Utvärdera klassificeringsmodeller
Träningsnoggrannheten för en klassificeringsmodell är mycket mindre viktig än hur väl modellen fungerar när nya, osynliga data ges. Vi tränar trots allt modeller så att de kan användas på nya data som vi hittar i verkligheten. Så när vi har tränat en klassificeringsmodell utvärderar vi hur den fungerar på en uppsättning nya, osedda data.
I de tidigare enheterna skapade vi en modell som skulle förutsäga om en patient hade diabetes eller inte baserat på deras blodsockernivå. Nu får vi följande förutsägelser när de tillämpas på vissa data som inte ingick i träningsuppsättningen.
| x | y | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |
Kom ihåg att x refererar till blodsockernivån, y refererar till om de faktiskt är diabetiker, och ŷ hänvisar till modellens förutsägelse om huruvida de är diabetiker eller inte.
Att bara beräkna hur många förutsägelser som var korrekta är ibland vilseledande eller för förenklat för oss att förstå vilka typer av fel det kommer att göra i den verkliga världen. För att få mer detaljerad information kan vi ta en tabell över resultatet i en struktur som kallas för en förvirringsmatris, så här:
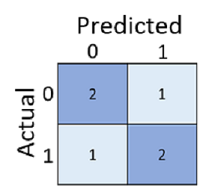
Förvirringsmatrisen visar det totala antalet fall där:
- Modellen förutsade 0 och den faktiska etiketten är 0 (sanna negativa värden, längst upp till vänster)
- Modellen förutsade 1 och den faktiska etiketten är 1 (sanna positiva identifieringar, längst ned till höger)
- Modellen förutsade 0 och den faktiska etiketten är 1 (falska negativa värden längst ned till vänster)
- Modellen förutsade 1 och den faktiska etiketten är 0 (falska positiva identifieringar uppe till höger)
Cellerna i en förvirringsmatris skuggas ofta så att högre värden har en djupare nyans. Detta gör det lättare att se en stark diagonal trend från övre vänstra till nedre högra hörnet, vilket markerar cellerna där det förutsagda värdet och det faktiska värdet är desamma.
Från dessa kärnvärden kan du beräkna ett antal andra mått som kan hjälpa dig att utvärdera modellens prestanda. Till exempel:
- Noggrannhet: (TP+TN)/(TP+TN+FP+FN) – ut alla förutsägelser, hur många var korrekta?
- Kom ihåg: TP/(TP+FN) – av alla fall som är positiva, hur många identifierade modellen?
- Precision: TP/(TP+FP) – av alla fall som modellen förutsade vara positiv, hur många är faktiskt positiva?