Felsök ett nätverk genom att använda metrik och loggar i Network Watcher.
Om du snabbt vill diagnostisera ett problem måste du förstå den information som är tillgänglig i Azure Network Watcher-loggarna.
I ditt ingenjörsföretag vill du minimera den tid det tar för personalen att diagnostisera och lösa eventuella problem med nätverkskonfigurationen. Du vill se till att de vet vilken information som är tillgänglig i vilka loggar.
I den här modulen fokuserar du på flödesloggar, diagnostikloggar och trafikanalys. Du får lära dig hur de här verktygen kan hjälpa dig att felsöka Azure-nätverket.
Användning och kvoter
Du kan använda varje Microsoft Azure-resurs upp till dess kvot. Varje prenumeration har separata kvoter och användningen spåras per prenumeration. Endast en instans av Network Watcher krävs per prenumeration per region. Den här instansen ger dig en vy över användning och kvoter så att du kan se om du riskerar att nå en kvot.
Om du vill visa användnings- och kvotinformationen går du till Alla tjänster>Nätverk>Network Watcheroch väljer sedan Användning och kvoter. Du ser detaljerade data baserat på användning och resursplats. Data för följande mått samlas in:
- Nätverksgränssnitt
- Nätverkssäkerhetsgrupper (NSG:er)
- Virtuella nätverk
- Offentliga IP-adresser
Här är ett exempel som visar användning och kvoter i portalen:

Loggar
Nätverksdiagnostikloggar tillhandahåller detaljerade data. Du kommer att använda dessa data för att bättre förstå anslutningsproblem och prestandaproblem. Det finns tre loggvisningsverktyg i Network Watcher:
- NSG-flödesloggar
- Diagnostikloggar
- Trafikanalys
Nu ska vi titta på vart och ett av dessa verktyg.
NSG-flödesloggar
I NSG-flödesloggar kan du visa information om inkommande och utgående IP-trafik i nätverkssäkerhetsgrupper. Flödesloggar visar utgående och inkommande flöden per regel, baserat på det nätverkskort som flödet gäller. NSG-flödesloggar visar om trafik tilläts eller nekades baserat på 5-tuppelns information som samlats in. Den här informationen omfattar:
- Käll-IP
- Ursprungsport
- Mål-IP
- Målport
- Protokoll
Det här diagrammet visar arbetsflödet som NSG följer.
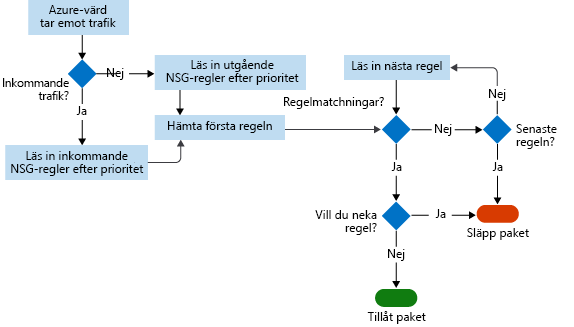
Flödesloggar lagrar data i en JSON-fil. Det kan vara svårt att få insikter om dessa data genom att manuellt söka i loggfilerna, särskilt om du har en stor infrastrukturdistribution i Azure. Lös problemet genom att använda Power BI.
I Power BI kan du visualisera NSG-flödesloggar på många sätt. Till exempel:
- De främsta talarna (IP-adress)
- Flöden efter riktning (inkommande och utgående)
- Flöden efter beslut (godkända och avvisade)
- Flöden efter målport
Du kan också använda verktyg med öppen källkod för att analysera dina loggar, till exempel Elastic Stack, Grafana och Graylog.
Not
NSG-flödesloggar stöder inte lagringskonton på den klassiska Azure-portalen.
Diagnostikloggar
I Network Watcher är diagnostikloggar en central plats för att aktivera och inaktivera loggar för Azure-nätverksresurser. Dessa resurser kan omfatta NSG:er, offentliga IP-adresser, lastbalanserare och appgatewayer. När du har aktiverat loggarna som intresserar dig kan du använda verktygen för att fråga efter och visa loggposter.
Du kan importera diagnostikloggar till Power BI och andra verktyg för att analysera dem.
Trafikanalys
Om du vill undersöka användar- och appaktivitet i dina molnnätverk använder du trafikanalys.
