Utforska lösningsarkitekturen
Innan vi börjar ska vi utforska arkitekturen för att förstå alla krav. Att ta en modell till produktion innebär att du måste skala din lösning och arbeta tillsammans med andra team. Tillsammans med dataexperter, datatekniker och infrastrukturteam har du bestämt dig för att använda följande metod:
- Alla data lagras i en Azure Blob Storage som hanteras av datateknikern.
- Infrastrukturteamet skapar nödvändiga Azure-resurser som Azure Machine Learning-arbetsytan.
- Dataforskaren fokuserar på den inre loopen: utveckla och träna modellen.
- Maskininlärningsteknikern tar den tränade modellen och distribuerar den i den yttre loopen.
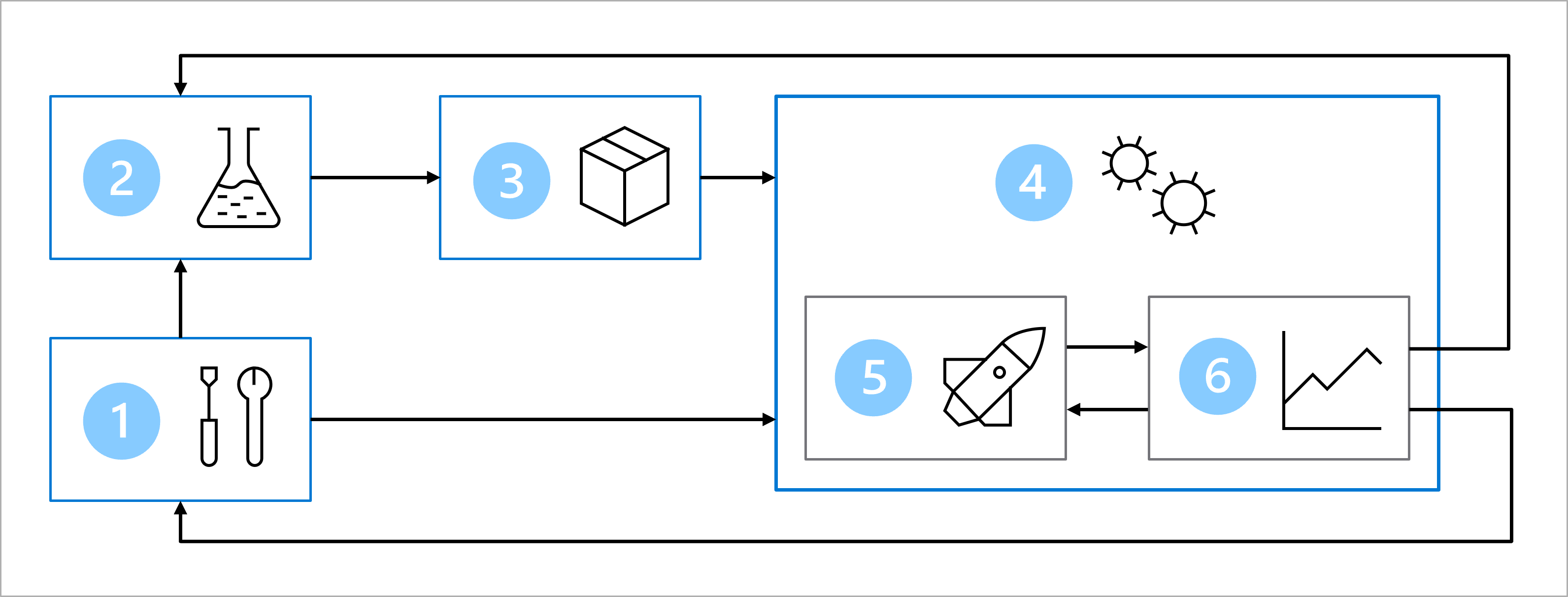
Tillsammans med det större teamet har du utformat en arkitektur för att uppnå maskininlärningsåtgärder (MLOps).
Kommentar
Diagrammet är en förenklad representation av en MLOps-arkitektur. Om du vill visa en mer detaljerad arkitektur kan du utforska de olika användningsfallen i lösningsacceleratorn MLOps (v2).
Huvudmålet med MLOps-arkitekturen är att skapa en robust och reproducerbar lösning. För att uppnå detta omfattar arkitekturen:
- Installation: Skapa alla nödvändiga Azure-resurser för lösningen.
- Modellutveckling (inre loop): Utforska och bearbeta data för att träna och utvärdera modellen.
- Kontinuerlig integrering: Paketera och registrera modellen.
- Modelldistribution (yttre loop): Distribuera modellen.
- Kontinuerlig distribution: Testa modellen och flytta upp till produktionsmiljön.
- Övervakning: Övervaka modell- och slutpunktsprestanda.
Nu i projektet skapas Azure Machine Learning-arbetsytan, data lagras i en Azure Blob Storage och datavetenskapsteamet har tränat modellen.
Du vill flytta från den inre loopen och modellutvecklingen till den yttre loopen genom att distribuera modellen till produktion. Därför måste du konvertera data science-teamets utdata till en robust och reproducerbar pipeline i Azure Machine Learning.
