Övning – Rensa och förbereda data
Innan du kan förbereda en datamängd behöver du förstå dess innehåll och struktur. I den föregående övningen importerade du en datamängd som innehöll information om ankomster i tid för ett stort amerikanskt flygbolag. Dessa data omfattade 26 kolumner och tusentals rader, där varje rad representerade en flygresa och innehöll information såsom flygresans avgångsplats, resmål och schemalagd avgångstid. Du läste även in data i en Jupyter-notebook-fil och använde ett enkelt Python-skript för att skapa en Pandas-dataram från dem.
En dataram är en tvådimensionell etiketterad datastruktur. Kolumnerna i en dataram kan vara av olika typer, precis som kolumner i ett kalkylblad eller en databastabell. Det är det objekt som används oftast i Pandas. I den här övningen undersöker du dataramen och dess data närmare.
Gå tillbaka till den Azure-notebook-fil som du skapade i föregående avsnitt. Om du stängde anteckningsboken kan du logga in på Microsoft Azure Notebooks-portalen igen, öppna anteckningsboken och använda Cell ->Kör alla för att köra alla celler i anteckningsboken igen när du har öppnat den.
FlightData-notebook-filen
Den kod som du lade till i notebook-filen i föregående övning skapar en dataram från flightdata.csv och anropar DataFrame.head på den för att visa de första fem raderna. En av de första saker som du förmodligen vill veta om en datamängd är hur många rader den innehåller. För att få fram antalet skriver du in följande instruktion i en tom cell i slutet av notebook-filen och kör den:
df.shapeBekräfta att dataramen innehåller 11 231 rader och 26 kolumner:

Hämta antalet rader och kolumner
Undersök nu de 26 kolumnerna i datamängden. De innehåller viktig information, till exempel det datum då flygresan ägde rum (YEAR (år), MONTH (månad) och DAY_OF_MONTH (månadsdag)), avgångsplats och mål (ORIGIN och DEST), schemalagd avgångstid och ankomsttider (CRS_DEP_TIME respektive CRS_ARR_TIME), skillnaden mellan schemalagd ankomsttid och faktisk ankomsttid i minuter (ARR_DELAY) samt huruvida flygresan var försenad med 15 minuter eller mer (ARR_DEL15).
Här är en fullständig lista över kolumnerna i datamängden. Tiderna anges i fyrsiffrigt 24-timmarsformat. Till exempel är 1130 lika med 11:30 och 1500 är lika med 15:00.
Kolumn beskrivning YEAR Det år då flygresan ägde rum QUARTER Det kvartal då flygresan ägde rum (1–4) MONTH Den månad då flygresan ägde rum (1–12) DAY_OF_MONTH Den månadsdag då flygresan ägde rum (1–31) DAY_OF_WEEK Den veckodag då flygresan ägde rum (1 = måndag, 2 = tisdag osv.) UNIQUE_CARRIER Flygbolagets transportföretagskod (t.ex. DL) TAIL_NUM Flygplanets registreringsnummer FL_NUM Flygnummer ORIGIN_AIRPORT_ID Avgångsflygplatsens ID ORIGIN Avgångsflygplatsens kod (ATL, DFW, SEA osv.) DEST_AIRPORT_ID Målflygplatsens ID DEST Målflygplatsens kod (ATL, DFW, SEA osv.) CRS_DEP_TIME Schemalagd avgångstid DEP_TIME Faktisk avgångstid DEP_DELAY Antal minuter som avgången fördröjdes DEP_DEL15 0 = avgången fördröjdes mindre än 15 minuter, 1 = avgången fördröjdes 15 minuter eller mer CRS_ARR_TIME Schemalagd ankomsttid ARR_TIME Faktisk ankomsttid ARR_DELAY Antal minuter som flygresan var försenad med ARR_DEL15 0 = ankom mindre än 15 minuter för sent, 1 = ankom 15 minuter för sent eller mer CANCELLED 0 = flygresan ställdes inte in, 1 = flygresan ställdes in DIVERTED 0 = flygresan omdirigerades inte, 1 = flygresan omdirigerades CRS_ELAPSED_TIME Schemalagd flygtid i minuter ACTUAL_ELAPSED_TIME Faktisk flygtid i minuter DISTANCE Avstånd i engelska mil
Datamängden innehåller en ganska jämn fördelning av datum under året, vilket är viktigt eftersom en flygresa från Minneapolis är mindre benägen att fördröjas på grund av snöstorm i juli än i januari. Den här datamängden är dock långt från att vara ”ren” och redo att användas. Nu skriver vi lite Pandas-kod som rensar den.
