Flera linjär regression och R-kvadrat
I den här lektionen kontrasterar vi flera linjära regressioner med enkel linjär regression. Vi tittar också på ett mått som kallas R2, som ofta används för att utvärdera kvaliteten på en linjär regressionsmodell.
Multipel linjär regression
Flera linjära regressionsmodeller relationen mellan flera funktioner och en enda variabel. Matematiskt sett är det samma som enkel linjär regression och passar vanligtvis med samma kostnadsfunktion, men med fler funktioner.
I stället för att modellera en enda relation modellerar den här tekniken flera relationer samtidigt, som den behandlar som oberoende av varandra. Om vi till exempel förutsäger hur sjuk en hund blir baserat på deras ålder och body_fat_percentage, hittas två relationer:
- Hur ålder ökar eller minskar sjukdom
- Hur body_fat_percentage ökar eller minskar sjukdom
Om vi bara arbetar med två funktioner kan vi visualisera vår modell som ett plan – en platt 2D-yta – precis som vi kan modellera enkel linjär regression som en linje. Vi ska utforska detta i nästa övning.
Flera linjär regression har antaganden
Det faktum att modellen förväntar sig att funktioner ska vara oberoende kallas ett modellantagande. När modellantaganden inte är sanna kan modellen göra vilseledande förutsägelser.
Till exempel förutsäger ålder förmodligen hur sjuka hundar blir, när äldre hundar blir mer sjuka, tillsammans med om hundar har fått lära sig att spela frisbee; äldre hundar vet förmodligen alla hur man spelar frisbee. Om vi inkluderade ålder och knows_frisbee till vår modell som funktioner, skulle det sannolikt berätta för oss knows_frisbee är en bra förutsägelse av en sjukdom och underskattar ålderns betydelse. Detta är lite absurt, för att veta frisbee kommer sannolikt inte att orsaka sjukdom. Däremot kan dog_breed också vara en bra prediktor för sjukdom, men det finns ingen anledning att tro att ålder förutsäger dog_breed, så det skulle vara säkert att inkludera båda i en modell.
Godhet i passform: R2
Vi vet att kostnadsfunktioner kan användas för att utvärdera hur väl en modell passar de data som den tränas på. Linjära regressionsmodeller har ett särskilt relaterat mått som kallas R2 (R-kvadrat). R2 är ett värde mellan 0 och 1 som visar hur väl en linjär regressionsmodell passar data. När folk talar om korrelationer som är starka, betyder de ofta att R2-värdet var stort.
R2 använder matematik utöver vad vi tänker gå in på i den här kursen, men vi kan tänka på det intuitivt. Låt oss ta en titt på föregående övning, där vi tittade på relationen mellan ålder och core_temperature. En R2 av 1 skulle innebära att år kan användas för att perfekt förutsäga vem som hade en hög temperatur och vem som hade en låg temperatur. Däremot skulle en 0 innebära att det helt enkelt inte fanns något samband mellan år och temperatur.
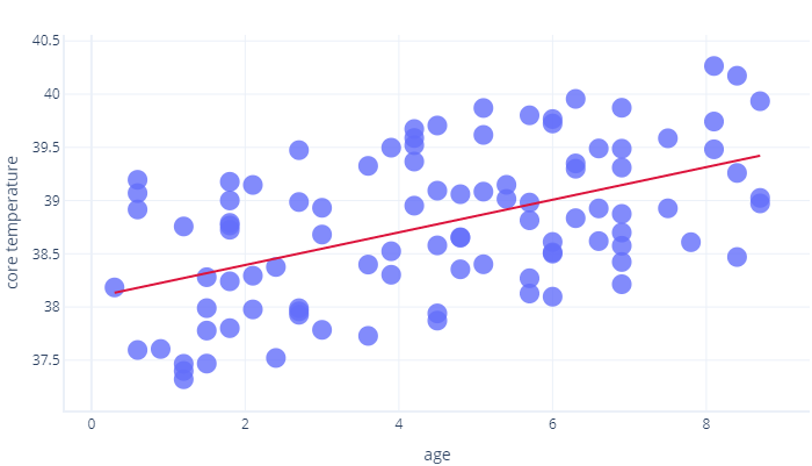
Verkligheten är någonstans däremellan. Vår modell kan förutsäga temperatur till viss grad (så det är bättre än R2 = 0), men punkterna varierade från den här förutsägelsen något (så det är mindre än R2 = 1).
R2 är bara halva historien.
R2-värden är allmänt accepterade, men är inte ett perfekt mått som vi kan använda isolerat. De har fyra begränsningar:
- På grund av hur R2 beräknas, desto fler exempel har vi, desto högre är R2. Detta kan leda oss till att tro att en modell är bättre än en annan (identisk) modell, helt enkelt för att R2-värden beräknades med olika mängder data.
- R2-värden visar inte hur bra en modell fungerar med nya, tidigare osedda data. Statistiker övervinner detta genom att beräkna ett tilläggsmått, kallat p-värde, som vi inte kommer att ta upp här. Inom maskininlärning testar vi ofta uttryckligen vår modell på en annan datauppsättning i stället.
- R2-värden anger inte relationens riktning. Ett R2-värde på 0,8 anger till exempel inte om linjen är lutad uppåt eller nedåt. Det visar inte heller hur sluttande linjen är.
Det är också värt att komma ihåg att det inte finns några universella kriterier för vad som gör ett R2-värde "tillräckligt bra". I de flesta fysiker är det till exempel osannolikt att korrelationer som inte är särskilt nära 1 anses vara användbara, men när du modellerar komplexa system kan R2-värden så låga som 0,3 anses vara utmärkta.