Förstå Delta Lake
Delta Lake är ett lagringslager med öppen källkod som lägger till relationsdatabassemantik i Spark-baserad datasjöbearbetning. Tabeller i Microsoft Fabric lakehouses är Delta-tabeller, vilket visas av ikonen för triangulärt delta (Δ) på tabeller i lakehouse-användargränssnittet.
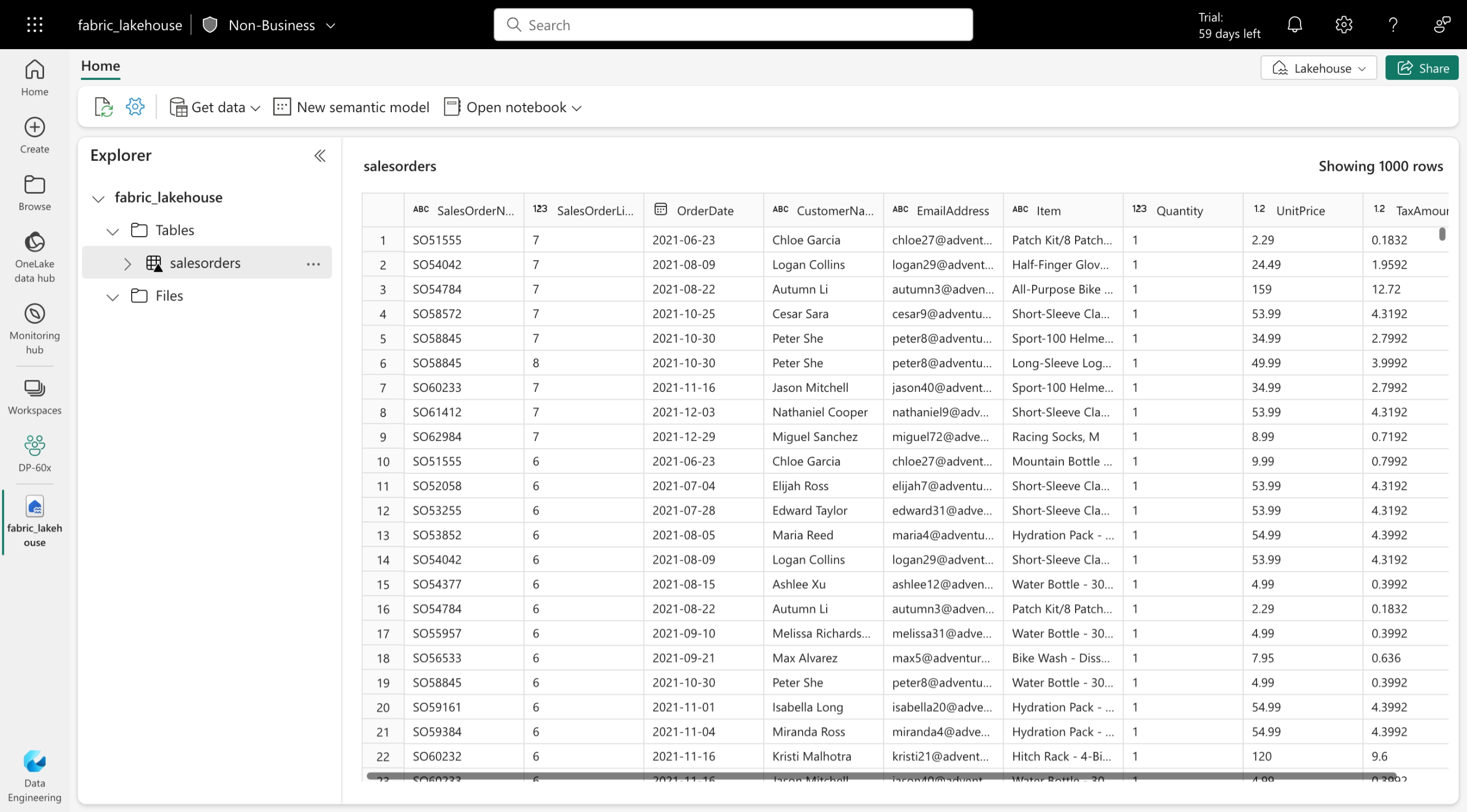
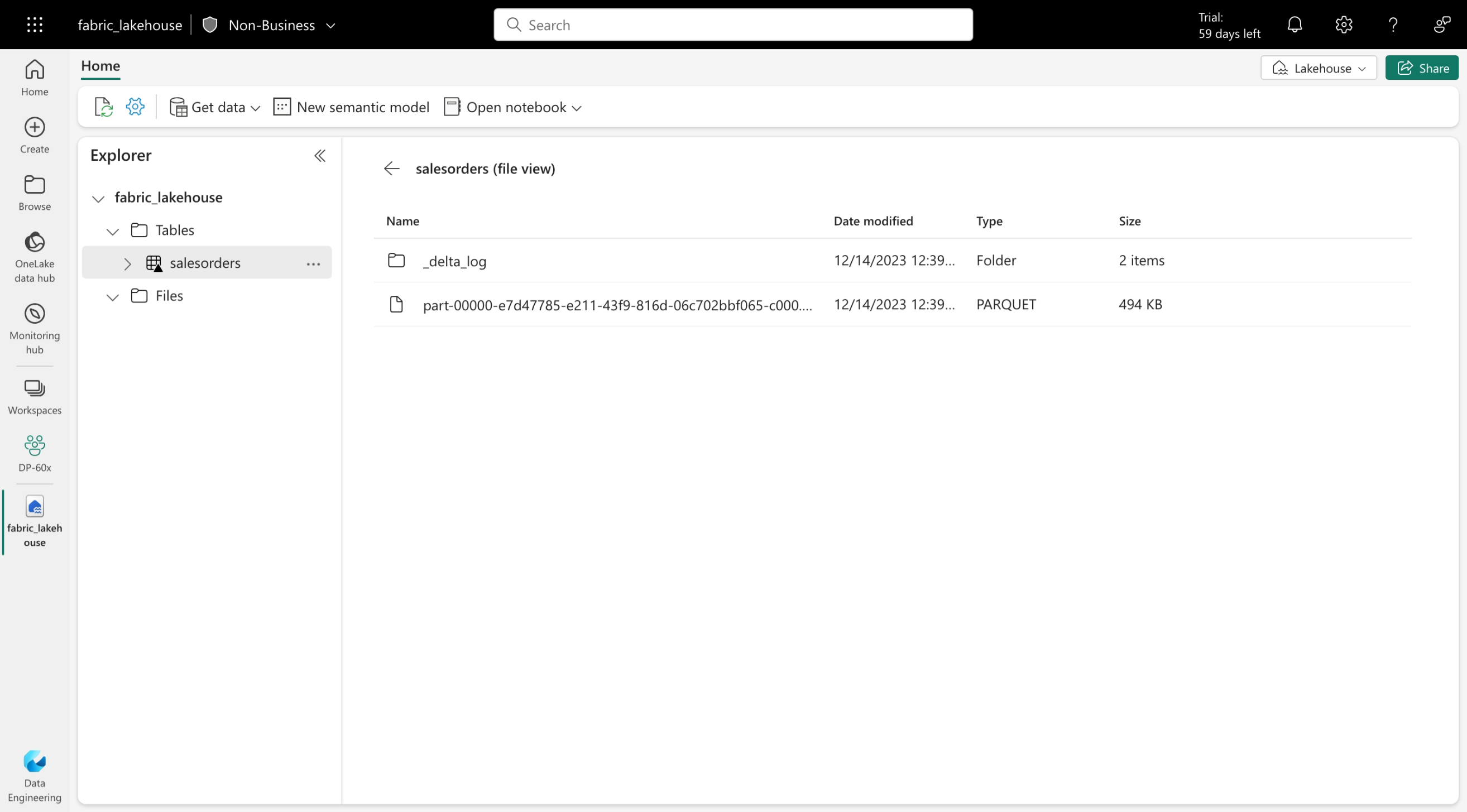
Deltatabeller är schemaabstraktioner över datafiler som lagras i Delta-format. För varje tabell lagrar lakehouse en mapp som innehåller Parquet-datafiler och en _delta_Log mapp där transaktionsinformation loggas i JSON-format.
Fördelarna med att använda Delta-tabeller är:
- Relationstabeller som stöder frågor och dataändringar. Med Apache Spark kan du lagra data i Delta-tabeller som stöder CRUD-åtgärder (skapa, läsa, uppdatera och ta bort). Med andra ord kan du välja, infoga, uppdatera och ta bort rader med data på samma sätt som i ett relationsdatabassystem.
- Stöd för ACID-transaktioner. Relationsdatabaser är utformade för att stödja ändringar av transaktionsdata som ger atomitet (transaktioner slutförs som en enda arbetsenhet), konsekvens (transaktioner lämnar databasen i ett konsekvent tillstånd), isolering (pågående transaktioner kan inte störa varandra) och hållbarhet (när en transaktion slutförs bevaras de ändringar som gjorts). Delta Lake ger samma transaktionsstöd till Spark genom att implementera en transaktionslogg och framtvinga serialiserbar isolering för samtidiga åtgärder.
- Dataversioner och tidsresor. Eftersom alla transaktioner loggas i transaktionsloggen kan du spåra flera versioner av varje tabellrad och till och med använda tidsresefunktionen för att hämta en tidigare version av en rad i en fråga.
- Stöd för batch- och strömmande data. Även om de flesta relationsdatabaser innehåller tabeller som lagrar statiska data, innehåller Spark inbyggt stöd för strömmande data via Spark Structured Streaming-API:et. Delta Lake-tabeller kan användas som både mottagare (mål) och källor för strömmande data.
- Standardformat och samverkan. Underliggande data för Delta-tabeller lagras i Parquet-format, som ofta används i data lake-inmatningspipelines. Dessutom kan du använda SQL-analysslutpunkten för Microsoft Fabric Lakehouse för att fråga Delta-tabeller i SQL.