenticationPolicy tokenPolicy = new BearerTokenAuthenticationPolicy(credential, new string[] { "https://cognitiveservices.azure.com/.default" });
clientOptions.AddPolicy(tokenPolicy, HttpPipelinePosition.PerRetry);
client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
credential,
clientOptions,
);
Create a chat completion request
The following example shows how you can create a basic chat completions request to the model.
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
Model = "mistral-large-2407",
};
Response<ChatCompletions> response = client.Complete(requestOptions);
Note
Some models don't support system messages (role="system"). When you use the Azure AI model inference API, system messages are translated to user messages, which is the closest capability available. This translation is offered for convenience, but it's important for you to verify that the model is following the instructions in the system message with the right level of confidence.
The response is as follows, where you can see the model's usage statistics:
Console.WriteLine($"Response: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Inspect the usage section in the response to see the number of tokens used for the prompt, the total number of tokens generated, and the number of tokens used for the completion.
Stream content
By default, the completions API returns the entire generated content in a single response. If you're generating long completions, waiting for the response can take many seconds.
You can stream the content to get it as it's being generated. Streaming content allows you to start processing the completion as content becomes available. This mode returns an object that streams back the response as data-only server-sent events. Extract chunks from the delta field, rather than the message field.
To stream completions, use CompleteStreamingAsync method when you call the model. Notice that in this example we the call is wrapped in an asynchronous method.
static async Task StreamMessageAsync(ChatCompletionsClient client)
{
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world? Write an essay about it.")
},
MaxTokens=4096,
Model = "mistral-large-2407",
};
StreamingResponse<StreamingChatCompletionsUpdate> streamResponse = await client.CompleteStreamingAsync(requestOptions);
await PrintStream(streamResponse);
}
To visualize the output, define an asynchronous method to print the stream in the console.
static async Task PrintStream(StreamingResponse<StreamingChatCompletionsUpdate> response)
{
await foreach (StreamingChatCompletionsUpdate chatUpdate in response)
{
if (chatUpdate.Role.HasValue)
{
Console.Write($"{chatUpdate.Role.Value.ToString().ToUpperInvariant()}: ");
}
if (!string.IsNullOrEmpty(chatUpdate.ContentUpdate))
{
Console.Write(chatUpdate.ContentUpdate);
}
}
}
You can visualize how streaming generates content:
StreamMessageAsync(client).GetAwaiter().GetResult();
Explore more parameters supported by the inference client
Explore other parameters that you can specify in the inference client. For a full list of all the supported parameters and their corresponding documentation, see Azure AI Model Inference API reference.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
Model = "mistral-large-2407",
PresencePenalty = 0.1f,
FrequencyPenalty = 0.8f,
MaxTokens = 2048,
StopSequences = { "<|endoftext|>" },
Temperature = 0,
NucleusSamplingFactor = 1,
ResponseFormat = new ChatCompletionsResponseFormatText()
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
Some models don't support JSON output formatting. You can always prompt the model to generate JSON outputs. However, such outputs are not guaranteed to be valid JSON.
If you want to pass a parameter that isn't in the list of supported parameters, you can pass it to the underlying model using extra parameters. See Pass extra parameters to the model.
Create JSON outputs
Some models can create JSON outputs. Set response_format to json_object to enable JSON mode and guarantee that the message the model generates is valid JSON. You must also instruct the model to produce JSON yourself via a system or user message. Also, the message content might be partially cut off if finish_reason="length", which indicates that the generation exceeded max_tokens or that the conversation exceeded the max context length.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage(
"You are a helpful assistant that always generate responses in JSON format, " +
"using. the following format: { \"answer\": \"response\" }."
),
new ChatRequestUserMessage(
"How many languages are in the world?"
)
},
ResponseFormat = new ChatCompletionsResponseFormatJsonObject(),
Model = "mistral-large-2407",
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
Pass extra parameters to the model
The Azure AI Model Inference API allows you to pass extra parameters to the model. The following code example shows how to pass the extra parameter logprobs to the model.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
Model = "mistral-large-2407",
AdditionalProperties = { { "logprobs", BinaryData.FromString("true") } },
};
response = client.Complete(requestOptions, extraParams: ExtraParameters.PassThrough);
Console.WriteLine($"Response: {response.Value.Content}");
Before you pass extra parameters to the Azure AI model inference API, make sure your model supports those extra parameters. When the request is made to the underlying model, the header extra-parameters is passed to the model with the value pass-through. This value tells the endpoint to pass the extra parameters to the model. Use of extra parameters with the model doesn't guarantee that the model can actually handle them. Read the model's documentation to understand which extra parameters are supported.
