Skapa ett Spark-kluster
Du kan skapa ett eller flera kluster på din Azure Databricks-arbetsyta med hjälp av Azure Databricks-portalen.
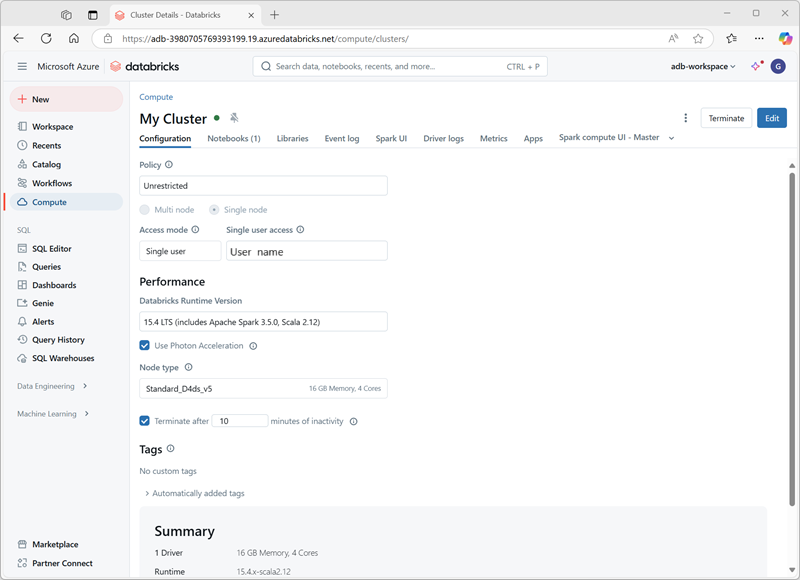
När du skapar klustret kan du ange konfigurationsinställningar, inklusive:
- Ett namn på klustret.
- Ett klusterläge, som kan vara:
- Standard: Lämplig för arbetsbelastningar med en användare som kräver flera arbetsnoder.
- Hög samtidighet: Lämplig för arbetsbelastningar där flera användare använder klustret samtidigt.
- Enskild nod: Lämplig för små arbetsbelastningar eller testning, där endast en enda arbetsnod krävs.
- Den version av Databricks Runtime som ska användas i klustret, som avgör vilken version av Spark och enskilda komponenter som Python, Scala och andra som installeras.
- Den typ av virtuell dator (VM) som används för arbetsnoderna i klustret.
- Det minsta och högsta antalet arbetsnoder i klustret.
- Den typ av virtuell dator som används för drivrutinsnoden i klustret.
- Om klustret stöder autoskalning för att dynamiskt ändra storlek på klustret.
- Hur länge klustret kan vara inaktivt innan det stängs av automatiskt.
Så hanterar Azure klusterresurser
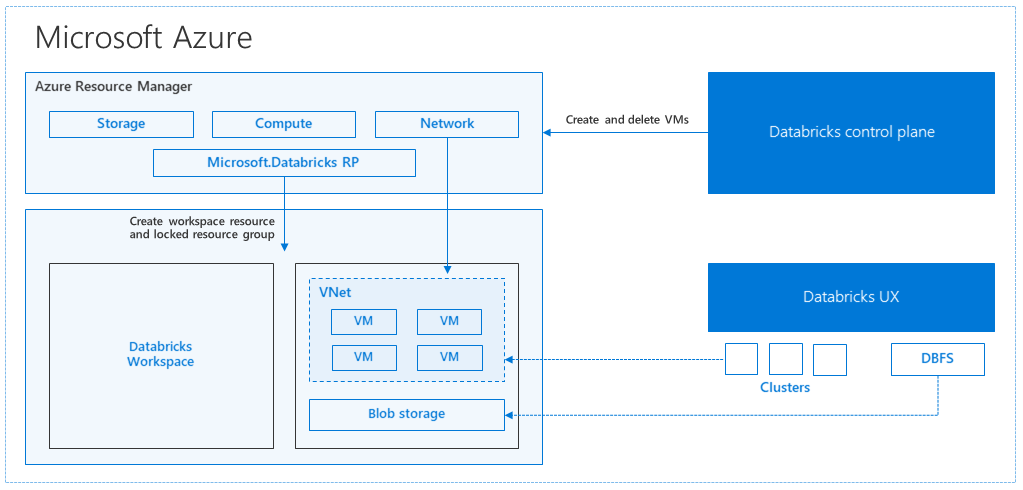
När du skapar en Azure Databricks-arbetsyta distribueras en Databricks-installation som en Azure-resurs i din prenumeration. När du skapar ett kluster på arbetsytan anger du de typer och storlekar på de virtuella datorer som ska användas för både drivrutins- och arbetsnoderna och några andra konfigurationsalternativ, men Azure Databricks hanterar alla andra aspekter av klustret.
Databricks-installationen distribueras till Azure som en hanterad resursgrupp i din prenumeration. Den här resursgruppen innehåller drivrutinen och de virtuella arbetsdatorerna för dina kluster, tillsammans med andra nödvändiga resurser, inklusive ett virtuellt nätverk, en säkerhetsgrupp och ett lagringskonto. Alla metadata för klustret, till exempel schemalagda jobb, lagras i en Azure Database med geo-replikering för feltolerans.
Internt används Azure Kubernetes Service (AKS) för att köra Kontrollplan och dataplan i Azure Databricks via containrar som körs på den senaste generationens Azure-maskinvara (virtuella Dv3-datorer), med NvMe SSD:er som kan ge 100us svarstid på högpresterande virtuella Azure-datorer med accelererat nätverk. Azure Databricks använder dessa funktioner i Azure för att ytterligare förbättra Spark-prestanda. När tjänsterna i din hanterade resursgrupp är klara kan du hantera Databricks-klustret via Azure Databricks-användargränssnittet och via funktioner som automatisk skalning och automatisk avslutning.
Kommentar
Du kan också koppla klustret till en pool med inaktiva noder för att minska starttiden för klustret. Mer information finns i Pooler i Azure Databricks-dokumentationen.