Optimera deltatabeller
Spark är ett ramverk för parallell bearbetning med data som lagras på en eller flera arbetsnoder. Dessutom är Parquet-filer oföränderliga, med nya filer skrivna för varje uppdatering eller borttagning. Den här processen kan leda till att Spark lagrar data i ett stort antal små filer, så kallade små filproblem. Det innebär att frågor om stora mängder data kan köras långsamt eller till och med misslyckas.
Funktionen OptimizeWrite
OptimizeWrite är en funktion i Delta Lake som minskar antalet filer när de skrivs. I stället för att skriva många små filer skrivs färre större filer. Detta hjälper till att förhindra problemet med små filer och se till att prestanda inte försämras.
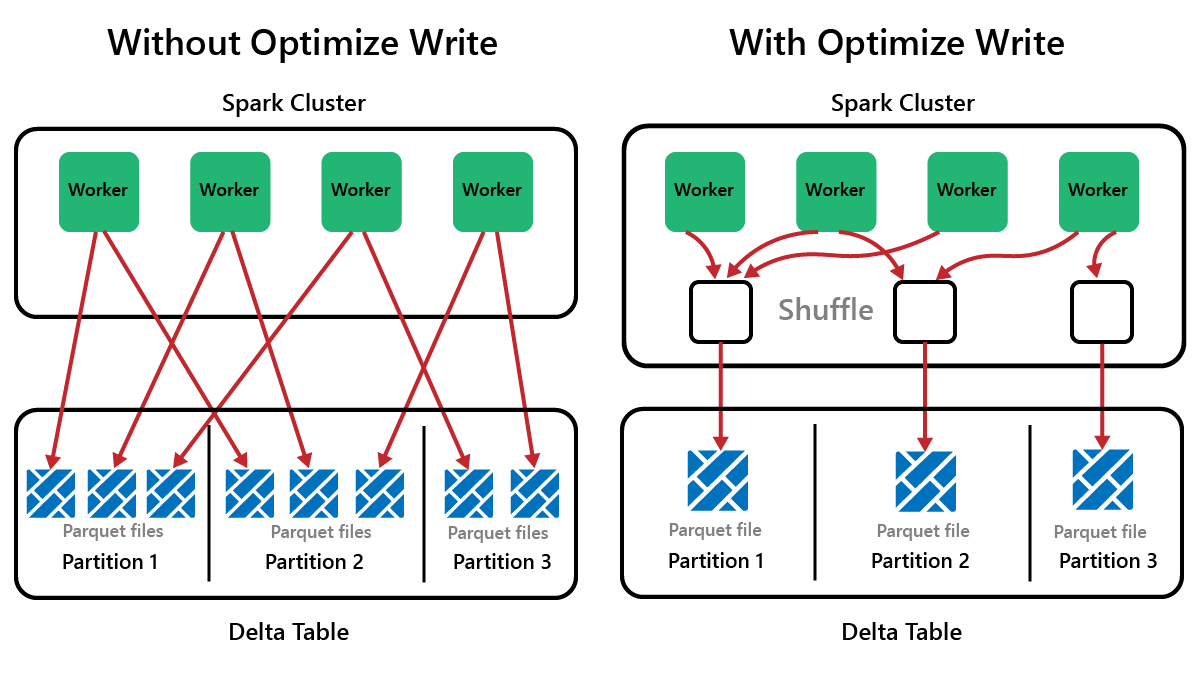
I Microsoft Fabric OptimizeWrite är aktiverat som standard. Du kan aktivera eller inaktivera det på Spark-sessionsnivå:
# Disable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", False)
# Enable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", True)
print(spark.conf.get("spark.microsoft.delta.optimizeWrite.enabled"))
Kommentar
OptimizeWrite kan också anges i Tabellegenskaper och för enskilda skrivkommandon.
