Utforska lösningsarkitekturen
Nu ska vi se över arkitekturen för maskininlärningsåtgärder (MLOps) för att förstå syftet med det vi försöker uppnå.
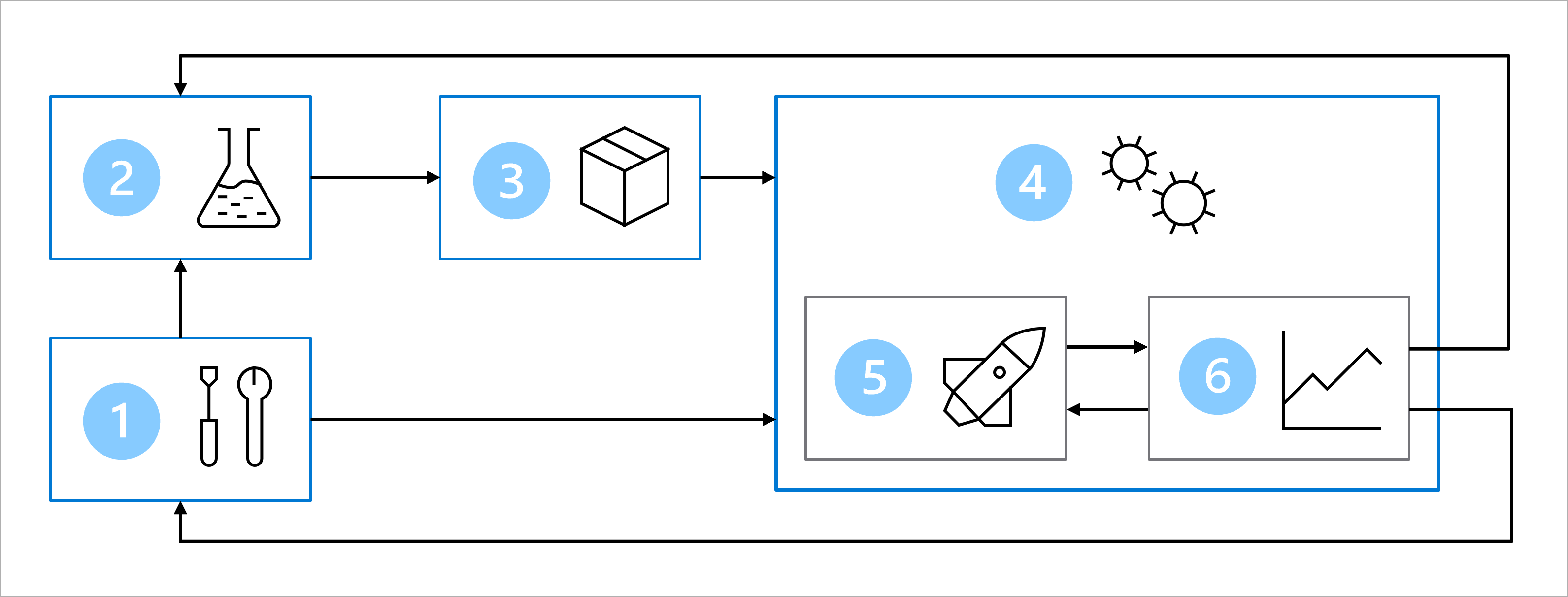
Anta att du tillsammans med datavetenskaps- och programvaruutvecklingsteamet har kommit överens om följande arkitektur för att träna, testa och distribuera diabetesklassificeringsmodellen:
Kommentar
Diagrammet är en förenklad representation av en MLOps-arkitektur. Om du vill visa en mer detaljerad arkitektur kan du utforska de olika användningsfallen i lösningsacceleratorn MLOps (v2).
Arkitekturen innehåller:
- Installation: Skapa alla nödvändiga Azure-resurser för lösningen.
- Modellutveckling (inre loop): Utforska och bearbeta data för att träna och utvärdera modellen.
- Kontinuerlig integrering: Paketera och registrera modellen.
- Modelldistribution (yttre loop): Distribuera modellen.
- Kontinuerlig distribution: Testa modellen och flytta upp till produktionsmiljön.
- Övervakning: Övervaka modell- och slutpunktsprestanda.
Data science-teamet ansvarar för modellutvecklingen. Programvaruutvecklingsteamet ansvarar för att integrera den distribuerade modellen med den webbapp som används av utövare för att bedöma om en patient har diabetes. Du ansvarar för att ta modellen från modellutveckling till modelldistribution.
Du förväntar dig att data science-teamet ständigt föreslår ändringar i de skript som används för att träna modellen. När det sker en ändring i träningsskriptet måste du träna om modellen och distribuera om modellen till den befintliga slutpunkten.
Du vill tillåta att data science-teamet experimenterar utan att röra koden som är redo för produktion. Du vill också se till att all ny eller uppdaterad kod automatiskt genomgår överenskomna kvalitetskontroller. När du har verifierat koden för att träna modellen använder du det uppdaterade träningsskriptet för att träna en ny modell och distribuera den.
För att hålla reda på ändringar och verifiera koden innan du uppdaterar produktionskoden måste du arbeta med grenar. Du har kommit överens med data science-teamet om att varje gång de vill göra en ändring skapar de en funktionsgren för att skapa en kopia av koden och göra sina ändringar i kopian.
Alla dataexperter kan skapa en funktionsgren och arbeta där. När de har uppdaterat koden och vill att koden ska vara den nya produktionskoden måste de skapa en pull-begäran. I pull-begäran visas det för andra vad de föreslagna ändringarna är, vilket ger andra möjlighet att granska och diskutera ändringarna.
När en pull-begäran skapas vill du automatiskt kontrollera om koden fungerar och att kodens kvalitet är upp till organisationens standarder. När koden har godkänt kvalitetskontrollerna måste den ledande dataexperten granska ändringarna och godkänna uppdateringarna innan pull-begäran kan sammanfogas, och koden i huvudgrenen kan uppdateras i enlighet med detta.
Viktigt!
Ingen bör någonsin tillåtas att skicka ändringar till huvudgrenen. För att skydda din kod, särskilt produktionskod, vill du framtvinga att huvudgrenen endast kan uppdateras via pull-begäranden som måste godkännas.