Use tools
Some models support the use of tools, which can be an extraordinary resource when you need to offload specific tasks from the language model and instead rely on a more deterministic system or even a different language model. The Azure AI Model Inference API allows you to define tools in the following way.
The following code example creates a tool definition that is able to look from flight information from two different cities.
FunctionDefinition flightInfoFunction = new FunctionDefinition("getFlightInfo")
{
Description = "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
Parameters = BinaryData.FromObjectAsJson(new
{
Type = "object",
Properties = new
{
origin_city = new
{
Type = "string",
Description = "The name of the city where the flight originates"
},
destination_city = new
{
Type = "string",
Description = "The flight destination city"
}
}
},
new JsonSerializerOptions() { PropertyNamingPolicy = JsonNamingPolicy.CamelCase }
)
};
ChatCompletionsFunctionToolDefinition getFlightTool = new ChatCompletionsFunctionToolDefinition(flightInfoFunction);
In this example, the function's output is that there are no flights available for the selected route, but the user should consider taking a train.
static string getFlightInfo(string loc_origin, string loc_destination)
{
return JsonSerializer.Serialize(new
{
info = $"There are no flights available from {loc_origin} to {loc_destination}. You " +
"should take a train, specially if it helps to reduce CO2 emissions."
});
}
Note
Cohere models require a tool's responses to be a valid JSON content formatted as a string. When constructing messages of type Tool, ensure the response is a valid JSON string.
Prompt the model to book flights with the help of this function:
var chatHistory = new List<ChatRequestMessage>(){
new ChatRequestSystemMessage(
"You are a helpful assistant that help users to find information about traveling, " +
"how to get to places and the different transportations options. You care about the" +
"environment and you always have that in mind when answering inqueries."
),
new ChatRequestUserMessage("When is the next flight from Miami to Seattle?")
};
requestOptions = new ChatCompletionsOptions(chatHistory, model: "mistral-large-2407");
requestOptions.Tools.Add(getFlightTool);
requestOptions.ToolChoice = ChatCompletionsToolChoice.Auto;
response = client.Complete(requestOptions);
You can inspect the response to find out if a tool needs to be called. Inspect the finish reason to determine if the tool should be called. Remember that multiple tool types can be indicated. This example demonstrates a tool of type function.
var responseMessage = response.Value;
var toolsCall = responseMessage.ToolCalls;
Console.WriteLine($"Finish reason: {response.Value.Choices[0].FinishReason}");
Console.WriteLine($"Tool call: {toolsCall[0].Id}");
To continue, append this message to the chat history:
requestOptions.Messages.Add(new ChatRequestAssistantMessage(response.Value));
Now, it's time to call the appropriate function to handle the tool call. The following code snippet iterates over all the tool calls indicated in the response and calls the corresponding function with the appropriate parameters. The response is also appended to the chat history.
foreach (ChatCompletionsToolCall tool in toolsCall)
{
if (tool is ChatCompletionsFunctionToolCall functionTool)
{
// Get the tool details:
string callId = functionTool.Id;
string toolName = functionTool.Name;
string toolArgumentsString = functionTool.Arguments;
Dictionary<string, object> toolArguments = JsonSerializer.Deserialize<Dictionary<string, object>>(toolArgumentsString);
// Here you have to call the function defined. In this particular example we use
// reflection to find the method we definied before in an static class called
// `ChatCompletionsExamples`. Using reflection allows us to call a function
// by string name. Notice that this is just done for demonstration purposes as a
// simple way to get the function callable from its string name. Then we can call
// it with the corresponding arguments.
var flags = BindingFlags.Instance | BindingFlags.Public | BindingFlags.NonPublic | BindingFlags.Static;
string toolResponse = (string)typeof(ChatCompletionsExamples).GetMethod(toolName, flags).Invoke(null, toolArguments.Values.Cast<object>().ToArray());
Console.WriteLine("->", toolResponse);
requestOptions.Messages.Add(new ChatRequestToolMessage(toolResponse, callId));
}
else
throw new Exception("Unsupported tool type");
}
View the response from the model:
response = client.Complete(requestOptions);
Apply content safety
The Azure AI model inference API supports Azure AI content safety. When you use deployments with Azure AI content safety turned on, inputs and outputs pass through an ensemble of classification models aimed at detecting and preventing the output of harmful content. The content filtering system detects and takes action on specific categories of potentially harmful content in both input prompts and output completions.