Verktyget ger insikter om nätverksaktivitet i olika prenumerationer. Du kan diagnostisera säkerhetshot som öppna portar, virtuella datorer som kommunicerar med kända dåliga nätverk och trafikflödesmönster. Trafikanalys analyserar NSG-flödesloggar i Azure-regioner och prenumerationer. Du kan använda data för att optimera nätverksprestanda.
Det här verktyget kräver Log Analytics. Log Analytics-arbetsytan måste finnas i en region som stöds.
Användningsfallsscenarier
Nu ska vi titta på några användningsfall där Azure Network Watchers mått och loggar kan vara till hjälp.
Kundrapporter om långsamma prestanda
För att lösa långsam prestanda måste du fastställa den bakomliggande orsaken till problemet.
- Är det för mycket trafik som begränsar servern?
- Är VM-storleken lämplig för jobbet?
- Har skalbarhetströsklarna angetts på rätt sätt?
- Sker några skadliga attacker?
- Är vm-lagringskonfigurationen korrekt?
Kontrollera först att vm-storleken är lämplig för jobbet. Aktivera sedan Azure Diagnostics på den virtuella datorn för att få mer detaljerade data för specifika mått, till exempel CPU-användning och minnesanvändning. Om du vill aktivera VM-diagnostik via portalen går du till den virtuella datorn, väljer Diagnostikinställningaroch aktiverar sedan diagnostik.
Anta att du har en virtuell dator som har körts bra. Den virtuella datorns prestanda har dock nyligen försämrats. För att identifiera om du har några flaskhalsar i resurser måste du granska de insamlade uppgifterna.
Börja med ett tidsintervall med insamlade data före, under och efter det rapporterade problemet för att få en korrekt bild av prestanda. Dessa diagram kan också vara användbara för att korsreferera olika resursbeteenden under samma period. Du kommer att kontrollera:
- CPU-prestandaflaskhalsar
- Flaskhalsar i minnet
- Flaskhalsar på diskar
CPU-kapacitetsbegränsningar
När du tittar på prestandaproblem kan du undersöka trender för att förstå om de påverkar servern. Om du vill upptäcka trender använder du övervakningsdiagram från portalen. Du kan se olika typer av mönster i övervakningsdiagram:
- Isolerade spikar. En topp kan vara relaterad till en schemalagd aktivitet eller en förväntad händelse. Om du vet vad den här uppgiften är, körs den på den prestandanivå som krävs? Om prestandan är OK kanske du inte behöver öka kapaciteten.
- Spik upp och konstant. En ny arbetsbelastning kan orsaka den här trenden. Aktivera övervakning på den virtuella datorn för att ta reda på vilka processer som orsakar belastningen. Den ökade förbrukningen kan bero på ineffektiv kod eller på den nya arbetsbelastningens normala förbrukning. Fungerar processen på den prestandanivå som krävs om förbrukningen är normal?
- Konstant. Har den virtuella datorn alltid varit så här? I så fall bör du identifiera de processer som förbrukar de flesta resurser och överväga att lägga till kapacitet.
- stadigt ökande. Ser du en konstant ökning av förbrukningen? I så fall kan den här trenden tyda på ineffektiv kod eller en process som tar på sig mer användararbetsbelastning.
Om du ser hög CPU-användning kan du antingen:
- Öka storleken på den virtuella datorn för att skala med fler kärnor.
- Undersöka problemet ytterligare. Leta upp appen och processen och felsök därefter.
Om du skalar upp den virtuella datorn och processorn fortfarande körs på över 95 procent, är appprestandan bättre eller är appdataflödet högre till en acceptabel nivå? Annars kan du felsöka den enskilda appen.
Flaskhalsar i minnet
Du kan visa mängden minne som den virtuella datorn använder. Loggar hjälper dig att förstå trenden och om den mappas till den tidpunkt då du ser problem. Du bör inte ha mindre än 100 MB ledigt minne när som helst. Se upp för följande trender:
- Spikning och konstant förbrukning. Hög minnesanvändning kanske inte är orsaken till dåliga prestanda. Vissa appar, till exempel relationsdatabasmotorer, är minnesintensiva avsiktligt. Men om det finns flera minneshungriga appar kan det uppstå dålig prestanda eftersom minneskonkurrens orsakar trimning och sidhämtning till disk. Dessa processer orsakar en negativ prestandapåverkan.
- Stadigt ökande förbrukning. Den här trenden kan vara en app som värmer upp. Det är vanligt när databasmotorer startas. Men det kan också vara ett tecken på en minnesläcka i en app.
