Övning – Ladda upp och fråga efter data i HDInsight
Nu när du har etablerat ett lagringskonto och ett Interaktiv fråga kluster är det dags att ladda upp dina fastighetsdata och köra några frågor. De data som du laddar upp är Fastighetsdata i New York City. Den innehåller över 28 000 fastighetsposter, inklusive adresser, försäljningspriser, kvadratmeter och geokodad platsinformation för enkel mappning. Ditt fastighetsinvesteringsföretag använder denna information för att fastställa lämpliga kvadratmeterpriser för nya fastigheter som kommer på marknaden, baserat på försäljningspriser för tidigare sålda fastigheter.
För att ladda upp och fråga efter data använder vi Data Analytics Studio, som är ett webbaserat program som installerades i skriptåtgärden som vi använde när vi skapade Interaktiv fråga klustret. Du kan använda Data Analytics Studio för att ladda upp data till Azure Storage, transformera data till Hive-tabeller med hjälp av de datatyper och kolumnnamn som du anger och sedan köra frågor mot data i klustret med HiveQL. Förutom Data Analysstudio kan du använda valfritt ODBC/JDBC-kompatibelt verktyg för att arbeta med dina data med Hive, till exempel Spark & Hive Tools för Visual Studio Code.
Sedan använder du en Zeppelin Notebook för att snabbt visualisera trender i data. Med Zeppelin Notebooks kan du skicka frågor och visa resultatet i ett antal olika fördefinierade diagram. Zeppelin Notebooks som är installerade på Interaktiv fråga kluster har en JDBC-tolk med en Hive-drivrutin.
Ladda ned fastighetsdata
- Gå till https://github.com/Azure/hdinsight-mslearn/tree/master/Sample%20dataoch ladda ned datauppsättningen för att spara filen propertysales.csv på datorn.
Ladda upp data med Data Analytics Studio
- Öppna nu Data Analytics Studio i webbläsaren med hjälp av följande URL och ersätt servernamn med det klusternamn som du använde: https:// servername.azurehdinsight.net/das/
För att logga in är användarnamnet administratör och lösenordet är lösenordet du skapade.
Om du stöter på ett fel går du till fliken Översikt i klustret i Azure-portalen och kontrollerar att statusen är inställd på Körs och att klustertypen HDI-versionen är inställd på Interaktiv fråga 3.1 (HDI 4.0).
- Data Studio Analytics lanseras i webbläsaren.
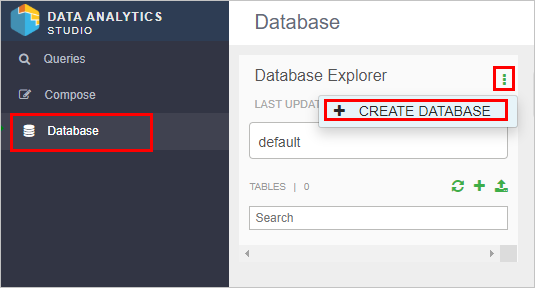
- Klicka på Databas på den vänstra menyn, klicka sedan på den gröna upprättstående ellipsknappen och klicka sedan på Skapa databas.
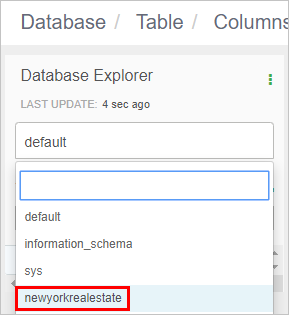
Ge databasen namnet "newyorkrealestate" och klicka sedan på Skapa.
I Databasutforskaren klickar du på rutan databasnamn och väljer sedan newyorkrealestate.
- I Databasutforskaren klickar du på + och sedan på Skapa tabell.
- Ge den nya tabellen namnet "propertysales" och klicka sedan på Ladda upp tabell. Tabellnamn får endast innehålla gemener och siffror, inga specialtecken.
- I området Välj filformat på sidan:
- Kontrollera att filformatet är csv
- Markera rutan Är första radens rubrik?
