Använda Apache Phoenix på HDInsight HBase
HBase-kluster på HDInsight levereras med Apache Phoenix. Apache Phoenix är ett öppen källkod, massivt parallellt relationsdatabaslager som bygger på Apache HBase. Med Apache Phoenix kan du använda SQL-liknande frågor via HBase. Den använder JDBC-drivrutiner under för att göra det möjligt för användare att skapa, ta bort och ändra SQL-tabeller. Du kan också indexeras, skapa vyer och sekvenser samt öka raderna individuellt och i bulk. Phoenix använder noSQL-intern kompilering i stället för att använda MapReduce för att kompilera frågor, vilket gör det möjligt att skapa program med låg latens ovanpå HBase. Phoenix lägger till medprocessorer för att stödja körning av kod som tillhandahålls av klienten i serverns adressutrymme och kör koden som samlokaliserats med data. Den här metoden minimerar överföring av klient-/serverdata. Mer information finns i Apache Phoenix-dokumentationen.
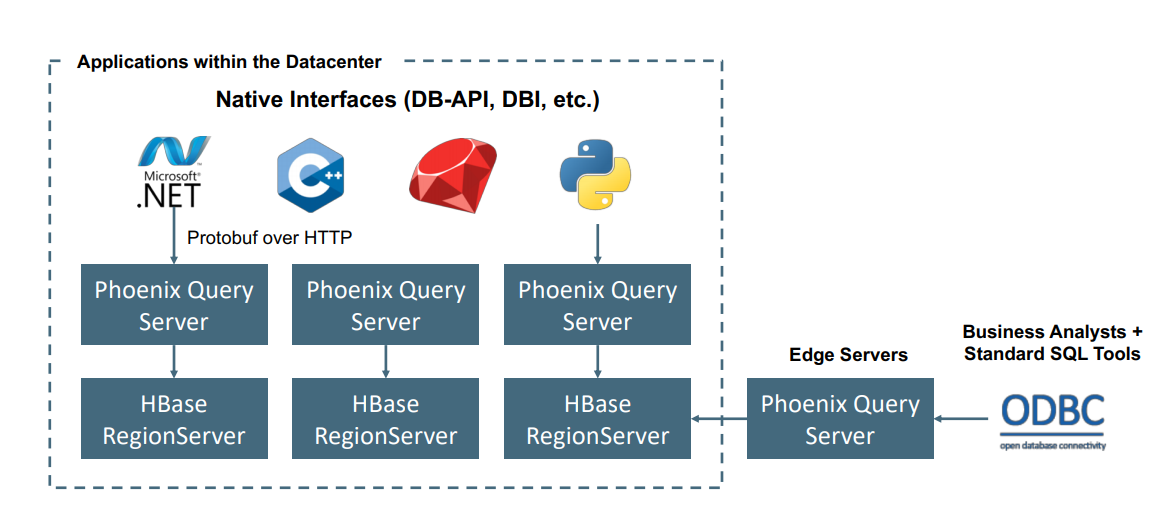
Apache Phoenix på HDInsight HBase används vanligtvis för att aktivera självbetjäningsanalys och extrahera insikter enligt beskrivningen nedan. Phoenix kan ansluta till valfritt ODBC-kompatibelt BI-verktyg och aktivera ad hoc SQL-analys på HBase.