En av de viktigaste aspekterna med att förbereda en datamängd för användning i maskininlärning är att välja de ”egenskapskolumner” som är relevanta för det resultat som du försöker förutse samt att filtrera bort kolumner som inte påverkar resultatet, kan leda till negativ påverkan via bias eller ge upphov till multikollinearitet. En annan viktig uppgift är att eliminera saknade värden genom att antingen ta bort rader eller kolumner som innehåller dessa värden eller ersätta dem med meningsfulla värden. I den här övningen tar du bort överflödiga kolumner och ersätter saknade värden i de övriga kolumnerna.
En av de första saker som datatekniker vanligtvis letar efter i en datamängd är saknade värden. Det finns ett enkelt sätt att söka efter saknade värden i Pandas. Demonstrera detta genom att lägga till följande kod i en cell i slutet av notebook-filen:
df.isnull().values.any()Kontrollera att resultatet är ”True”, vilket betyder att det finns minst ett saknat värde någonstans i datamängden.

Söka efter saknade värden
Nästa steg är att ta reda på var de saknade värdena finns. Det gör du genom att köra följande kod:
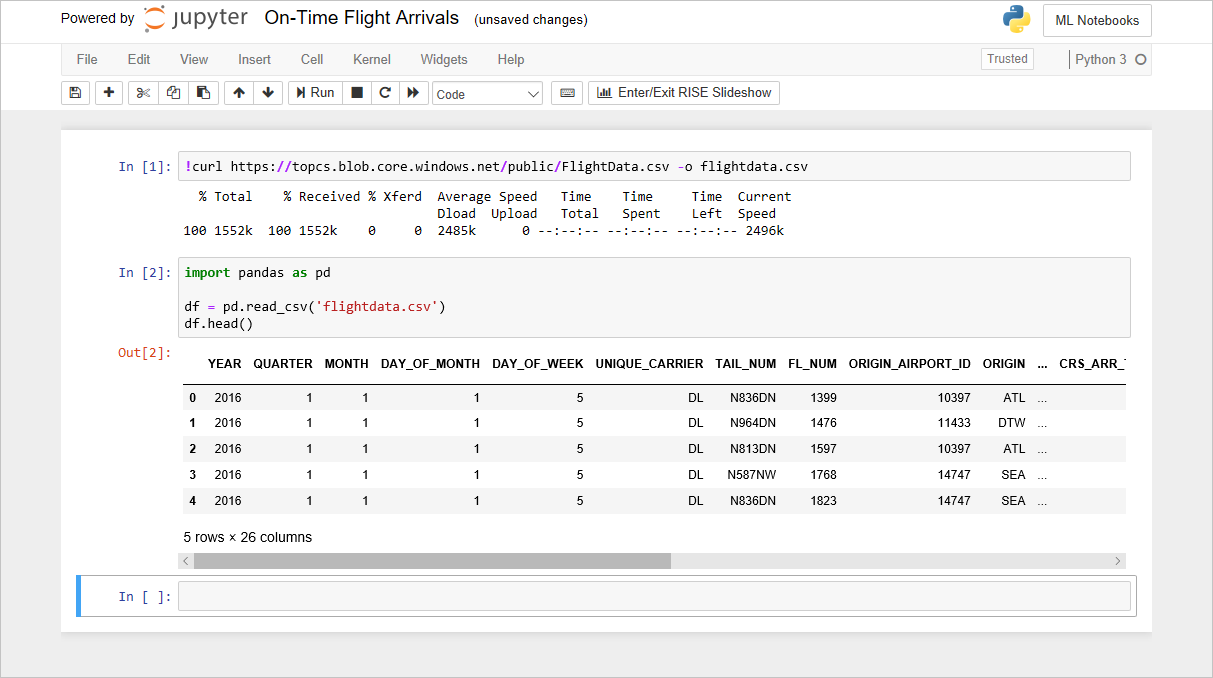
df.isnull().sum()Kontrollera att du ser i följande utdata som visar antalet saknade värden i varje kolumn:
Antalet saknade värden i varje kolumn
Märkligt nog innehåller den 26:e kolumnen ("Namnlös: 25") 11 231 saknade värden, vilket motsvarar antalet rader i datamängden. Den här kolumnen skapades av misstag eftersom den CSV-fil som du importerade innehåller ett kommatecken i slutet av varje rad. Du kan ta bort den kolumnen genom att lägga till följande kod i notebook-filen och köra den:
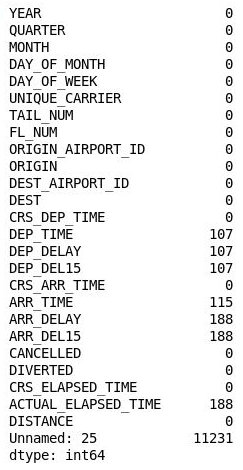
df = df.drop('Unnamed: 25', axis=1) df.isnull().sum()Granska utdata och kontrollera att kolumn 26 har försvunnit från dataramen:
Dataramen med kolumn 26 borttagen
Dataramen innehåller fortfarande många saknade värden, men vissa av dem är inte användbara eftersom de kolumner som innehåller dem inte är relevanta för den modell som du skapar. Målet med den modellen är att förutsäga om en flygresa som du funderar på att boka kan förväntas ankomma i tid. Om du vet att risken för försening är stor väljer du kanske att boka en annan flygresa.