Optimera
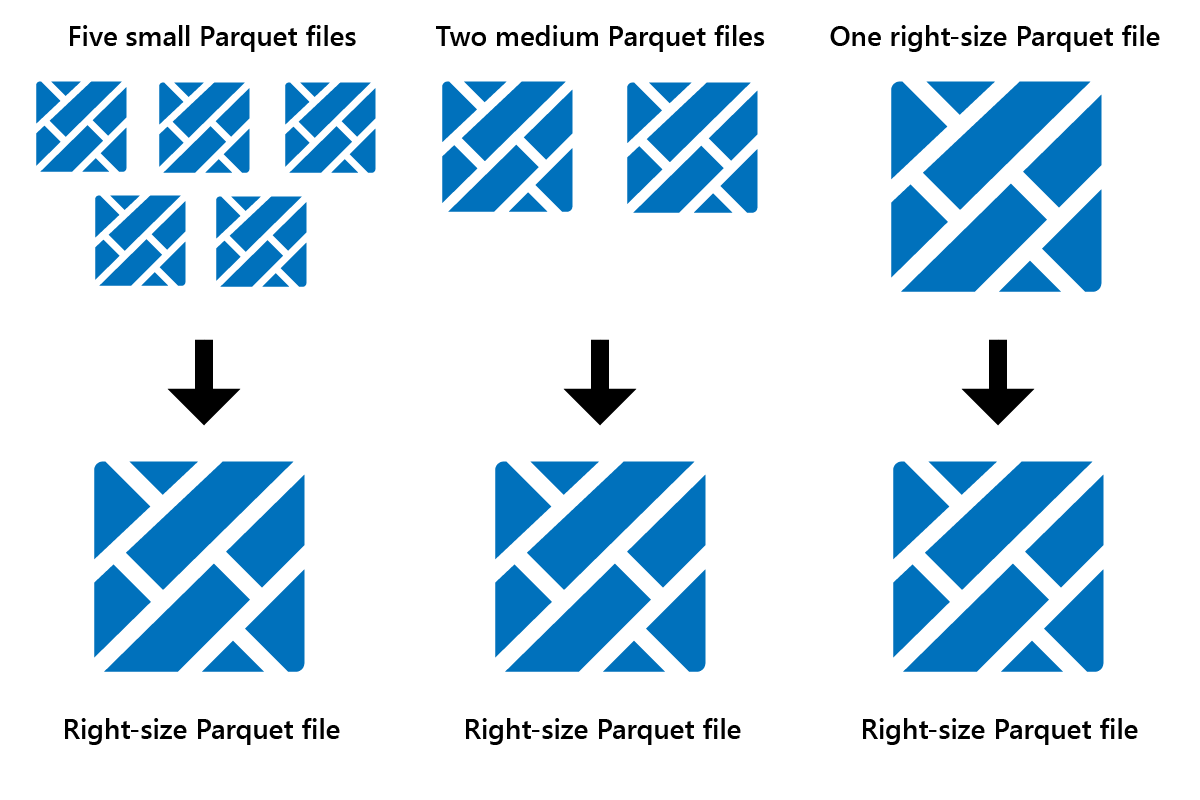
Optimize är en tabellunderhållsfunktion som konsoliderar små Parquet-filer till färre stora filer. Du kan köra Optimera när du har läst in stora tabeller, vilket resulterar i:
- färre större filer
- bättre komprimering
- effektiv datadistribution mellan noder
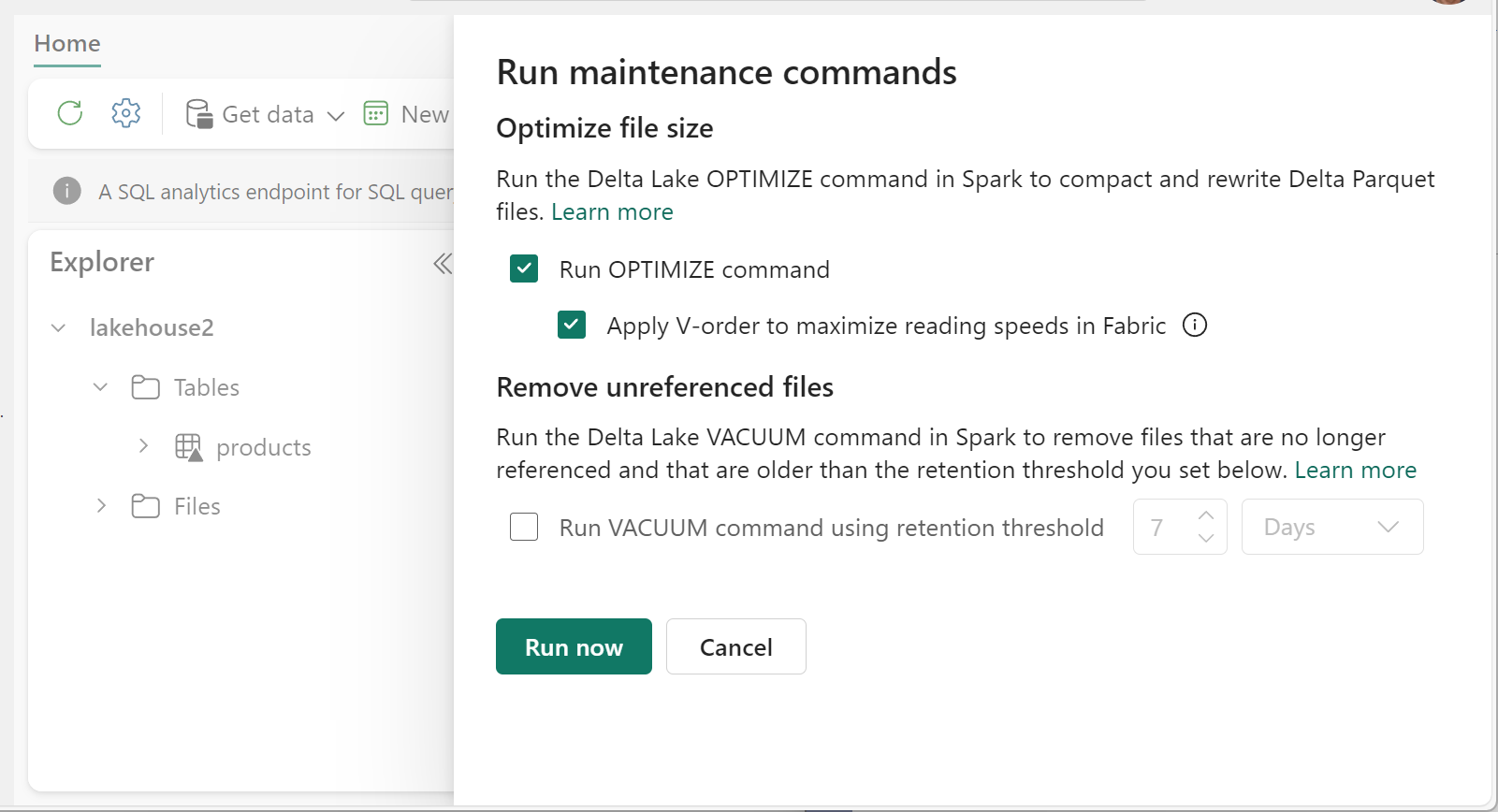
Så här kör du Optimera:
- I Lakehouse Explorer väljer du ... bredvid ett tabellnamn och välj Underhåll.
- Välj Kör KOMMANDOT OPTIMERA.
- Du kan också välja Använd V-ordning för att maximera läshastigheterna i Infrastrukturresurser.
- Välj kör nu.
Funktionen V-Order
När du kör Optimera kan du även köra V-Order, som är utformat för Parquet-filformatet i Fabric. V-Order möjliggör blixtsnabba läsningar med minnesbaserade dataåtkomsttider. Det förbättrar också kostnadseffektiviteten eftersom det minskar nätverks-, disk- och CPU-resurser under läsningar.
V-Order är aktiverat som standard i Microsoft Fabric och tillämpas när data skrivs. Det medför en liten omkostnad på cirka 15 % vilket gör skrivningar lite långsammare. V-Order möjliggör dock snabbare läsningar från Microsoft Fabric-beräkningsmotorerna, till exempel Power BI, SQL, Spark och andra.
I Microsoft Fabric använder Power BI- och SQL-motorerna Microsoft Verti-Scan-teknik som drar full nytta av V-Order-optimering för att påskynda läsningar. Spark och andra motorer använder inte VertiScan-teknik men drar fortfarande nytta av V-Order-optimering med cirka 10 % snabbare läsningar, ibland upp till 50 %.
V-Order fungerar genom att använda särskild sortering, radgruppsdistribution, ordlistekodning och komprimering på Parquet-filer. Det är 100 % kompatibelt med Parquet-formatet med öppen källkod och alla Parquet-motorer kan läsa det.
