Övning – Visualisera utdata för modellen
I den här enheten importerar du Matplotlib till den notebook-fil som du har arbetat med och konfigurerar notebook-filen för att stödja infogade Matplotlib-utdata.
Gå tillbaka till den Azure-notebook-fil som du skapade i föregående avsnitt. Om du stängde anteckningsboken kan du logga in på Microsoft Azure Notebooks-portalen igen, öppna anteckningsboken och använda Cell ->Kör alla för att köra alla celler i anteckningsboken igen när du har öppnat den.
Kör följande instruktioner i en ny cell i slutet av notebook-filen. Ignorera eventuella varningsmeddelanden som visas som rör cachelagring av teckensnitt:
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns sns.set()Den första instruktionen är ett av flera magiska kommandon som stöds av den Python-kernel som du valde när du skapade notebook-filen. Det gör att Jupyter kan rendera Matplotlib-utdata i en notebook-fil utan att göra upprepade anrop till show. Och det måste anges före alla referenser till Matplotlib självt. Den sista instruktionen konfigurerar Seaborn till att förbättra utdata från Matplotlib.
Om du vill se hur Matplotlib fungerar kör du följande kod i en ny cell för att plotta ROC-kurvan för den maskininlärningsmodell som du skapade i föregående övning:
from sklearn.metrics import roc_curve fpr, tpr, _ = roc_curve(test_y, probabilities[:, 1]) plt.plot(fpr, tpr) plt.plot([0, 1], [0, 1], color='grey', lw=1, linestyle='--') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate')Kontrollera att du ser följande utdata:
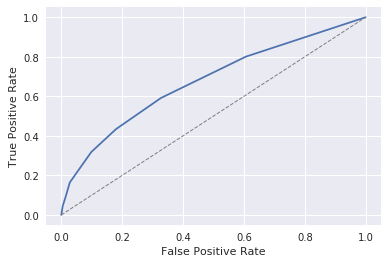
Den ROC-kurva som genererats med Matplotlib
Den streckade linjen i mitten av grafen representerar 50 procents chans att få rätt svar. Den blå kurvan representerar modellens noggrannhet. Något som är viktigare är att det här diagrammet överhuvudtaget visas, vilket demonstrerar att du kan använda Matplotlib i en Jupyter-notebook-fil.
Syftet med att du har skapat en maskininlärningsmodell är att förutsäga huruvida en flygresa kommer att ankomma i tid eller bli försenad. I den här övningen skriver du en Python-funktion som anropar den maskininlärningsmodell som du skapade i föregående övning för att beräkna sannolikheten att en flygresa ankommer i tid. Sedan använder du funktionen för att analysera flera flygresor.
Ange följande funktionsdefinition i en ny cell och kör sedan cellen.
def predict_delay(departure_date_time, origin, destination): from datetime import datetime try: departure_date_time_parsed = datetime.strptime(departure_date_time, '%d/%m/%Y %H:%M:%S') except ValueError as e: return 'Error parsing date/time - {}'.format(e) month = departure_date_time_parsed.month day = departure_date_time_parsed.day day_of_week = departure_date_time_parsed.isoweekday() hour = departure_date_time_parsed.hour origin = origin.upper() destination = destination.upper() input = [{'MONTH': month, 'DAY': day, 'DAY_OF_WEEK': day_of_week, 'CRS_DEP_TIME': hour, 'ORIGIN_ATL': 1 if origin == 'ATL' else 0, 'ORIGIN_DTW': 1 if origin == 'DTW' else 0, 'ORIGIN_JFK': 1 if origin == 'JFK' else 0, 'ORIGIN_MSP': 1 if origin == 'MSP' else 0, 'ORIGIN_SEA': 1 if origin == 'SEA' else 0, 'DEST_ATL': 1 if destination == 'ATL' else 0, 'DEST_DTW': 1 if destination == 'DTW' else 0, 'DEST_JFK': 1 if destination == 'JFK' else 0, 'DEST_MSP': 1 if destination == 'MSP' else 0, 'DEST_SEA': 1 if destination == 'SEA' else 0 }] return model.predict_proba(pd.DataFrame(input))[0][0]Den här funktionen tar datum och tid, en flygplatskod för avgångsplatsen samt en flygplatskod för ankomstplatsen och returnerar ett värde mellan 0,0 och 1,0 som anger sannolikheten att den flygresan ankommer till målet i tid. Den använder den maskininlärningsmodell som du skapade i föregående övning för att beräkna sannolikheten. Och för att anropa modellen skickar den en dataram som innehåller indatavärden till
predict_proba. Dataramens struktur är exakt samma som för den dataram vi använde tidigare.Kommentar
Datumindata till funktionen
predict_delayanvänder det internationella datumformatetdd/mm/year.Du kan använda koden nedan för att beräkna sannolikheten att en flygresa från New York till Atlanta kvällen den 1 oktober ankommer i tid. Det år som du anger är inte relevant eftersom det inte används av modellen.