Därför är nästa steg att filtrera datamängden för att ta bort kolumner som inte är relevanta för en förutsägelsemodell. Till exempel har flygplanets registreringsnummer förmodligen inte så stor inverkan på huruvida en flygresa ankommer i tid, och när du bokar biljetten finns det inget sätt att ta reda på om en flygresa kommer att ställas in, omdirigeras eller fördröjas. Däremot kan den schemalagda avgångstiden avsevärt påverka ankomsten. På grund av det nav-och-eker-system som de flesta flygbolag använder ankommer flygresor på morgonen oftare i tid än flygresor på eftermiddagen eller kvällen. Och vid vissa större flygplatser ökar trafiken under dagen, vilket gör det troligare att senare flygresor fördröjs.
Pandas erbjuder ett enkelt sätt att filtrera bort kolumner som du inte vill ha. Kör följande kod i en ny cell i slutet av notebook-filen:
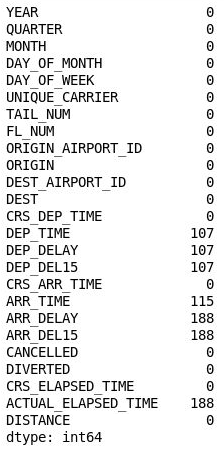
df = df[["MONTH", "DAY_OF_MONTH", "DAY_OF_WEEK", "ORIGIN", "DEST", "CRS_DEP_TIME", "ARR_DEL15"]] df.isnull().sum()Utdata visar att dataramen nu bara innehåller de kolumner som är relevanta för modellen och att antalet saknade värden har minskats avsevärt:
Den filtrerade dataramen
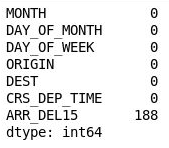
Den enda kolumn som nu innehåller saknade värden är kolumnen ARR_DEL15, som använder 0:or för att identifiera flygresor som anlänt i tid och 1:or för flygresor som inte anlände i tid. Använd följande kod för att visa de första fem raderna med saknade värden:
df[df.isnull().values.any(axis=1)].head()Pandas representerar saknade värden med
NaN, som står för Not a Number (Inte ett tal). Utdata visar att de här raderna mycket riktigt saknar värden i kolumnen ARR_DEL15:
Rader med saknade värden
Anledningen till att de här raderna saknar ARR_DEL15-värden är att de allihop motsvarar flygresor som har ställts in eller omdirigerats. Du skulle kunna anropa dropna på dataramen för att ta bort de här raderna. Men eftersom en flygning som ställs in eller omdirigeras till en annan flygplats kan betraktas som ”försenad” använder vi metoden fillna för att ersätta de saknade värdena med 1:or.
Använd följande kod för att ersätta saknade värden i kolumnen ARR_DEL15 med 1:or och visa raderna 177 till och med 184:
df = df.fillna({'ARR_DEL15': 1}) df.iloc[177:185]Bekräfta att
NaN:orna på raderna 177, 179 och 184 ersattes med 1:or som anger att flygresorna anlände sent: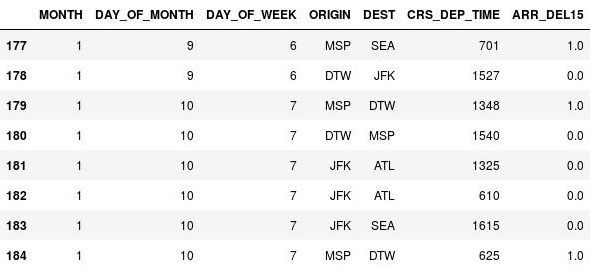
NaN har ersatts med 1:or
Datamängden är nu ”ren” i den mening att saknade värden har ersatts och listan över kolumner har begränsats till dem som är mest relevanta för modellen. Men det är inte klart än. Det finns mer att göra för att förbereda datamängden för användning i maskininlärning.