V-Order kanske inte är fördelaktigt för skrivintensiva scenarier, till exempel mellanlagring av datalager där data bara läse en eller två gånger. I dessa situationer kan inaktivering av V-Order minska den totala bearbetningstiden för datainmatning.
Använd V-Order på enskilda tabeller med hjälp av funktionen Tabellunderhåll genom att köra OPTIMIZE kommandot .
Vakuum
Med kommandot VACUUM kan du ta bort gamla datafiler.
Varje gång en uppdatering eller borttagning görs skapas en ny Parquet-fil och en post görs i transaktionsloggen. Gamla Parquet-filer behålls för att möjliggöra tidsresor, vilket innebär att Parquet-filer ackumuleras över tid.
KOMMANDOT VACUUM tar bort gamla Parquet-datafiler, men inte transaktionsloggarna. När du kör VACUUM kan du inte gå tillbaka tidigare än kvarhållningsperioden.
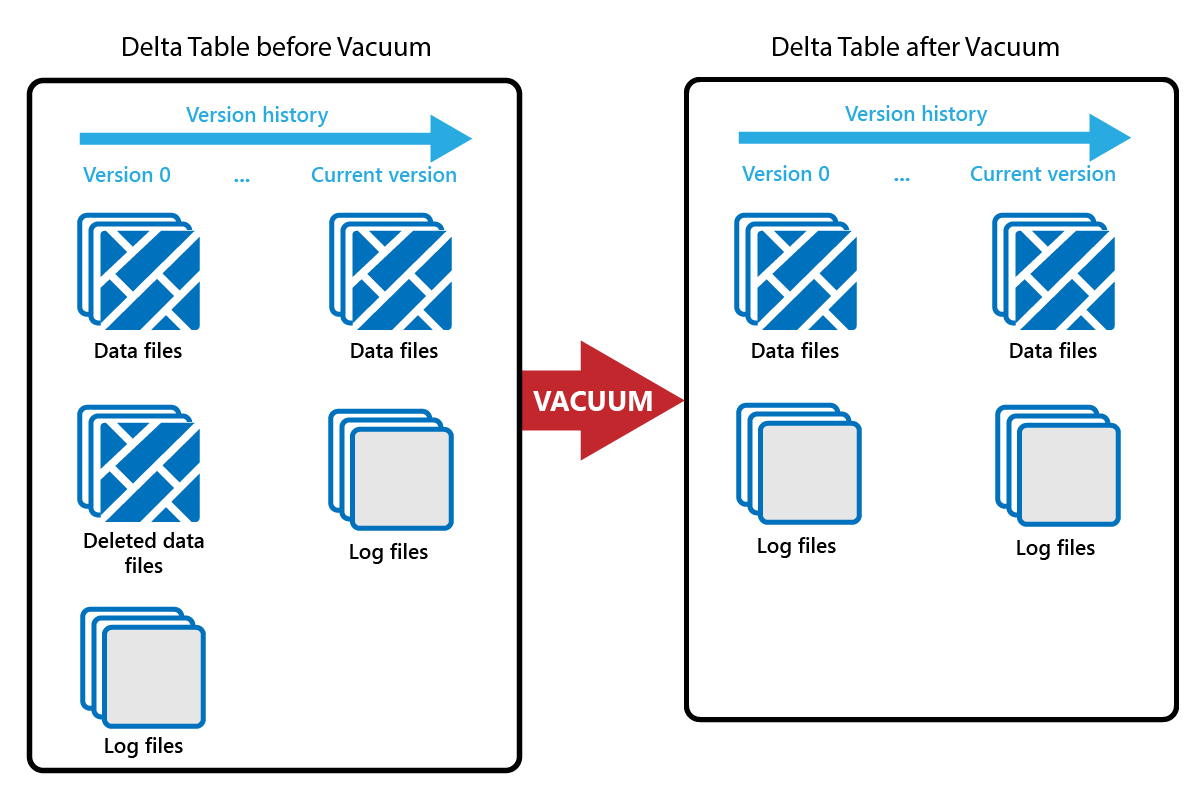
Datafiler som för närvarande inte refereras till i en transaktionslogg och som är äldre än den angivna kvarhållningsperioden tas bort permanent genom att vacuum körs. Välj kvarhållningsperiod baserat på faktorer som:
- Krav för datakvarhållning
- Kostnader för datastorlek och lagring
- Dataändringsfrekvens
- Myndighetskrav
Standardkvarhållningsperioden är 7 dagar (168 timmar) och systemet hindrar dig från att använda en kortare kvarhållningsperiod.
