Visualisera data
Ett av de mest intuitiva sätten att analysera resultatet av datafrågor är att visualisera dem som diagram. Notebook-filer i Azure Databricks tillhandahåller diagramfunktioner i användargränssnittet, och när den funktionen inte ger det du behöver kan du använda ett av de många Python-grafikbiblioteken för att skapa och visa datavisualiseringar i notebook-filen.
Använda inbyggda notebook-diagram
När du visar en dataram eller kör en SQL-fråga i en Spark-notebook-fil i Azure Databricks visas resultatet under kodcellen. Som standard återges resultaten som en tabell, men du kan också visa resultatet som en visualisering och anpassa hur diagrammet visar data, som du ser här:
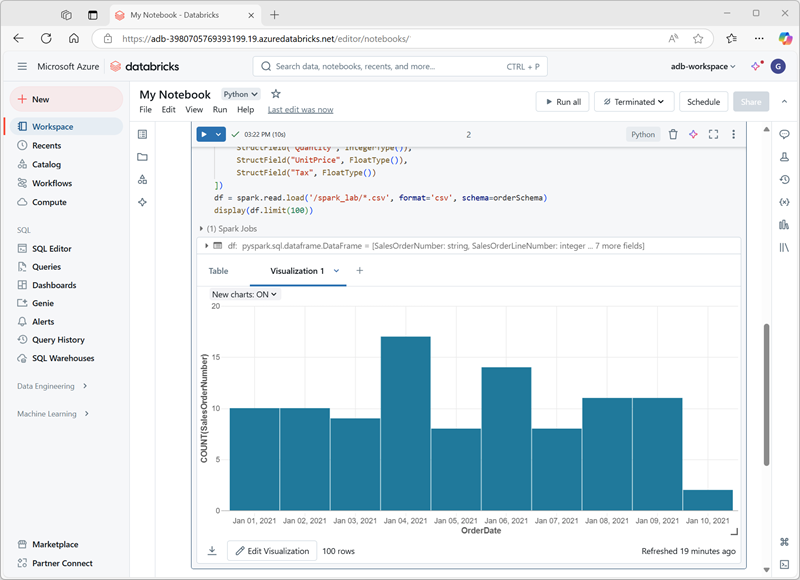
De inbyggda visualiseringsfunktionerna i notebook-filer är användbara när du snabbt vill sammanfatta data visuellt. När du vill ha mer kontroll över hur data formateras eller visa värden som du redan har aggregerat i en fråga bör du överväga att använda ett grafikpaket för att skapa egna visualiseringar.
Använda grafikpaket i kod
Det finns många grafikpaket som du kan använda för att skapa datavisualiseringar i kod. I synnerhet har Python stöd för ett stort urval av paket. de flesta bygger på det grundläggande Matplotlib-biblioteket . Utdata från ett grafikbibliotek kan återges i en notebook-fil, vilket gör det enkelt att kombinera kod för att mata in och manipulera data med infogade datavisualiseringar och markdown-celler för att ge kommentarer.
Du kan till exempel använda följande PySpark-kod för att aggregera data från de hypotetiska produktdata som utforskades tidigare i den här modulen och använda Matplotlib för att skapa ett diagram från aggregerade data.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
Matplotlib-biblioteket kräver att data finns i en Pandas-dataram i stället för en Spark-dataram, så metoden toPandas används för att konvertera den. Koden skapar sedan en bild med en angiven storlek och ritar ett stapeldiagram med en anpassad egenskapskonfiguration innan det resulterande diagrammet visas.
Diagrammet som skapas av koden skulle se ut ungefär så här:
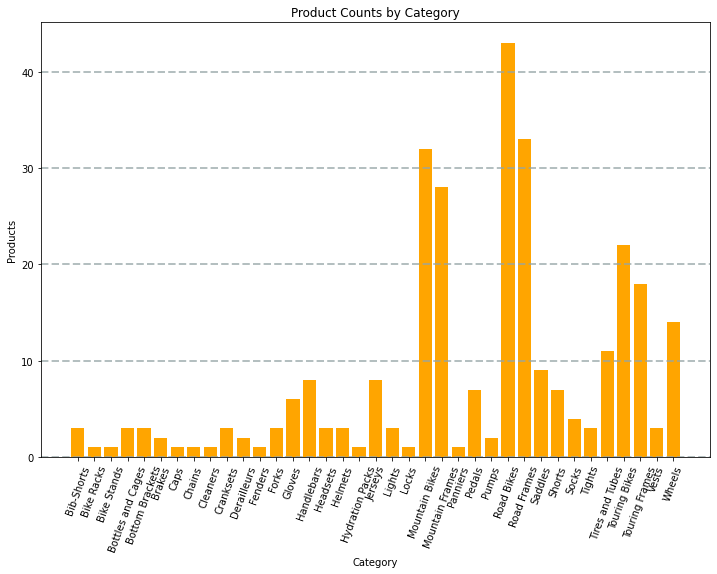
Du kan använda Matplotlib-biblioteket för att skapa många typer av diagram. eller om du vill kan du använda andra bibliotek, till exempel Seaborn , för att skapa mycket anpassade diagram.
Kommentar
Biblioteken Matplotlib och Seaborn kan redan vara installerade i Databricks-kluster, beroende på Databricks Runtime för klustret. Om inte, eller om du vill använda ett annat bibliotek som inte redan är installerat, kan du lägga till det i klustret. Mer information finns i Klusterbibliotek i Azure Databricks-dokumentationen.