Integrera Apache Spark- och Hive LLAP-frågor
I föregående lektion tittade vi på två sätt att köra frågor mot statiska data som lagras i ett Interaktiv fråga kluster – Data Analytics Studio och en Zeppelin-notebook-fil. Men vad händer om du vill strömma nya fastighetsdata till dina kluster med Spark och sedan köra frågor mot dem med Hive? Eftersom Hive och Spark har två olika metaarkiv behöver de en anslutningsapp för att överbrygga mellan de två – och Apache Hive Warehouse Connector (HWC) är den bryggan. Med Hive Warehouse Connector-biblioteket kan du arbeta enklare med Apache Spark och Apache Hive genom att stödja uppgifter som att flytta data mellan Spark DataFrames- och Hive-tabeller och även dirigera Spark-strömmande data till Hive-tabeller. Vi konfigurerar inte anslutningsappen i vårt scenario, men det är viktigt att veta att alternativet finns.
Apache Spark har ett API för strukturerad direktuppspelning som tillhandahåller strömningsfunktioner som inte är tillgängliga i Apache Hive. Från och med HDInsight 4.0 har Apache Spark 2.3.1 och Apache Hive 3.1.0 separata metaarkiv, vilket gjorde samverkan svår. Hive Warehouse Connector gör det enklare att använda Spark och Hive tillsammans. Hive Warehouse Connector-biblioteket läser in data från LLAP-daemoner till Spark-köre parallellt, vilket gör det mer effektivt och skalbart än att använda en JDBC-standardanslutning från Spark till Hive.
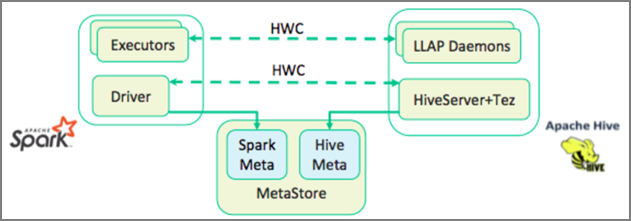
Några av de åtgärder som stöds av Hive Warehouse Connector är:
- Beskriva en tabell
- Skapa en tabell för ORC-formaterade data (Optimized Row Columnar)
- Välja Hive-data och hämta en DataFrame
- Skriva en dataram till Hive i batch
- Köra en Hive-uppdateringsinstruktor
- Läsa tabelldata från Hive, transformera dem i Spark och skriva dem till en ny Hive-tabell
- Skriva en DataFrame- eller Spark-dataström till Hive med HiveStreaming
När du har distribuerat ett Spark-kluster och ett Interaktiv fråga kluster konfigurerar du Spark-klusterinställningarna i Ambari, som är ett webbaserat verktyg som ingår i alla HDInsight-kluster. Öppna Ambari genom att gå till https:// servername.azurehdinsight.net i webbläsaren där servernamnet är namnet på ditt Interaktiv fråga kluster.
Om du sedan vill skriva Spark-strömmande data till tabellerna skapar du en Hive-tabell och börjar skriva data till den. Kör sedan frågor på dina strömmande data, du kan använda något av följande:
- spark-shell
- PySpark
- spark-submit
- Zeppelin
- Livy