Utforska Dataflöden Gen2 i Microsoft Fabric
I Microsoft Fabric kan du skapa ett Dataflöde Gen2 i Data Factory-arbetsbelastningen eller Power BI-arbetsytan, eller direkt i lakehouse. Eftersom vårt scenario fokuserar på datainmatning ska vi titta på datafabrikens arbetsbelastningsupplevelse. Dataflöden Gen2 använder Power Query Online för att visualisera transformeringar. Se en översikt över gränssnittet:
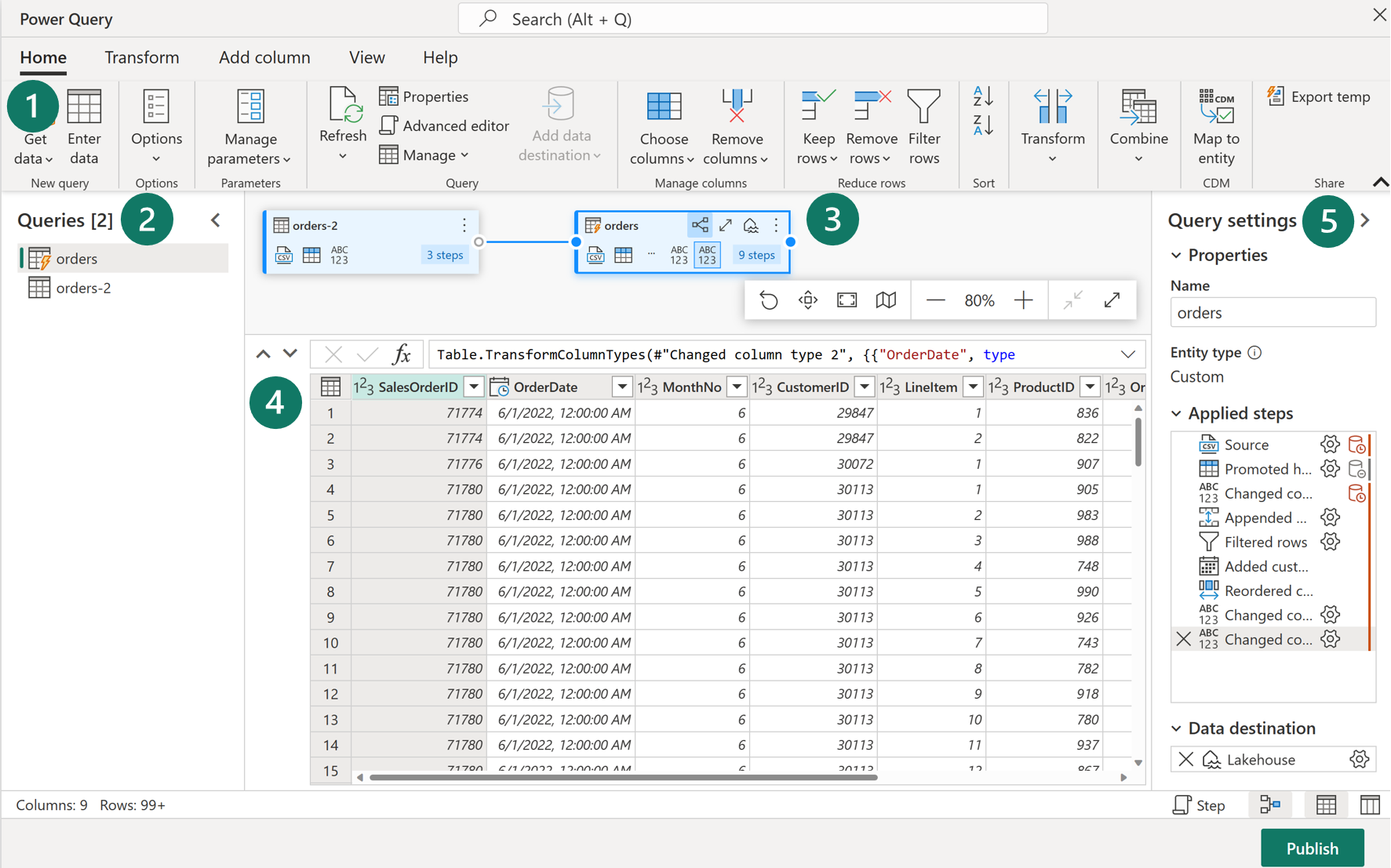
1. Menyfliksområdet Power Query
Dataflöden Gen2 har stöd för en mängd olika anslutningsappar för datakällor. Vanliga källor är molnbaserade och lokala relationsdatabaser, Excel eller flata filer, SharePoint, SalesForce, Spark och Fabric Lakehouses. Sedan finns det många möjliga datatransformeringar, till exempel:
- Filtrera och sortera rader
- Pivot och Unpivot
- Sammanslagnings- och tilläggsfrågor
- Delning och villkorsstyrd delning
- Ersätt värden och Ta bort dubbletter
- Lägg till, byt namn på, ordna om eller ta bort kolumner
- Ranknings- och procentkalkylator
- Välj övre N och nederkant N
Du kan också skapa och hantera datakällanslutningar, hantera parametrar och konfigurera standarddatamålet i det här menyfliksområdet.
2. Fönstret Frågor
Fönstret Frågor visar de olika datakällorna – som nu kallas frågor. Dessa frågor kallas tabeller när de läses in i ditt datalager. Du kan duplicera eller referera till en fråga om du behöver flera kopior av samma data, till exempel skapa ett star-schema och dela upp data i separata, mindre tabeller. Du kan också inaktivera belastningen på en fråga, om du bara behöver en engångsimport.
3. Diagramvy
Med diagramvyn kan du visuellt se hur datakällorna är anslutna och de olika tillämpade omvandlingarna. Ditt dataflöde ansluter till en datakälla, duplicerar frågan, tar bort kolumner från källfrågan och tar sedan bort duplicerade frågor. Varje fråga representeras som en form med alla tillämpade transformeringar och ansluts av en rad för den duplicerade frågan. Du kan aktivera eller inaktivera den här vyn.