Du kan köra VACUUM på ad hoc-basis eller schemalägga med hjälp av Fabric Notebooks.
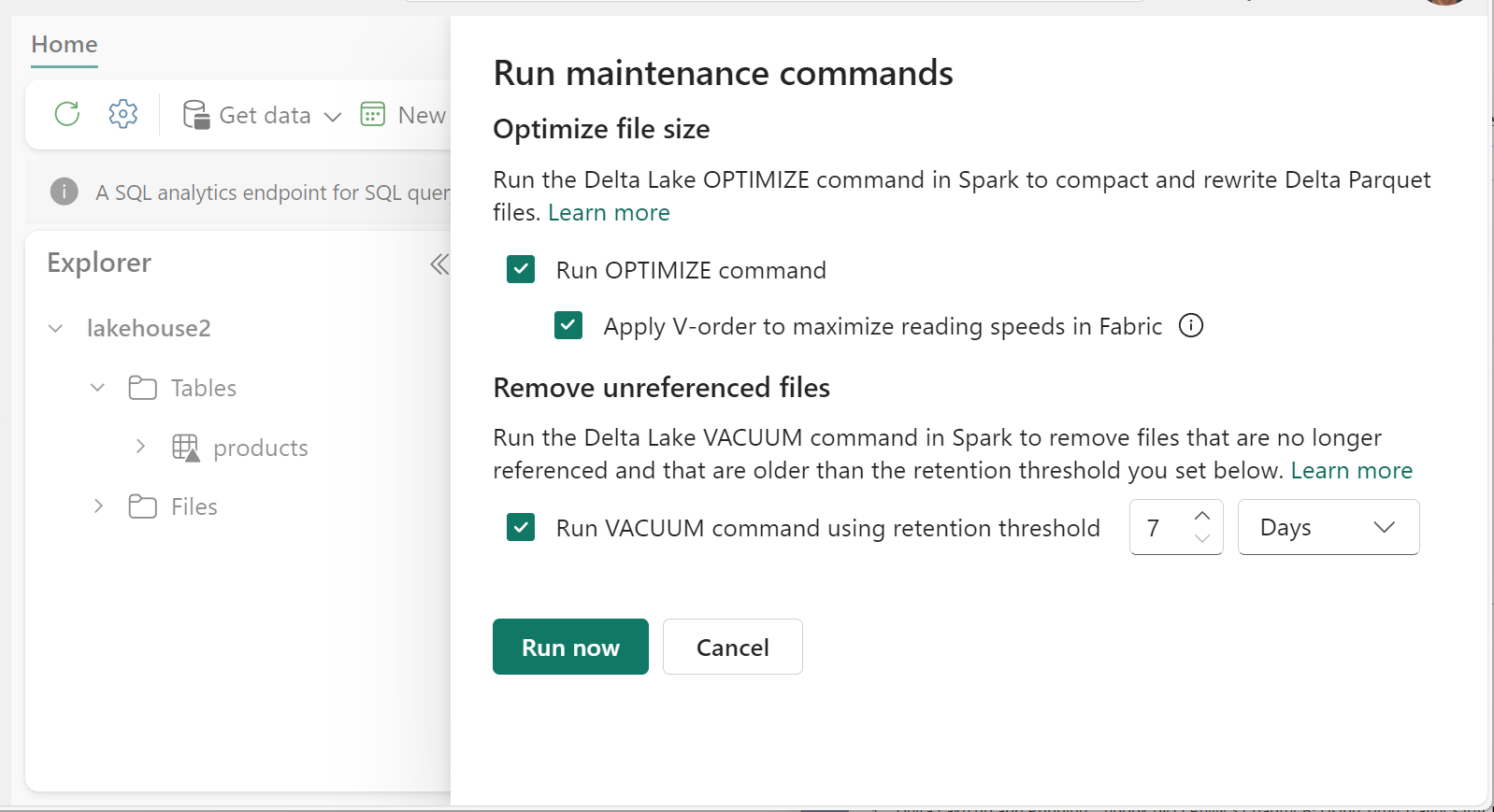
Kör VACUUM på enskilda tabeller med hjälp av funktionen Tabellunderhåll:
- I Lakehouse Explorer väljer du ... bredvid ett tabellnamn och välj Underhåll.