- I området Välj filkälla på sidan:
- Välj Ladda upp från Lokal.
- Klicka på Dra fil för att ladda upp eller klicka på Bläddra och navigera till filen propertysales.csv.
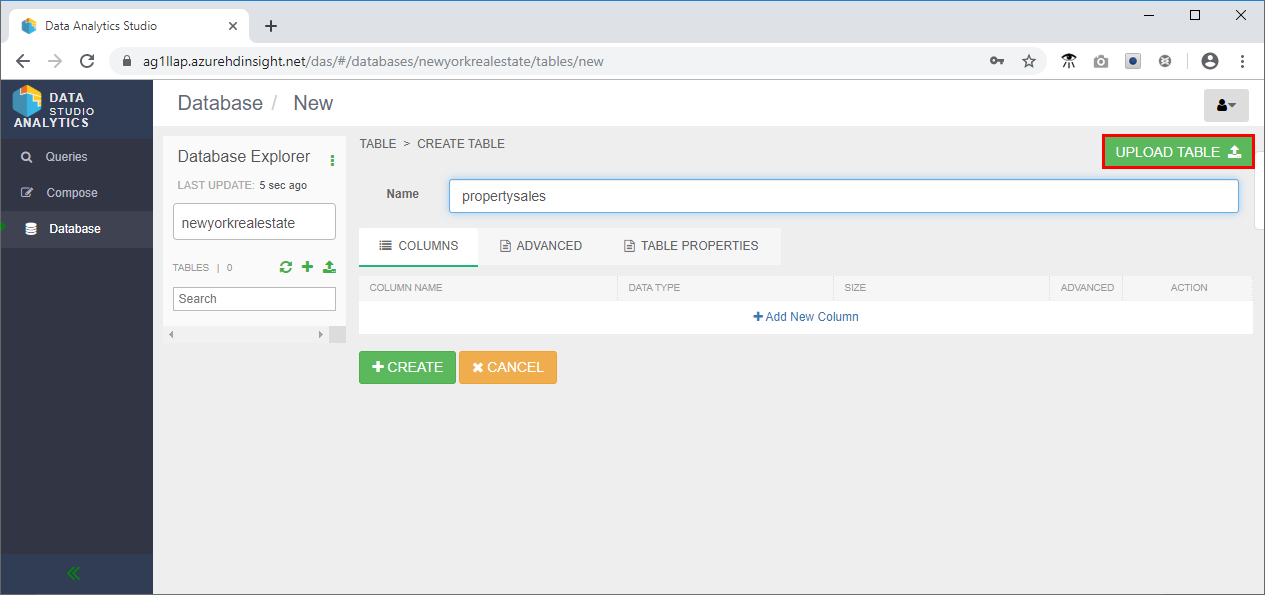
- I avsnittet Kolumner ändrar du datatypen latitud och longitud till Sträng och Försäljningsdatum till ett datum.
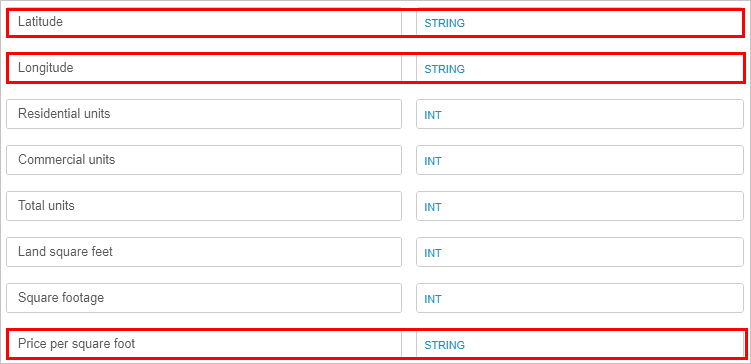
- Rulla uppåt och granska avsnittet Tabellförhandsgranskning för att verifiera att kolumnrubrikerna ser korrekta ut.
- Rulla hela vägen ned och klicka på Skapa för att skapa Hive-tabellen i databasen newyorkrealestate.

- I den vänstra menyn klickar du på Skriv.