Kolumnen CRS_DEP_TIME i den datamängd som du använder representerar schemalagda avgångstider. Kornigheten för siffrorna i den här kolumnen, som innehåller fler än 500 unika värden, kan ha en negativ inverkan på precisionen hos en maskininlärningsmodell. Detta kan lösas med hjälp av en teknik som kallas gruppering, eller kvantisering. Vad händer om du skulle dela varje siffra i den här kolumnen med 100 och runda ned till närmaste heltal? 1030 skulle bli 10, 1925 skulle bli 19 och så vidare, och du skulle ha högst 24 diskreta värden kvar i den här kolumnen. Intuitivt är det vettigt, eftersom det förmodligen inte spelar så stor roll om ett flyg avgår klockan 10:30 eller 10:40. Det spelar stor roll om den lämnar klockan 10:30 eller 17:30.
Dessutom innehåller datamängdens kolumner ORIGIN och DEST flygplatskoder som representerar kategoriska maskininlärningsvärden. De här kolumnerna behöver konverteras till diskreta kolumner som innehåller indikatorvariabler, som ibland kallas ”dummyvariabler”. Med andra ord behöver kolumnen ORIGIN, som innehåller fem flygplatskoder, konverteras till fem kolumner, en per flygplats, där varje kolumn innehåller 1:or och 0:or som anger huruvida en flygresa avgick från den flygplats som kolumnen representerar. Kolumnen DEST behöver hanteras på ett liknande sätt.
I den här övningen ”grupperar” du avgångstiderna i kolumnen CRS_DEP_TIME och använder Pandas metod get_dummies för att skapa indikatorkolumner utifrån kolumnerna ORIGIN och DEST.
Använd följande kommando för att visa de fem första raderna i dataramen:
df.head()Observera att kolumnen CRS_DEP_TIME innehåller värden mellan 0 och 2359, som representerar fyrsiffriga 24-timmarstider.
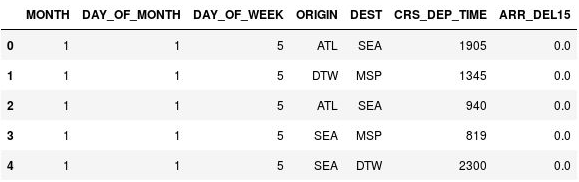
Dataramen med ogrupperade avgångstider
Använd följande instruktioner för att gruppera avgångstiderna:
import math for index, row in df.iterrows(): df.loc[index, 'CRS_DEP_TIME'] = math.floor(row['CRS_DEP_TIME'] / 100) df.head()Bekräfta att siffrorna i kolumnen CRS_DEP_TIME nu ligger i intervallet 0 till 23:
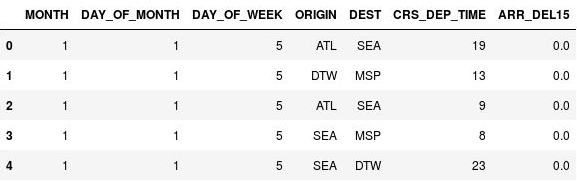
Dataramen med grupperade avgångstider
Använd nu följande instruktioner för att skapa indikatorkolumner utifrån kolumnerna ORIGIN och DEST, samtidigt som kolumnerna ORIGIN och DEST själva släpps:
df = pd.get_dummies(df, columns=['ORIGIN', 'DEST']) df.head()Granska resulterande dataram och notera att kolumnerna ORIGIN och DEST ersattes med kolumner som motsvarar de flygplatskoder som finns i originalkolumnerna. De nya kolumnerna innehåller 1:or och 0:or som anger huruvida en viss flygresa avgick från eller hade motsvarande flygplats som mål.
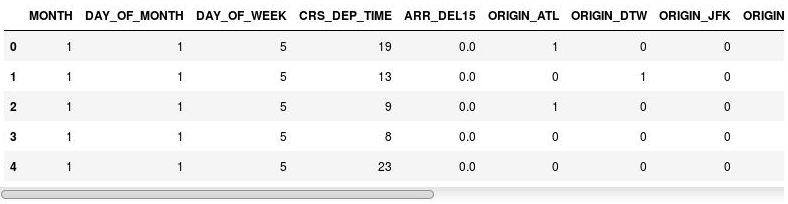
Dataramen med indikatorkolumner
Använd kommandot Arkiv ->Spara och Kontrollpunkt för att spara anteckningsboken.
Datamängden ser mycket annorlunda ut än den gjorde i början, men den har nu optimerats för användning i maskininlärning.