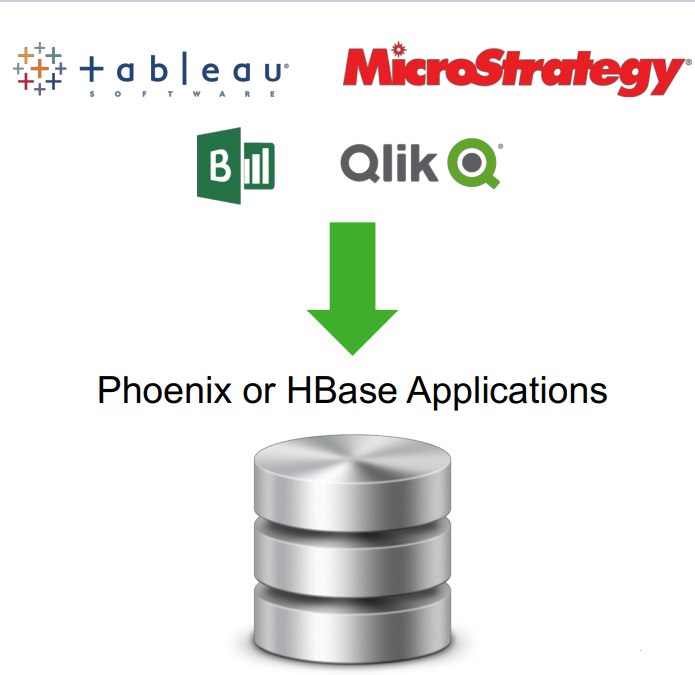
Att kombinera Apache HBase och Phoenix kan användas som ett datalager för föränderliga data. Apache Phoenix-frågemotorn på HBase har några viktiga funktioner.
Sekundära index
Poster i HBase används med hjälp av den primära radnyckeln med hjälp av ett enda index som lexicographically sorteras på den primära radnyckeln. Om du försöker komma åt poster på något annat sätt än den primära raden skulle det leda till ineffektiv genomsökning av alla data i HBase-tabellen. Med Apache Phoenix kan du skapa sekundära index för kolumner och uttryck för att skapa alternativa radnycklar för att tillåta punktsökningar eller intervallsökningar längs det nya indexet. Mer information finns i dokumentationen om Apache Phoenix Secondary Indexes.
KOMMANDOT CREATE INDEX används för att skapa sekundära index i HBase enligt nedan.
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
Vyer
Att begränsa antalet fysiska tabeller i HBase och i sin tur begränsa antalet regioner är en rekommenderad strategi. Vyer i Phoenix hjälper den här rekommendationen genom att tillåta skapandet av flera virtuella tabeller som delar samma underliggande fysiska tabell på HBase. Mer information finns i dokumentationen om Apache Phoenix Views.
Med tanke på tabelldefinitionen nedan i HBase.
CREATE TABLE product_metrics (
metric_type CHAR(1),
created_by VARCHAR,
created_date DATE,
metric_id INTEGER
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
Du kan definiera följande vy.
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS SELECT * FROM product_metric WHERE metric_type = 'm';
Transaktioner
HBase fungerar endast med transaktioner på radnivå, men Apache Phoenix möjliggör transaktioner mellan tabeller och korsrader med fullständigt ACID-stöd genom att integrera med Apache Tephra.
Mer information finns i dokumentationen om Apache Phoenix-transaktioner
I följande exempel skapas en tabell med namnet my_table och sedan ändras tabellen för att aktivera transaktioner.
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Saltade tabeller
Regionserverns hotspotting i HBase kan inträffa under sekventiella skrivningar om radnycklarna ökar monotont. Apache Phoenix kan lindra hotspotting genom att ge ett sätt att salta radnyckeln med en saltningsbyte för en viss tabell. Mer information finns i dokumentationen om Apache Phoenix Salted Table.
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Hoppa över genomsökning
För en viss uppsättning rader använder Apache Phoenix Skip Scan för genomsökning inom rad över en intervallgenomsökning för bättre prestanda. Hoppa över genomsökning utnyttjar SEEK_NEXT_USING_HINT HBase-filtret. Den lagrar information om vilken uppsättning nycklar/nyckelintervall som söks efter i varje kolumn. Den tar sedan en nyckel (skickas till den under filterutvärderingen) och räknar ut om den finns i någon av kombinationerna eller intervallet eller inte. Om inte, räknar det ut till vilken näst högsta nyckel att hoppa. Mer information finns i dokumentationen om Apache Phoenix Skip Scan.
Prestandaoptimering på Apache Phoenix är en valfri begärd funktion och är främst beroende av att optimera HBase-prestanda under. Prestandaoptimering är ett komplext ämne och ligger utanför den här kursens omfång. Men om du är intresserad kan du läsa dokumentationen om bästa praxis för Apache Phoenix-prestanda.