4. Fönstret Dataförhandsgranskning
Fönstret Dataförhandsgranskning visar bara en delmängd data så att du kan se vilka transformeringar du ska göra och hur de påverkar data. Du kan också interagera med förhandsgranskningsfönstret genom att dra och släppa kolumner för att ändra ordning eller högerklicka på kolumner för att filtrera eller göra ändringar. Dataförhandsgranskningen visar alla dina transformeringar för den valda frågan.
5. Fönstret Frågeinställningar
Fönstret Frågeinställningar innehåller de tillämpade stegen. Varje transformering representeras som ett steg, varav vissa tillämpas automatiskt när du ansluter datakällan. Beroende på komplexiteten i omvandlingarna kan du ha flera tillämpade steg för varje fråga. De flesta steg har en kugghjulsikon som gör att du kan ändra steget, annars måste du ta bort och upprepa omvandlingen.
Varje steg har också en snabbmeny när du högerklickar så att du kan byta namn på, ändra ordning på eller ta bort stegen. Du kan också visa datakällfrågan när du ansluter till en datakälla som stöder frågedelegering.
Även om det här visuella gränssnittet är användbart kan du också visa M-koden via Avancerad redigerare.
I fönstret Frågeinställningar kan du se ett alternativ för datamål för att landa dina data på någon av följande platser i infrastrukturmiljön:
- Sjöhus
- Distributionslager
- SQL-databas
Du kan också läsa in ditt dataflöde till Azure SQL-databasen, Azure Data Explorer eller Azure Synapse Analytics.
Dataflöden Gen2 tillhandahåller en lösning med låg till ingen kod för att mata in, transformera och läsa in data i dina infrastrukturdatalager. Power BI-utvecklare är bekanta och kan snabbt börja utföra transformeringar uppströms för att förbättra prestanda för sina rapporter.