Lär känna Spark
För att få en bättre förståelse för hur du bearbetar och analyserar data med Apache Spark i Azure Databricks är det viktigt att förstå den underliggande arkitekturen.
Översikt på hög nivå
På hög nivå startar och hanterar Azure Databricks-tjänsten Apache Spark-kluster i din Azure-prenumeration. Apache Spark-kluster är grupper av datorer som behandlas som en enda dator och hanterar körningen av kommandon som utfärdas från notebook-filer. Kluster gör det möjligt att parallellisera data mellan många datorer för att förbättra skalning och prestanda. De består av en Spark-drivrutin och arbetsnoder. Drivrutinsnoden skickar arbete till arbetsnoderna och instruerar dem att hämta data från en angiven datakälla.
I Databricks är notebook-gränssnittet vanligtvis drivrutinsprogrammet. Det här drivrutinsprogrammet innehåller huvudloopen för programmet och skapar distribuerade datauppsättningar i klustret och tillämpar sedan åtgärder på dessa datauppsättningar. Drivrutinsprogram får åtkomst till Apache Spark via ett SparkSession-objekt oavsett distributionsplats.
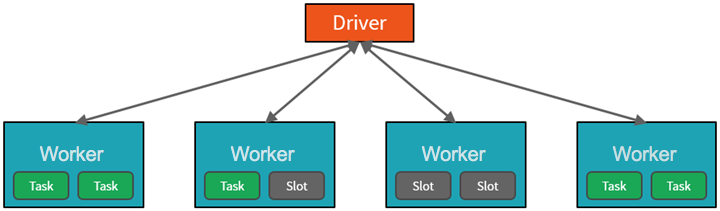
Microsoft Azure hanterar klustret och skalar det automatiskt efter behov baserat på din användning och den inställning som används när klustret konfigureras. Automatisk avslutning kan också aktiveras, vilket gör att Azure kan avsluta klustret efter ett angivet antal minuters inaktivitet.
Spark-jobb i detalj
Arbetet som skickas till klustret delas upp i så många oberoende jobb som behövs. Så här distribueras arbetet mellan klustrets noder. Jobb delas in ytterligare i aktiviteter. Indata till ett jobb partitioneras i en eller flera partitioner. Dessa partitioner är arbetsenheten för varje fack. Mellan aktiviteter kan partitioner behöva omorganiseras och delas över nätverket.
Hemligheten med Sparks höga prestanda är parallellitet. Skalning lodrätt (genom att lägga till resurser på en enda dator) begränsas till en begränsad mängd RAM-minne, trådar och PROCESSORhastigheter, men kluster skalas horisontellt och lägger till nya noder i klustret efter behov.
Spark parallelliserar jobb på två nivåer:
- Den första nivån av parallellisering är kören – en virtuell Java-dator (JVM) som körs på en arbetsnod, vanligtvis en instans per nod.
- Den andra nivån av parallellisering är facket – vars antal bestäms av antalet kärnor och processorer för varje nod.
- Varje köre har flera platser som parallelliserade uppgifter kan tilldelas till.
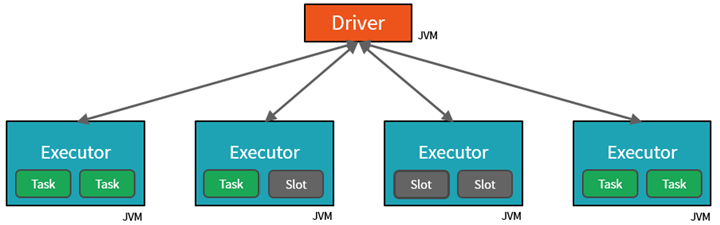
JVM är naturligt flertrådad, men en enda JVM, till exempel den som samordnar arbetet på drivrutinen, har en begränsad övre gräns. Genom att dela upp arbetet i uppgifter kan drivrutinen tilldela arbetsenheter till *fack i körarna på arbetsnoder för parallell körning. Dessutom avgör drivrutinen hur data partitioneras så att de kan distribueras för parallell bearbetning. Drivrutinen tilldelar därför en partition av data till varje uppgift så att varje uppgift vet vilken datadel den ska bearbeta. När den har startats hämtar varje uppgift partitionen med data som tilldelats den.
Jobb och faser
Beroende på vilket arbete som utförs kan flera parallelliserade jobb krävas. Varje jobb är uppdelat i steg. En användbar analogi är att föreställa sig att jobbet är att bygga ett hus:
- Det första steget skulle vara att lägga grunden.
- Det andra steget skulle vara att resa väggarna.
- Det tredje steget skulle vara att lägga till taket.
Att försöka göra något av dessa steg i fel ordning är helt enkelt inte meningsfullt, och kan i själva verket vara omöjligt. På samma sätt delar Spark upp varje jobb i faser för att säkerställa att allt görs i rätt ordning.
Modularitet
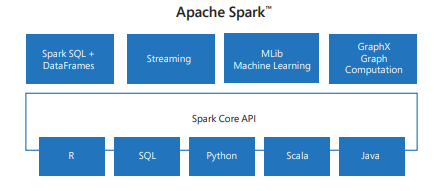
Spark innehåller bibliotek för uppgifter som sträcker sig från SQL till direktuppspelning och maskininlärning, vilket gör det till ett verktyg för databearbetningsuppgifter. Några av Spark-biblioteken är:
- Spark SQL: För att arbeta med strukturerade data.
- SparkML: För maskininlärning.
- GraphX: För grafbearbetning.
- Spark-direktuppspelning: För databearbetning i realtid.
Kompatibilitet
Spark kan köras på en mängd olika distribuerade system, inklusive Hadoop YARN, Apache Mesos, Kubernetes eller Sparks egen klusterhanterare. Den läser också från och skriver till olika datakällor som HDFS, Cassandra, HBase och Amazon S3.