The following example shows how to handle events when the model detects harmful content in the input prompt and content safety is enabled.
try
{
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage(
"Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
),
},
Model = "mistral-large-2407",
};
response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
}
catch (RequestFailedException ex)
{
if (ex.ErrorCode == "content_filter")
{
Console.WriteLine($"Your query has trigger Azure Content Safety: {ex.Message}");
}
else
{
throw;
}
}
Tip
To learn more about how you can configure and control Azure AI content safety settings, check the Azure AI content safety documentation.
Use chat completions with images
Some models can reason across text and images and generate text completions based on both kinds of input. In this section, you explore the capabilities of Some models for vision in a chat fashion:
Important
Some models support only one image for each turn in the chat conversation and only the last image is retained in context. If you add multiple images, it results in an error.
To see this capability, download an image and encode the information as base64 string. The resulting data should be inside of a data URL:
string imageUrl = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
string imageFormat = "jpeg";
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0");
byte[] imageBytes = httpClient.GetByteArrayAsync(imageUrl).Result;
string imageBase64 = Convert.ToBase64String(imageBytes);
string dataUrl = $"data:image/{imageFormat};base64,{imageBase64}";
Visualize the image:
Now, create a chat completion request with the image:
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage([
new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"),
new ChatMessageImageContentItem(new Uri(dataUrl))
]),
},
MaxTokens=2048,
Model = "phi-3.5-vision-instruct",
};
var response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
The response is as follows, where you can see the model's usage statistics:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: phi-3.5-vision-instruct
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Important
Items marked (preview) in this article are currently in public preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
This article explains how to use chat completions API with models deployed to Azure AI model inference in Azure AI services.
Prerequisites
To use chat completion models in your application, you need:
An Azure subscription. If you're using GitHub Models, you can upgrade your experience and create an Azure subscription in the process. Read Upgrade from GitHub Models to Azure AI model inference if that's your case.
An Azure AI services resource. For more information, see Create an Azure AI Services resource.
The endpoint URL and key.
- A chat completions model deployment. If you don't have one read Add and configure models to Azure AI services to add a chat completions model to your resource.
Use chat completions
To use the text embeddings, use the route /chat/completions appended to the base URL along with your credential indicated in api-key. Authorization header is also supported with the format Bearer <key>.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
If you have configured the resource with Microsoft Entra ID support, pass you token in the Authorization header:
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
Create a chat completion request
The following example shows how you can create a basic chat completions request to the model.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
]
}
Note
Some models don't support system messages (role="system"). When you use the Azure AI model inference API, system messages are translated to user messages, which is the closest capability available. This translation is offered for convenience, but it's important for you to verify that the model is following the instructions in the system message with the right level of confidence.
The response is as follows, where you can see the model's usage statistics:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Inspect the usage section in the response to see the number of tokens used for the prompt, the total number of tokens generated, and the number of tokens used for the completion.
Stream content
By default, the completions API returns the entire generated content in a single response. If you're generating long completions, waiting for the response can take many seconds.
You can stream the content to get it as it's being generated. Streaming content allows you to start processing the completion as content becomes available. This mode returns an object that streams back the response as data-only server-sent events. Extract chunks from the delta field, rather than the message field.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"stream": true,
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
You can visualize how streaming generates content:
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": ""
},
"finish_reason": null,
"logprobs": null
}
]
}
The last message in the stream has finish_reason set, indicating the reason for the generation process to stop.
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"content": ""
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Explore more parameters supported by the inference client
Explore other parameters that you can specify in the inference client. For a full list of all the supported parameters and their corresponding documentation, see Azure AI Model Inference API reference.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"presence_penalty": 0.1,
"frequency_penalty": 0.8,
"max_tokens": 2048,
"stop": ["<|endoftext|>"],
"temperature" :0,
"top_p": 1,
"response_format": { "type": "text" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Some models don't support JSON output formatting. You can always prompt the model to generate JSON outputs. However, such outputs are not guaranteed to be valid JSON.
