Introduktion
Klustring är en process för att gruppera objekt med liknande objekt. I bilden nedan finns till exempel en samling 2D-koordinater som har grupperats i tre kategorier – övre vänstra (gul), nederkant (röd) och övre högra (blå).
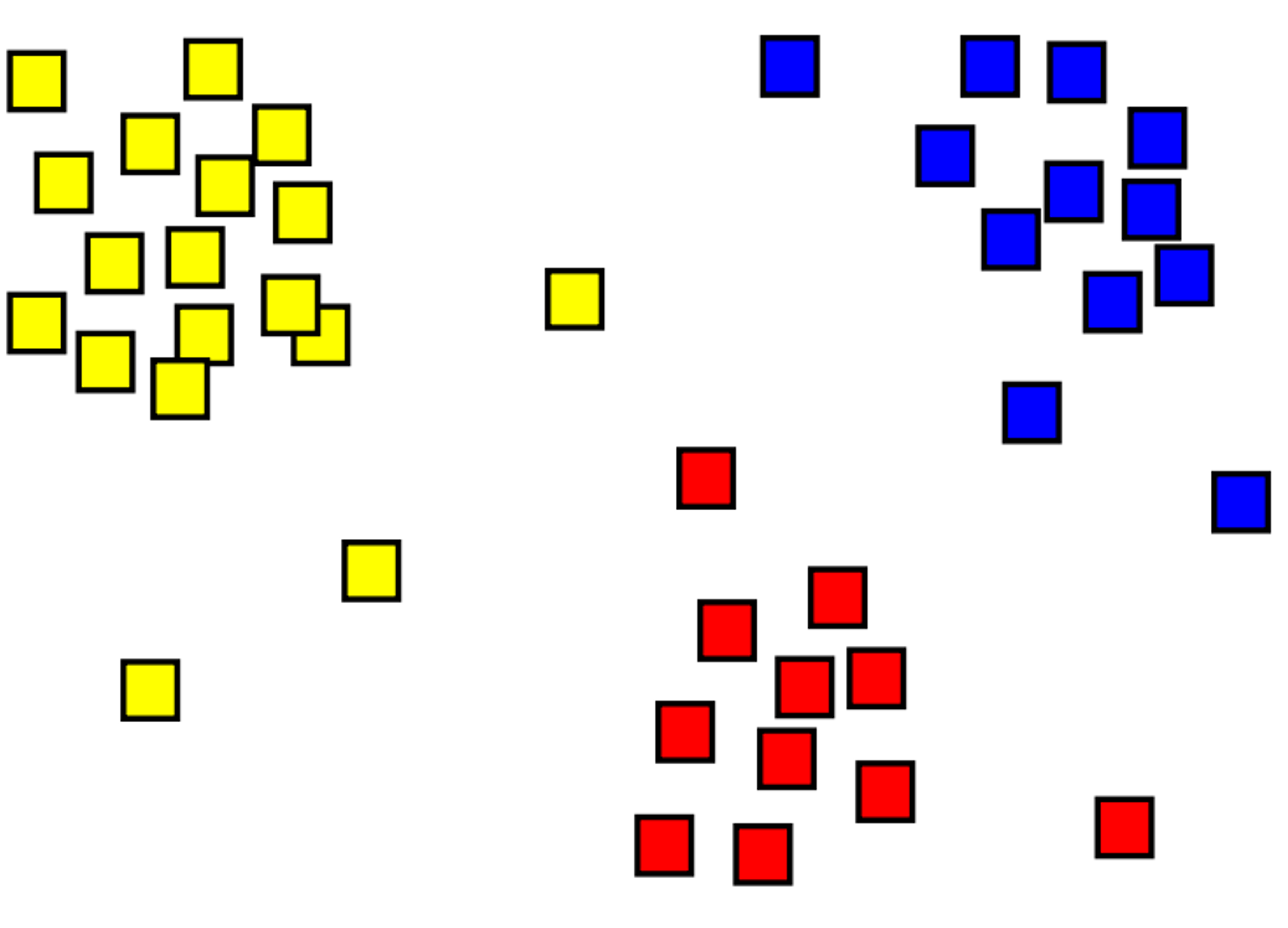
En stor skillnad mellan klustrings- och klassificeringsmodeller är att klustring är en oövervakad metod, där träning utförs utan etiketter. Klustringsmodeller identifierar exempel som har en liknande samling funktioner. I föregående bild grupperas exempel som finns på en liknande plats tillsammans.
Klustring är vanligt och användbart för att utforska nya data där mönster mellan datapunkter, till exempel kategorier på hög nivå, ännu inte är kända. Det används i många fält som automatiskt måste märka komplexa data, inklusive analys av sociala nätverk, hjärnanslutning, skräppostfiltrering och så vidare.