- Välj Kör VACUUM-kommandot med kvarhållningströskelvärdet och ange kvarhållningströskelvärdet.
- Välj kör nu.
Du kan också köra VACUUM som ett SQL-kommando i en notebook-fil:
%%sql
VACUUM lakehouse2.products RETAIN 168 HOURS;
VACUUM checkar in i Delta-transaktionsloggen, så att du kan visa tidigare körningar i BESKRIVA HISTORIK.
%%sql
DESCRIBE HISTORY lakehouse2.products;
Partitionera Delta-tabeller
Med Delta Lake kan du ordna data i partitioner. Detta kan förbättra prestanda genom att aktivera överhoppning av data, vilket ökar prestandan genom att hoppa över irrelevanta dataobjekt baserat på ett objekts metadata.
Tänk dig en situation där stora mängder försäljningsdata lagras. Du kan partitionering försäljningsdata per år. Partitionerna lagras i undermappar med namnet "year=2021", "year=2022" osv. Om du bara vill rapportera försäljningsdata för 2024 kan partitionerna för andra år hoppas över, vilket förbättrar läsprestanda.
Partitionering av små mängder data kan dock försämra prestanda eftersom det ökar antalet filer och kan förvärra problemet med "små filer".
Använd partitionering när:
- Du har mycket stora mängder data.
- Tabeller kan delas upp i några stora partitioner.
Använd inte partitionering när:
- Datavolymerna är små.
- En partitioneringskolumn har hög kardinalitet eftersom det skapar ett stort antal partitioner.
- En partitioneringskolumn skulle resultera i flera nivåer.
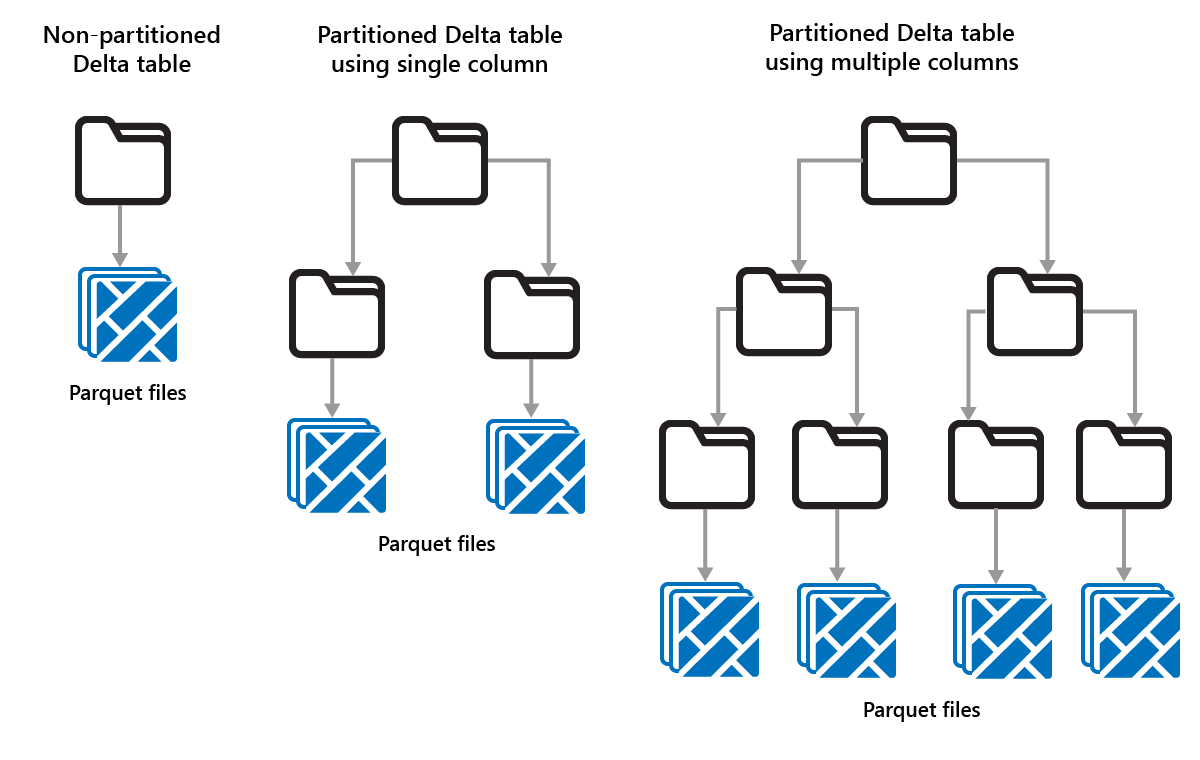
Partitioner är en fast datalayout och anpassas inte till olika frågemönster. När du överväger hur du använder partitionering bör du tänka på hur dina data används och dess kornighet.
