Transformera datafiler med instruktionen CREATE EXTERNAL TABLE AS SELECT
SQL-språket innehåller många funktioner som gör att du kan manipulera data. Du kan till exempel använda SQL för att:
- Filtrera rader och kolumner i en datauppsättning.
- Byt namn på datafält och konvertera mellan datatyper.
- Beräkna härledda datafält.
- Ändra strängvärden.
- Gruppera och aggregera data.
Azure Synapse-serverlösa SQL-pooler kan användas för att köra SQL-instruktioner som transformerar data och bevarar resultatet som en fil i en datasjö för vidare bearbetning eller frågor. Om du är bekant med Transact-SQL-syntaxen kan du skapa en SELECT-instruktion som tillämpar den specifika transformering som du är intresserad av och lagra resultatet av SELECT-instruktionen i ett valt filformat med ett metadatatabellschema som kan efterfrågas med SQL.
Du kan använda en CETAS-instruktion (CREATE EXTERNAL TABLE AS SELECT) i en dedikerad SQL-pool eller en serverlös SQL-pool för att spara resultatet av en fråga i en extern tabell, som lagrar sina data i en fil i datasjön.
CETAS-instruktionen innehåller en SELECT-instruktion som frågar efter och manipulerar data från en giltig datakälla (som kan vara en befintlig tabell eller vy i en databas eller en OPENROWSET-funktion som läser filbaserade data från datasjön). Resultatet av SELECT-instruktionen sparas sedan i en extern tabell, som är ett metadataobjekt i en databas som tillhandahåller en relationsabstraktion över data som lagras i filer. Följande diagram illustrerar begreppet visuellt:
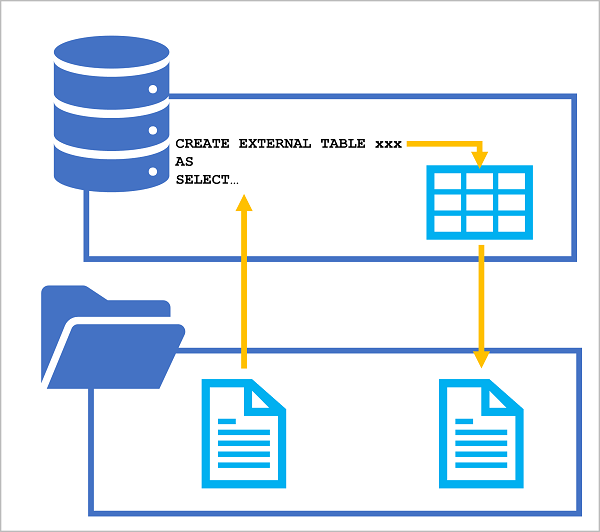
Genom att använda den här tekniken kan du använda SQL för att extrahera och transformera data från filer eller tabeller och lagra transformerade resultat för nedströmsbearbetning eller analys. Efterföljande åtgärder på transformerade data kan utföras mot relationstabellen i SQL-pooldatabasen eller direkt mot de underliggande datafilerna.
Skapa externa databasobjekt för att stödja CETAS
Om du vill använda CETAS-uttryck måste du skapa följande typer av objekt i en databas för antingen en serverlös eller dedikerad SQL-pool. När du använder en serverlös SQL-pool skapar du dessa objekt i en anpassad databas (skapas med instruktionen CREATE DATABASE ), inte den inbyggda databasen.
Extern datakälla
En extern datakälla kapslar in en anslutning till en filsystemplats i en datasjö. Du kan sedan använda den här anslutningen för att ange en relativ sökväg där datafilerna för den externa tabellen som skapas av CETAS-instruktionen sparas.
Om källdata för CETAS-instruktionen finns i filer i samma datasjösökväg kan du använda samma externa datakälla i funktionen OPENROWSET som används för att fråga den. Du kan också skapa en separat extern datakälla för källfilerna eller använda en fullständigt kvalificerad filsökväg i funktionen OPENROWSET.