- Prova följande Hive-fråga för att se till att allt fungerar som förväntat.
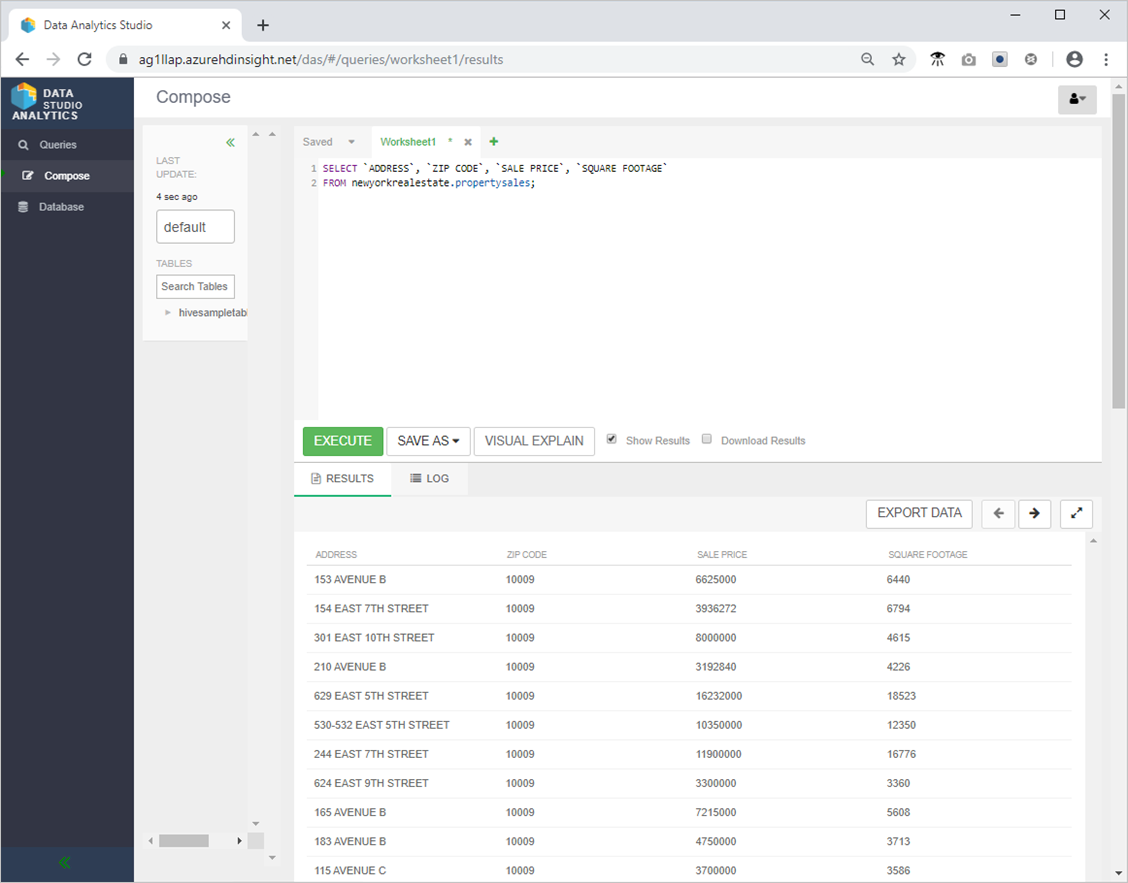
SELECT `ADDRESS`, `ZIP CODE`, `SALE PRICE`, `SQUARE FOOTAGE`
FROM newyorkrealestate.propertysales;
- Utdata bör se ut ungefär så här.
- Granska frågans prestanda genom att klicka på Frågor på den vänstra menyn och sedan välja frågan SELECT
ADDRESS,ZIP CODE,SALE PRICE,SQUARE FOOTAGEFROM newyorkrealestate.propertysales som du precis körde.
Om det fanns några tillgängliga prestandarekommendationer skulle verktyget visa dessa rekommendationer. Den här sidan visar även den faktiska SQL-frågan som kördes, ger en visuell förklaring av frågan, visar konfigurationsinformationen som hive härledde när frågan kördes och en ger en tidslinje som visar hur mycket tid som spenderades på att köra varje del av frågan.
