Utvärdera en klassificeringsmodell
En stor del av maskininlärning handlar om att utvärdera hur väl modeller fungerar. Den här utvärderingen sker under träning, för att hjälpa till att forma modellen och efter träningen, för att hjälpa oss att bedöma om modellen är OK att använda i den verkliga världen. Klassificeringsmodeller behöver utvärdering, precis som regressionsmodeller, men sättet vi gör den här utvärderingen på kan ibland vara lite mer komplext.
En uppdatering av kostnaden
Kom ihåg att vi under träningen beräknar hur dåligt en modell presterar och kallar detta kostnad, eller förlust. I linjär regressionen använder vi till exempel ofta ett mått som kallas MSE (mean-squared error). MSE beräknas genom att jämföra förutsägelsen och den faktiska etiketten, jämföra skillnaden och ta medelvärdet av resultatet. Vi kan använda MSE för att passa vår modell och rapportera hur bra den fungerar.
Kostnadsfunktioner för klassificering
Klassificeringsmodeller bedöms antingen utifrån deras utdataannolikheter, till exempel 40% risk för en lavin eller slutetiketter–no avalanche eller avalanche. Det kan vara fördelaktigt att använda utdatans sannolikheter under träningen. Små ändringar i modellen återspeglas i förändringar i sannolikheter, även om de inte räcker för att ändra det slutliga beslutet. Det är mer användbart att använda de slutliga etiketterna för en kostnadsfunktion om vi vill uppskatta modellens verkliga prestanda. Till exempel på testuppsättningen. För verklig användning använder vi de slutliga etiketterna, inte sannolikheterna.
Loggförlust
Loggförlust är en av de mest populära kostnadsfunktionerna för enkel klassificering. Loggförlust tillämpas på utdataannolikheter. På samma sätt som med MSE resulterar små mängder fel i små kostnader, medan måttliga felmängder resulterar i stora kostnader. Vi ritar loggförlust i följande diagram för en etikett där rätt svar var 0 (falskt).
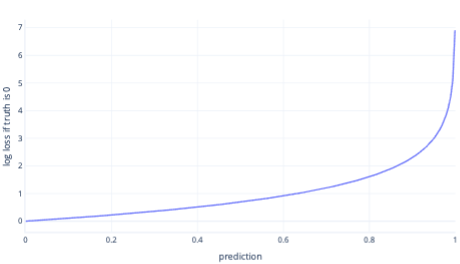
X-axeln visar möjliga modellutdata – sannolikheter från 0 till 1 – och y-axeln visar kostnaden. Om en modell har hög förtroende för att rätt svar är 0 (till exempel förutsäga 0,1). Sedan är kostnaden låg eftersom i den här instansen är rätt svar 0. Om modellen på ett säkert sätt förutsäger resultatet felaktigt (till exempel förutsäga 0,9) blir kostnaden hög. Faktum är att vid x = 1 är kostnaden så hög att vi beskär x-axeln här till 0,999 för att hålla grafen läsbar.
Varför inte MSE?
MSE och loggförlust är liknande mått. Det finns några komplexa orsaker till varför loggförlust gynnas av logistisk regression, men även några enklare orsaker. Till exempel, logaritmisk förlust straffar felaktiga svar mycket hårdare än MSE. I följande diagram, där rätt svar är 0, har förutsägelser över 0,8 till exempel en högre kostnad för loggförlust än MSE.
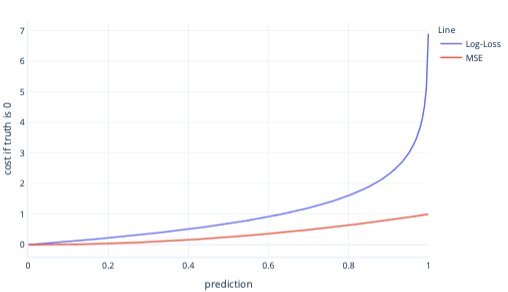
Att ha högre kostnader på det här sättet hjälper modellen att lära sig snabbare på grund av linjens brantare lutning. På samma sätt hjälper loggförlust modeller att bli mer säkra på att ge rätt svar. Observera i föregående diagram att MSE-kostnaden för värden som är mindre än 0,2 är små och att gradienten är nästan platt. Relationen gör att träningen går långsamt för modeller som är nära att vara korrekta. Loggförlust har en brantare lutning för dessa värden, vilket hjälper modellen att lära sig snabbare.
Begränsningar för kostnadsfunktioner
Användning av en enda kostnadsfunktion för mänsklig utvärdering av modellen är alltid begränsad eftersom den inte talar om för dig vilken typ av misstag din modell gör. Tänk till exempel på vårt scenario för lavinförutsägelse. Ett högt loggförlustvärde kan innebära att modellen upprepade gånger förutsäger laviner när det inte finns några. Eller så kan det innebära att det upprepade gånger misslyckas med att förutsäga laviner som inträffar.
För att förstå våra modeller bättre kan det vara enklare att använda mer än ett tal för att bedöma om de fungerar bra. Vi tar upp detta större ämne i annat inlärningsmaterial, även om vi berör det i följande övningar.