- Sid- eller växlingsfilanvändning. Kontrollera om du använder Windows-sidfilen kraftigt, eller Linux-växlingsfilen, som finns i /dev/sdb.
Tänk på följande lösningar för att lösa hög minnesanvändning:
- För omedelbar avlastning eller användning av sidfiler ökar du storleken på den virtuella datorn för att lägga till minne och övervakar sedan.
- Undersöka problemet ytterligare. Leta upp appen eller processen som orsakar flaskhalsen och felsök den. Om du känner till appen kan du se om du kan begränsa minnesallokeringen.
Flaskhalsar på diskar
Nätverksprestanda kan också vara relaterade till den virtuella datorns lagringsundersystem. Du kan undersöka lagringskontot för den virtuella datorn i portalen. Om du vill identifiera problem med lagring kan du titta på prestandamått från diagnostiken för lagringskontot och den virtuella datorns diagnostik. Leta efter viktiga trender när problemen uppstår inom ett visst tidsintervall.
- Om du vill söka efter tidsgränsen för Azure Storage använder du måtten ClientTimeOutError, ServerTimeOutError, AverageE2ELatency, AverageServerLatencyoch TotalRequests. Om du ser värden i måtten TimeOutError, innebär det att en I/O-åtgärd tog för lång tid och tidsgränsen uppnåddes. Om du samtidigt ser att AverageServerLatency ökar tillsammans med TimeOutErrors, kan det vara ett plattformsproblem. Skapa ett ärende med Microsofts tekniska support.
- För att kontrollera om det finns Azure Storage-begränsning använder du lagringskontots mått ThrottlingError. Om du märker åtstramningar når du IOPS-gränsen för kontot. Du kan kontrollera det här problemet genom att undersöka måttet TotalRequests.
Så här åtgärdar du problem med hög diskanvändning och svarstid:
- Optimera I/O för virtuella datorer för att överträffa gränserna för virtuella hårddiskar (VHD).
- Öka dataflödet och minska svarstiden. Om du upptäcker att du har en svarstidskänslig app och kräver högt dataflöde migrerar du dina virtuella hårddiskar till Azure Premium Storage.
Brandväggsregler för virtuella datorer som blockerar trafik
Om du vill felsöka ett NSG-flödesproblem använder du verktyget för att verifiera Network Watcher IP-flöde och NSG-flödesloggning för att avgöra om en NSG eller användardefinierad routning (UDR) stör trafikflödet.
Kör IP-flödeskontroll och ange den lokala virtuella datorn och den fjärr virtuella datorn. När du har valt Kontrollerakör Azure ett logiskt test av regler på plats. Om resultatet är att åtkomst tillåts använder du NSG-flödesloggar.
Gå till NSG:erna i portalen. Under flödeslogginställningarna väljer du På. Försök nu att ansluta till den virtuella datorn igen. Använd Trafikanalys för Network Watcher för att visualisera data. Om resultatet är att åtkomst tillåts finns det ingen NSG-regel i vägen.
Om du har nått den här punkten och fortfarande inte har diagnostiserat problemet kan det vara något fel på den fjärranslutna virtuella datorn. Inaktivera brandväggen på den virtuella fjärrdatorn och testa sedan anslutningen igen. Om du kan ansluta till den virtuella fjärrdatorn med brandväggen inaktiverad kontrollerar du inställningarna för fjärrbrandväggen. Aktivera sedan brandväggen igen.
Det går inte att kommunicera mellan klient- och serverdelsundernäten
Som standard kan alla undernät kommunicera i Azure. Om två virtuella datorer på två undernät inte kan kommunicera måste det finnas en konfiguration som blockerar kommunikationen. Innan du kontrollerar flödesloggarna kör du verktyget verifiera IP-flöde från den virtuella klientdatorn till den virtuella datorn på serversidan. Det här verktyget kör ett logiskt test på reglerna i nätverket.
Om resultatet är ett NSG på subnätet på serversidan som blockerar all kommunikation ska du konfigurera om den NSG:n. Av säkerhetsskäl måste du blockera viss kommunikation med klientdelen eftersom klientdelen exponeras för det offentliga Internet.
Genom att blockera kommunikationen till serverdelen begränsar du mängden exponering i händelse av skadlig kod eller säkerhetsattack. Men om NSG blockerar allt är det felaktigt konfigurerat. Aktivera de specifika protokoll och portar som krävs.