predict_delay('1/10/2018 21:45:00', 'JFK', 'ATL')Kontrollera att utdata visar att sannolikheten för en ankomst i tid är 60 %:

Förutsäga huruvida en flygresa ankommer i tid
Ändra koden för att beräkna sannolikheten att samma flygresa en dag senare ankommer i tid:
predict_delay('2/10/2018 21:45:00', 'JFK', 'ATL')Hur troligt är den här flygresan ankommer i tid? Skulle du överväga att skjuta upp resan en dag om dina reseplaner vore flexibla?
Ändra nu koden till att beräkna sannolikheten att en flygresa på morgonen samma dag från Atlanta till Seattle ankommer i tid:
predict_delay('2/10/2018 10:00:00', 'ATL', 'SEA')Är det troligt att den här flygresan ankommer i tid?
Nu har du ett enkelt sätt att med en enda rad kod förutsäga om en flygresa sannolikt ankommer i tid eller blir försenad. Experimentera gärna med andra datum, tider, avgångsplatser och mål. Men tänk på att resultatet bara är meningsfullt för flygplatskoderna ATL, DTW, JFK, MSP och SEA eftersom de är de enda flygplatskoder som modellen har tränats med.
Kör följande kod för att plotta sannolikheten för ankomst i tid för en flygresa på kvällen från JFK till ATL över ett antal dagar:
import numpy as np labels = ('Oct 1', 'Oct 2', 'Oct 3', 'Oct 4', 'Oct 5', 'Oct 6', 'Oct 7') values = (predict_delay('1/10/2018 21:45:00', 'JFK', 'ATL'), predict_delay('2/10/2018 21:45:00', 'JFK', 'ATL'), predict_delay('3/10/2018 21:45:00', 'JFK', 'ATL'), predict_delay('4/10/2018 21:45:00', 'JFK', 'ATL'), predict_delay('5/10/2018 21:45:00', 'JFK', 'ATL'), predict_delay('6/10/2018 21:45:00', 'JFK', 'ATL'), predict_delay('7/10/2018 21:45:00', 'JFK', 'ATL')) alabels = np.arange(len(labels)) plt.bar(alabels, values, align='center', alpha=0.5) plt.xticks(alabels, labels) plt.ylabel('Probability of On-Time Arrival') plt.ylim((0.0, 1.0))Bekräfta att utdata ser ut så här:
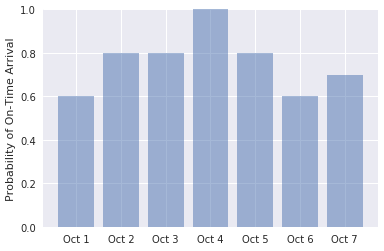
Sannolikheten för ankomst i tid över ett antal dagar
Ändra koden för att skapa ett liknande diagram för flygningar som lämnar JFK för MSP kl. 13:00 den 10 april till 16 april. Hur ser utdata ut jämfört med utdata i föregående steg?
På egen hand skriver du kod för att grafera sannolikheten att flygningar som lämnar SEA för ATL klockan 09:00, 12:00, 15:00, 18:00 och 21:00 den 30 januari anländer i tid. Bekräfta att utdata ser ut så här:
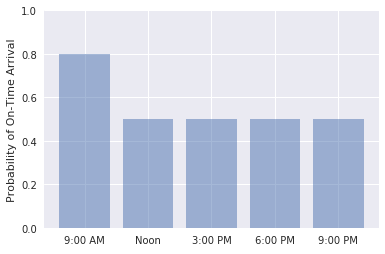
Sannolikheten för ankomst i tid över ett antal tider
Om du inte har använt Matplotlib förut och vill lära dig mer hittar du en utmärkt självstudie på https://www.labri.fr/perso/nrougier/teaching/matplotlib/.. Det finns mycket mer att lära sig om Matplotlib än vad vi gick igenom här, vilket är en orsak till varför det är så populärt i Python-communityn.