If you want to pass a parameter that isn't in the list of supported parameters, you can pass it to the underlying model using extra parameters. See Pass extra parameters to the model.
Create JSON outputs
Some models can create JSON outputs. Set response_format to json_object to enable JSON mode and guarantee that the message the model generates is valid JSON. You must also instruct the model to produce JSON yourself via a system or user message. Also, the message content might be partially cut off if finish_reason="length", which indicates that the generation exceeded max_tokens or that the conversation exceeded the max context length.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that always generate responses in JSON format, using the following format: { \"answer\": \"response\" }"
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"response_format": { "type": "json_object" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718727522,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "{\"answer\": \"There are approximately 7,117 living languages in the world today, according to the latest estimates. However, this number can vary as some languages become extinct and others are newly discovered or classified.\"}",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 39,
"total_tokens": 87,
"completion_tokens": 48
}
}
Pass extra parameters to the model
The Azure AI Model Inference API allows you to pass extra parameters to the model. The following code example shows how to pass the extra parameter logprobs to the model.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Authorization: Bearer <TOKEN>
Content-Type: application/json
extra-parameters: pass-through
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"logprobs": true
}
Before you pass extra parameters to the Azure AI model inference API, make sure your model supports those extra parameters. When the request is made to the underlying model, the header extra-parameters is passed to the model with the value pass-through. This value tells the endpoint to pass the extra parameters to the model. Use of extra parameters with the model doesn't guarantee that the model can actually handle them. Read the model's documentation to understand which extra parameters are supported.
Use tools
Some models support the use of tools, which can be an extraordinary resource when you need to offload specific tasks from the language model and instead rely on a more deterministic system or even a different language model. The Azure AI Model Inference API allows you to define tools in the following way.
The following code example creates a tool definition that is able to look from flight information from two different cities.
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
In this example, the function's output is that there are no flights available for the selected route, but the user should consider taking a train.
Note
Cohere models require a tool's responses to be a valid JSON content formatted as a string. When constructing messages of type Tool, ensure the response is a valid JSON string.
Prompt the model to book flights with the help of this function:
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
]
}
You can inspect the response to find out if a tool needs to be called. Inspect the finish reason to determine if the tool should be called. Remember that multiple tool types can be indicated. This example demonstrates a tool of type function.
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726007,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0dF1gh",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
"finish_reason": "tool_calls",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 190,
"total_tokens": 226,
"completion_tokens": 36
}
}
To continue, append this message to the chat history:
Now, it's time to call the appropriate function to handle the tool call. The following code snippet iterates over all the tool calls indicated in the response and calls the corresponding function with the appropriate parameters. The response is also appended to the chat history.
View the response from the model:
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0DeFgH",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
{
"role": "tool",
"content": "{ \"info\": \"There are no flights available from Miami to Seattle. You should take a train, specially if it helps to reduce CO2 emissions.\" }",
"tool_call_id": "abc0DeFgH"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters":{
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": ["origin_city", "destination_city"]
}
}
}
]
}
Apply content safety
The Azure AI model inference API supports Azure AI content safety. When you use deployments with Azure AI content safety turned on, inputs and outputs pass through an ensemble of classification models aimed at detecting and preventing the output of harmful content. The content filtering system detects and takes action on specific categories of potentially harmful content in both input prompts and output completions.
The following example shows how to handle events when the model detects harmful content in the input prompt and content safety is enabled.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are an AI assistant that helps people find information."
},
{
"role": "user",
"content": "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
}
]
}
{
"error": {
"message": "The response was filtered due to the prompt triggering Microsoft's content management policy. Please modify your prompt and retry.",
"type": null,
"param": "prompt",
"code": "content_filter",
"status": 400
}
}
Tip
To learn more about how you can configure and control Azure AI content safety settings, check the Azure AI content safety documentation.
Use chat completions with images
Some models can reason across text and images and generate text completions based on both kinds of input. In this section, you explore the capabilities of Some models for vision in a chat fashion:
Important
Some models support only one image for each turn in the chat conversation and only the last image is retained in context. If you add multiple images, it results in an error.
To see this capability, download an image and encode the information as base64 string. The resulting data should be inside of a data URL:
Tip
You will need to construct the data URL using a scripting or programming language. This tutorial use this sample image in JPEG format. A data URL has a format as follows: data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ....