Om du vill skapa en extern datakälla använder du -instruktionen CREATE EXTERNAL DATA SOURCE , som du ser i det här exemplet:
-- Create an external data source for the Azure storage account
CREATE EXTERNAL DATA SOURCE files
WITH (
LOCATION = 'https://mydatalake.blob.core.windows.net/data/files/',
TYPE = HADOOP, -- For dedicated SQL pool
-- TYPE = BLOB_STORAGE, -- For serverless SQL pool
CREDENTIAL = storageCred
);
I föregående exempel förutsätts att användare som kör frågor som använder den externa datakällan har tillräcklig behörighet för att komma åt filerna. En annan metod är att kapsla in en autentiseringsuppgift i den externa datakällan så att den kan användas för att komma åt fildata utan att ge alla användare behörighet att läsa den direkt:
CREATE DATABASE SCOPED CREDENTIAL storagekeycred
WITH
IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=xxx...';
CREATE EXTERNAL DATA SOURCE secureFiles
WITH (
LOCATION = 'https://mydatalake.blob.core.windows.net/data/secureFiles/'
CREDENTIAL = storagekeycred
);
Dricks
Förutom SAS-autentisering kan du definiera autentiseringsuppgifter som använder hanterad identitet (Microsoft Entra-identiteten som används av din Azure Synapse-arbetsyta), ett specifikt Microsoft Entra-huvudnamn eller genomströmningsautentisering baserat på identiteten för den användare som kör frågan (vilket är standardtypen för autentisering). Mer information om hur du använder autentiseringsuppgifter i en serverlös SQL-pool finns i artikeln Kontrollera åtkomst till lagringskonto för serverlös SQL-pool i Azure Synapse Analytics i Azure Synapse Analytics-dokumentationen.
Externt filformat
CETAS-instruktionen skapar en tabell med sina data lagrade i filer. Du måste ange formatet för de filer som du vill skapa som ett externt filformat.
Om du vill skapa ett externt filformat använder du -instruktionen CREATE EXTERNAL FILE FORMAT , som du ser i det här exemplet:
CREATE EXTERNAL FILE FORMAT ParquetFormat
WITH (
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
);
Dricks
I det här exemplet sparas filerna i Parquet-format. Du kan också skapa externa filformat för andra typer av filer. Mer information finns i SKAPA EXTERNT FILFORMAT (Transact-SQL).
Använda CETAS-instruktionen
När du har skapat en extern datakälla och ett externt filformat kan du använda CETAS-instruktionen för att transformera data och lagra resultatet i en extern tabell.
Anta till exempel att de källdata som du vill transformera består av försäljningsorder i kommaavgränsade textfiler som lagras i en mapp i en datasjö. Du vill filtrera data så att de endast innehåller beställningar som har markerats som "specialordning" och spara transformerade data som Parquet-filer i en annan mapp i samma datasjö. Du kan använda samma externa datakälla för både käll- och målmapparna som du ser i det här exemplet:
CREATE EXTERNAL TABLE SpecialOrders
WITH (
-- details for storing results
LOCATION = 'special_orders/',
DATA_SOURCE = files,
FILE_FORMAT = ParquetFormat
)
AS
SELECT OrderID, CustomerName, OrderTotal
FROM
OPENROWSET(
-- details for reading source files
BULK 'sales_orders/*.csv',
DATA_SOURCE = 'files',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE
) AS source_data
WHERE OrderType = 'Special Order';
Parametrarna LOCATION och BULK i föregående exempel är relativa sökvägar för resultaten respektive källfilerna. Sökvägarna är relativa till den filsystemplats som refereras av filernas externa datakälla.
En viktig punkt att förstå är att du måste använda en extern datakälla för att ange den plats där transformerade data för den externa tabellen ska sparas. När filbaserade källdata lagras i samma mapphierarki kan du använda samma externa datakälla. Annars kan du använda en andra datakälla för att definiera en anslutning till källdata eller använda den fullständigt kvalificerade sökvägen, som du ser i det här exemplet:
CREATE EXTERNAL TABLE SpecialOrders
WITH (
-- details for storing results
LOCATION = 'special_orders/',
DATA_SOURCE = files,
FILE_FORMAT = ParquetFormat
)
AS
SELECT OrderID, CustomerName, OrderTotal
FROM
OPENROWSET(
-- details for reading source files
BULK 'https://mystorage.blob.core.windows.net/data/sales_orders/*.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE
) AS source_data
WHERE OrderType = 'Special Order';
Ta bort externa tabeller
Om du inte längre behöver den externa tabellen som innehåller transformerade data kan du släppa den från databasen med hjälp av -instruktionen DROP EXTERNAL TABLE , som du ser här:
DROP EXTERNAL TABLE SpecialOrders;
Det är dock viktigt att förstå att externa tabeller är en metadataabstraktion över de filer som innehåller faktiska data. Om du tar bort en extern tabell tas inte de underliggande filerna bort.