Genom att se till att all kod lagras som skript och köra skripten som Azure Machine Learning-jobb blir det enklare att automatisera modellträningen och träna om modellen i framtiden.
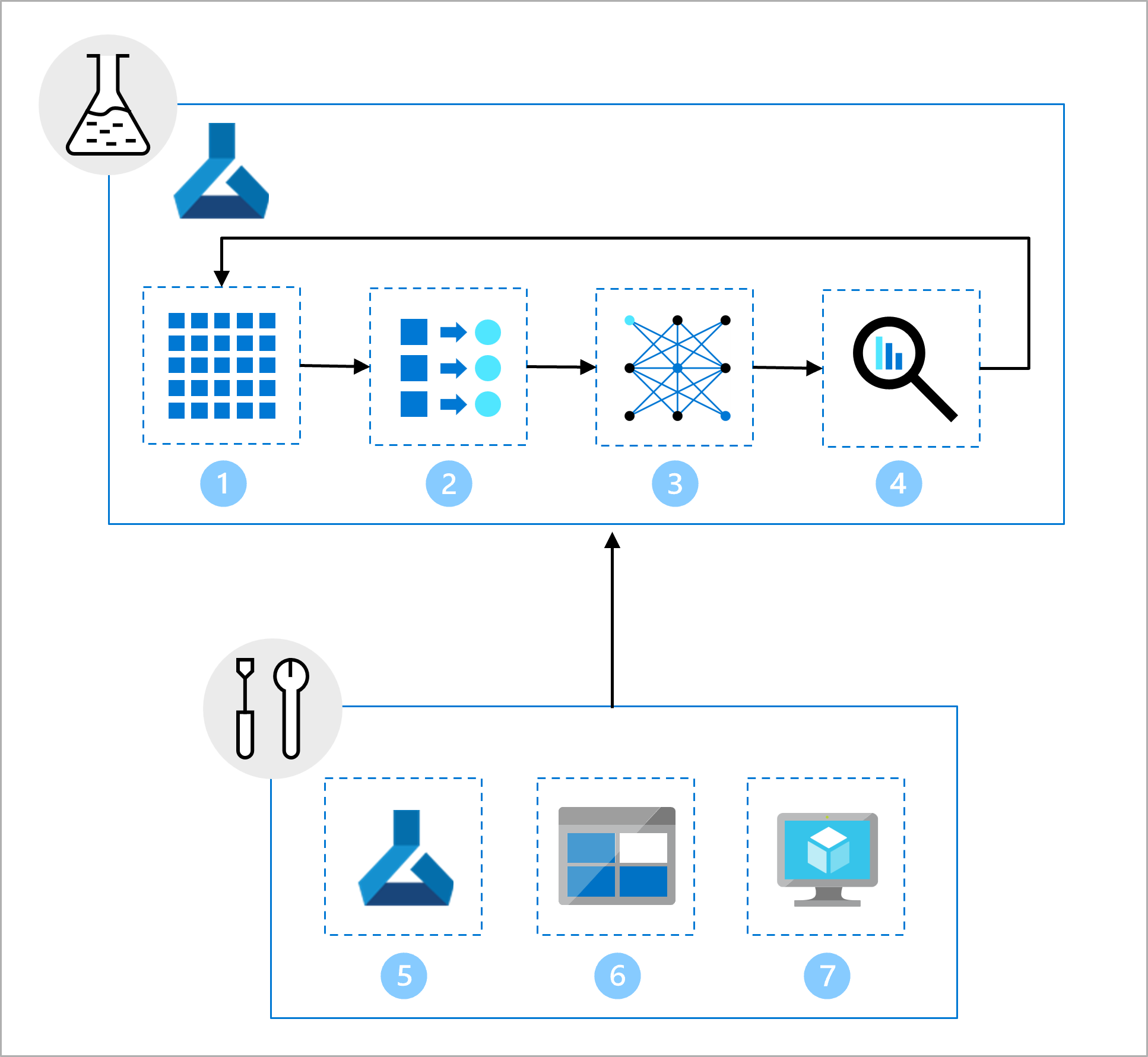
Data science-teamet har arbetat med modellutveckling. De ger dig en Jupyter Notebook, som innehåller följande uppgifter:
- Läsa och utforska data.
- Utföra funktionsframställning.
- Träna modellen.
- Utvärdera modellen.
Som en del av installationen har infrastrukturteamet skapat:
- En arbetsyta för Azure Machine Learning-utveckling (dev) som kan användas av datavetenskapsteamet för utforskning och experimentering.
- En datatillgång på arbetsytan, som refererar till en mapp i Azure Blob Storage som innehåller data.
- Beräkningsresurser som behövs för att köra notebook-filer och skript.
Din första uppgift mot MLOps är att konvertera arbetet från dataexperterna så att du enkelt kan automatisera modellutvecklingen. Data science-teamet arbetade i en Jupyter-anteckningsbok, men du måste använda skript och köra dem med hjälp av Azure Machine Learning-jobb. Indata för jobbet är den datatillgång som skapas av infrastrukturteamet, som pekar på de data som finns på Azure Blob Storage, anslutna till Azure Machine Learning-arbetsytan.