Vad är klassificeringsmodeller?
Klassificeringsmodeller används för att fatta beslut eller tilldela objekt till kategorier. Till skillnad från regressionsmoduler, som matar ut kontinuerliga tal, till exempel höjder eller vikter, matar klassificeringsmodeller ut booleska värden – antingen true eller false– eller kategoriska beslut, till exempel apple, bananaeller cherry.
Det finns många typer av klassificeringsmodeller. Vissa fungerar på samma sätt som klassiska regressionsmodeller, medan andra skiljer sig i grunden. En av de bästa modellerna att lära sig från början kallas logistisk regression.
Vad är logistisk regression?
Logistisk regression är en typ av klassificering modell som fungerar på samma sätt som linjär regression. Skillnaden mellan den här och den linjära regressionen är kurvans form. Medan enkel linjär regression passar en rak linje till data, passar logistiska regressionsmodeller en s-formad kurva:

Logistisk regression är bättre för att uppskatta booleska utfall än linjär regression eftersom logistikkurvan alltid genererar ett värde mellan 0 (falskt) och 1 (sant). Allt mellan dessa två värden kan betraktas som en sannolikhet.
Anta till exempel att vi försöker förutsäga om en lavin kan inträffa i dag. Om vår logistiska regressionsmodell ger oss värdet 0,3 uppskattar den att det finns 30% sannolikheten för en lavin.
Konvertera utdata till kategorier
Eftersom logistisk regression ger oss dessa sannolikheter, snarare än enkla sanna/falska värden, måste vi vidta extra åtgärder för att konvertera resultatet till en kategori. Det enklaste sättet att göra den här konverteringen är att tillämpa ett tröskelvärde. I följande diagram anges till exempel vårt tröskelvärde till 0,5. Det här tröskelvärdet innebär att alla y-värden under 0,5 konverteras till false – vänster nedre ruta – och alla värden över 0,5 konverteras till true – höger översta rutan.
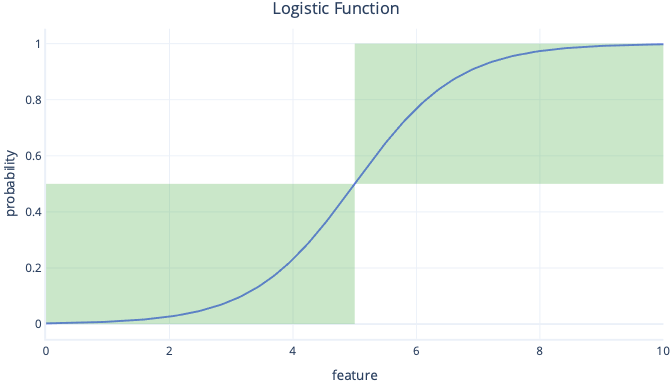
När vi tittar på diagrammet kan vi se att när funktionen är under 5 är sannolikheten mindre än 0,5 och konverteras till false. Funktionsvärden som är över 5 ger sannolikheter över 0,5 och konverteras till sant.
Det är anmärkningsvärt att logistisk regression inte behöver begränsas till ett sant/falskt utfall – det kan också användas där det finns tre eller fler potentiella utfall, till exempel rain, snoweller sun. Den här typen av resultat kräver en något mer komplex konfiguration, som kallas multinom logistisk regression. Även om vi inte övar multinom logistisk regression under de kommande övningarna är det värt att överväga i situationer där du behöver göra förutsägelser som inte är binära.
Det är också värt att notera att logistisk regression kan använda mer än en indatafunktion: mer om det här fallet snart.