I det här exemplet partitioneras en DataFrame som innehåller produktdata efter kategori:
df.write.format("delta").partitionBy("Category").saveAsTable("partitioned_products", path="abfs_path/partitioned_products")
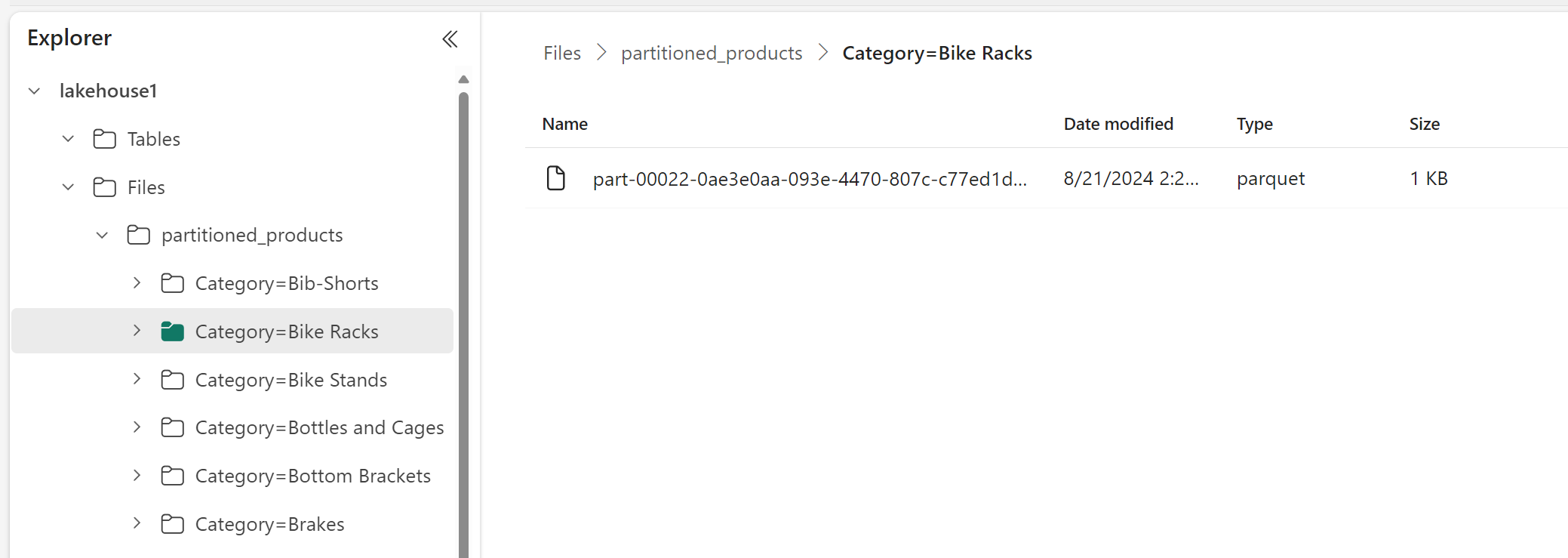
I Lakehouse Explorer kan du se att data är en partitionerad tabell.
- Det finns en mapp för tabellen med namnet "partitioned_products".
- Det finns undermappar för varje kategori, till exempel "Category=Bike Racks" osv.
Vi kan skapa en liknande partitionerad tabell med SQL:
%%sql
CREATE TABLE partitioned_products (
ProductID INTEGER,
ProductName STRING,
Category STRING,
ListPrice DOUBLE
)
PARTITIONED BY (Category);