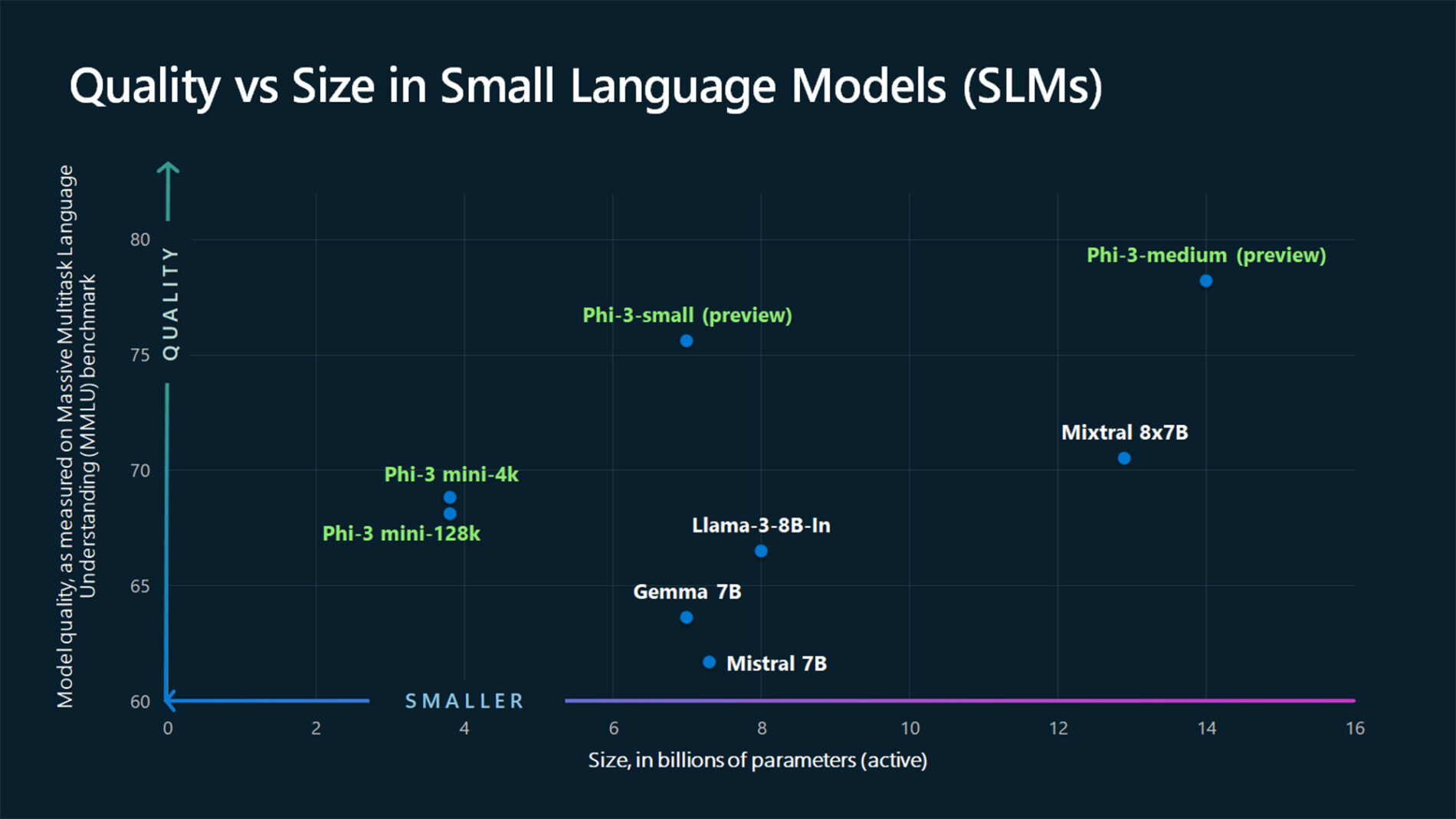{kind=link}
Visualize the image:
Now, create a chat completion request with the image:
{
"model": "phi-3.5-vision-instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Which peculiar conclusion about LLMs and SLMs can be extracted from the following chart?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ..."
}
}
]
}
],
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
The response is as follows, where you can see the model's usage statistics:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "phi-3.5-vision-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 2380,
"completion_tokens": 126,
"total_tokens": 2506
}
}