Beskriva Apache HBase
Apache HBase är en NoSQL-databas med öppen källkod som bygger på Apache Hadoop. HBase ger slumpmässig åtkomst och stark konsekvens för stora mängder ostrukturerade och halvstrukturerade data i en schemalös databas som ordnas efter kolumnfamiljer. HDInsight 4.0 HBase-kluster levereras med Apache HBase 2.1.6 och Apache Phoenix 5.
Från ett användarperspektiv liknar HBase en databas. Data lagras i raderna och kolumnerna i en tabell, och data i en rad grupperas efter kolumnfamilj. HBase är en schemalös databas i den mening att varken kolumner eller den typ av data som lagras i dem måste definieras innan du använder dem. Den öppna källkoden skalas linjärt för att hantera petabyte med data på tusentals noder.
HBase har följande funktioner som gör den unik
Konsekvent läsning och skrivningar
Åtgärder med låg svarstid
Automatisk horisontell partitionering
Automatisk regionserverredundans
Hadoop/HDFS/MapReduce-integrering
Java-klient-API
Stöder Thrift och REST för klientdelar som inte är java
Blockera cache- och Bloom-filter
Azure HDInsight HBase med Apache Phoenix medför följande extra fördelar
SQL- och inga SQL-gränssnitt
Flexibel kapacitetsplanering
Global distribution och replikering med Azure-nätverk
Separation av beräkning och lagring
Nära integrerad med HDInsight Enterprise-säkerhetsfunktioner
HDInsight HBase-accelererade skrivningar för läsningar och skrivningar med ultralåg svarstid
Apache Phoenix för realtids-SQL som att fråga
Med Azure HDInsight med HBase kan du köra NoSQL-databaser i massiv skala. Som en Dataingenjör för en Contoso måste du kunna köra benchmark-tester för att förstå prestanda och skala för HDInsight HBase innan du använder plattformen för verksamhetskritiska produktionsscenarier.
HBase på HDInsight körs med separation av beräkning och lagring. HDInsight HBase-kluster är konfigurerade för att lagra data direkt i Azure Storage, vilket ger låg svarstid och ökad elasticitet i prestanda- och kostnadsval. Den här egenskapen gör det möjligt för kunder att skapa interaktiva webbplatser som fungerar med stora datamängder. Skapa tjänster som lagrar sensor- och telemetridata från miljontals slutpunkter och analysera dessa data med Hadoop-jobb. HBase och Hadoop är bra utgångspunkter för stordataprojekt i Azure. Tjänsterna kan göra det möjligt för realtidsprogram att fungera med stora datamängder. HDInsight HBase-implementeringar använder en skalbar arkitektur för HBase för att tillhandahålla automatisk horisontell partitionering av tabeller. Det ger också stark konsekvens för läsningar och skrivningar samt automatisk redundans. Prestanda utökas av cachelagring i minnet för läsning och snabb strömning för skrivning. HBase-kluster kan skapas i virtuella nätverk. Mer information finns i Create HDInsight clusters on Azure Virtual Network (Skapa HDInsight-kluster i Azure Virtual Network).
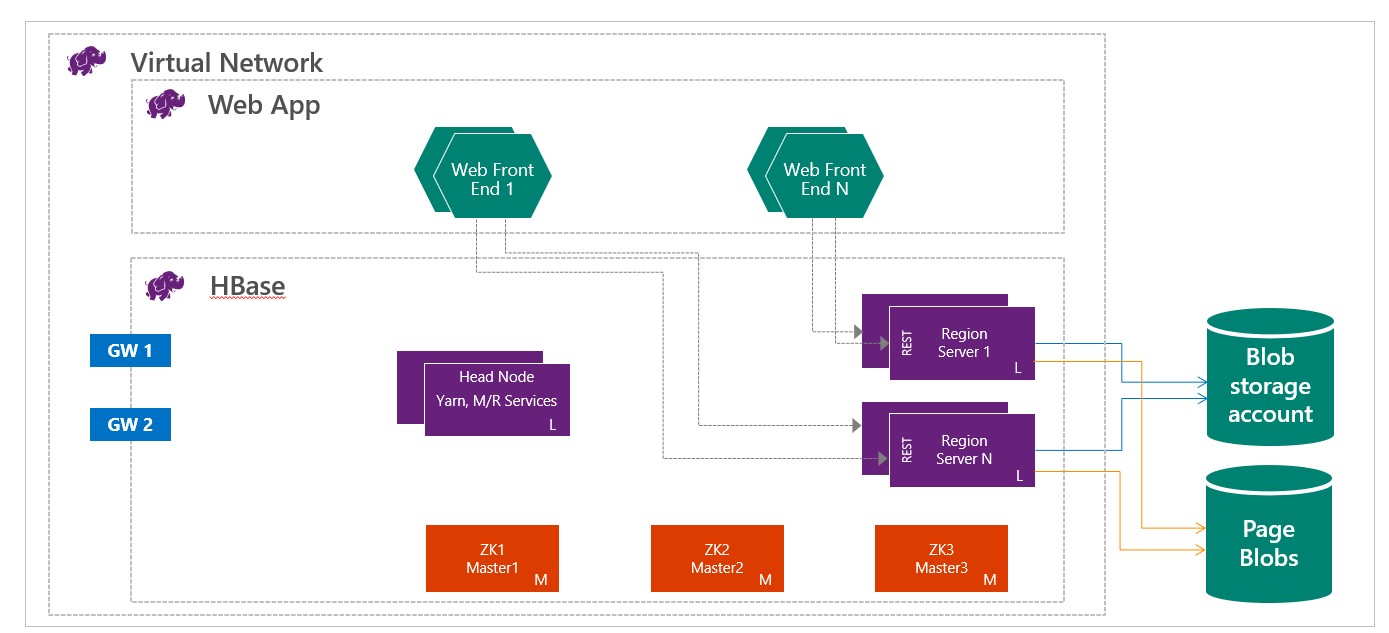
Som datatekniker måste du fastställa den lämpligaste typen av HDInsight-kluster som ska skapas för att skapa din lösning. Du använder HBase-kluster i HDInsight för en NoSQL-databas som skalar linjärt och uppnår enorma mängder dataflöde, ger läsningar med låg svarstid och obegränsad lagring till bråkdelen av kostnaden.
Följande är de viktigaste scenarierna för att använda HBase i HDInsight.
Nyckelvärdeslager
HBase används vanligtvis som ett nyckelvärdeslager och är lämpligt för att hantera meddelandesystem.
Sensordata
HBase är användbart för att samla in data som samlas in stegvis från olika källor, vilket inkluderar social analys, tidsserier, hålla interaktiva instrumentpaneler uppdaterade med trender och räknare och hantering av granskningsloggsystem.
Realtidsfråga
Apache Phoenix är en SQL-frågemotor för Apache HBase. Den används som en JDBC-drivrutin och gör det möjligt att köra frågor mot och hantera HBase-tabeller med hjälp av SQL.
HBase som en plattform
Program kan köras ovanpå HBase genom att använda det som ett datalager. Några exempel är Phoenix, OpenTSDB, Kiji och Titan. Program kan också integreras med HBase. Exempel är Apache Hive, Apache Pig, Solr, Apache Flume, Apache Impala, Apache Spark, Ganglia och Apache Drill.
I HDInsight kan HBase användas som fristående program eller distribueras tillsammans med andra stordataanalysprogram som Spark, Hadoop, Hive eller Kafka.
HBase-datamodellen lagrar halvstrukturerade data med olika datatyper, varierande kolumnstorlek och fältstorlek. Layouten för HBase-datamodellen underlättar datapartitionering och distribution i klustret. HBase-datamodellen består av flera logiska komponenter– radnycklar, kolumnfamilj, tabellnamn, tidsstämpel osv.
En radnyckel används för att unikt identifiera raderna i HBase-tabeller. I HDInsight kan du antingen skriva data till HBase direkt med hjälp av flera tillgängliga API:er som HBase REST, HBase RPC, Phoenix Query Server, HBase bulk load eller använda integreringen med flera stordataramverk som Apache Spark, Hive osv.
Du kan använda funktionen för HBase-accelererade skrivningar för att aktivera högt skrivdataflöde. Mer information om HBase-arkitektur och metodtips finns i HBase Book.