Utforska Hive-tabellerna med en Zeppelin-notebook-fil
- I Azure-portalen går du till sidan Översikt och klickar på Zeppelin Notebook i rutan Klusterinstrumentpanel.
- Klicka på Ny anteckning, ge anteckningen namnet Real Estate Data och klicka sedan på Skapa.
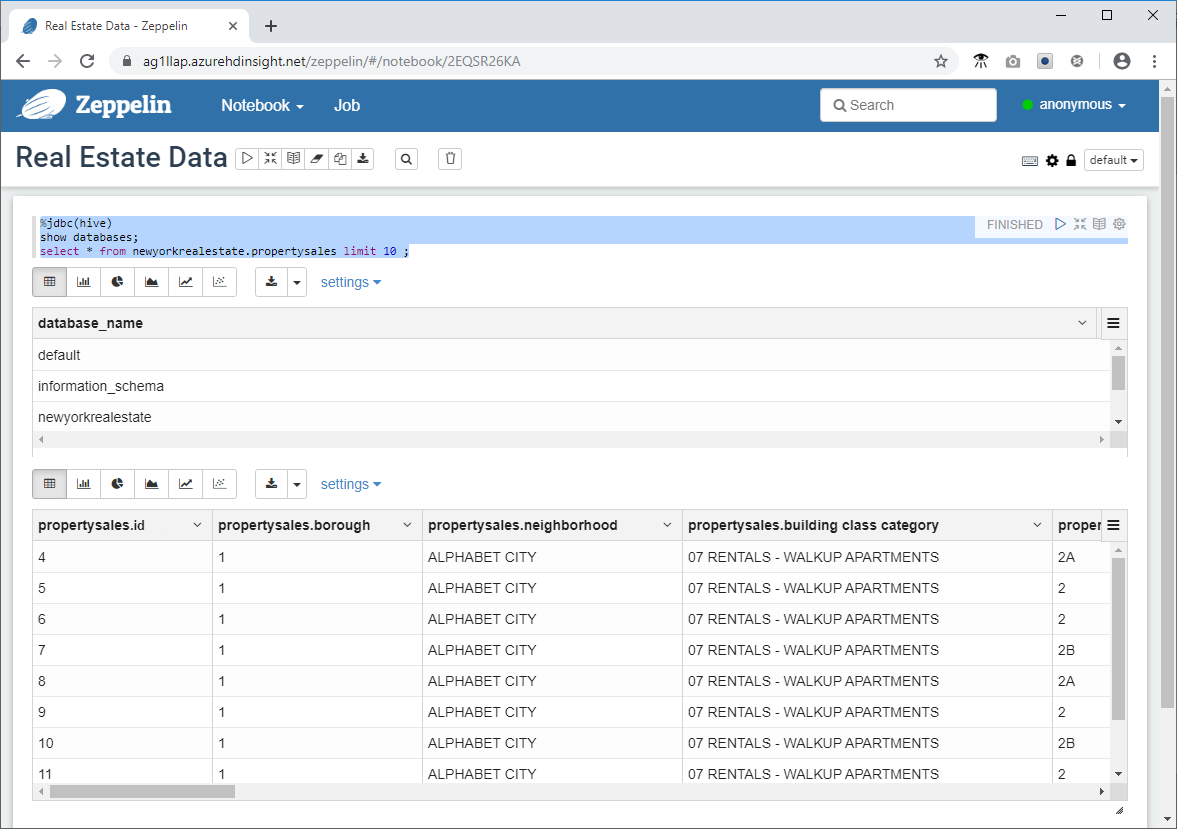
- Klistra in följande kodfragment i kommandotolken i Zeppelin-fönstret och klicka på uppspelningsikonen.
%jdbc(hive)
show databases;
select * from newyorkrealestate.propertysales limit 10 ;
Frågeutdata visas i fönstret. Du kan se att de första 10 resultaten returneras.
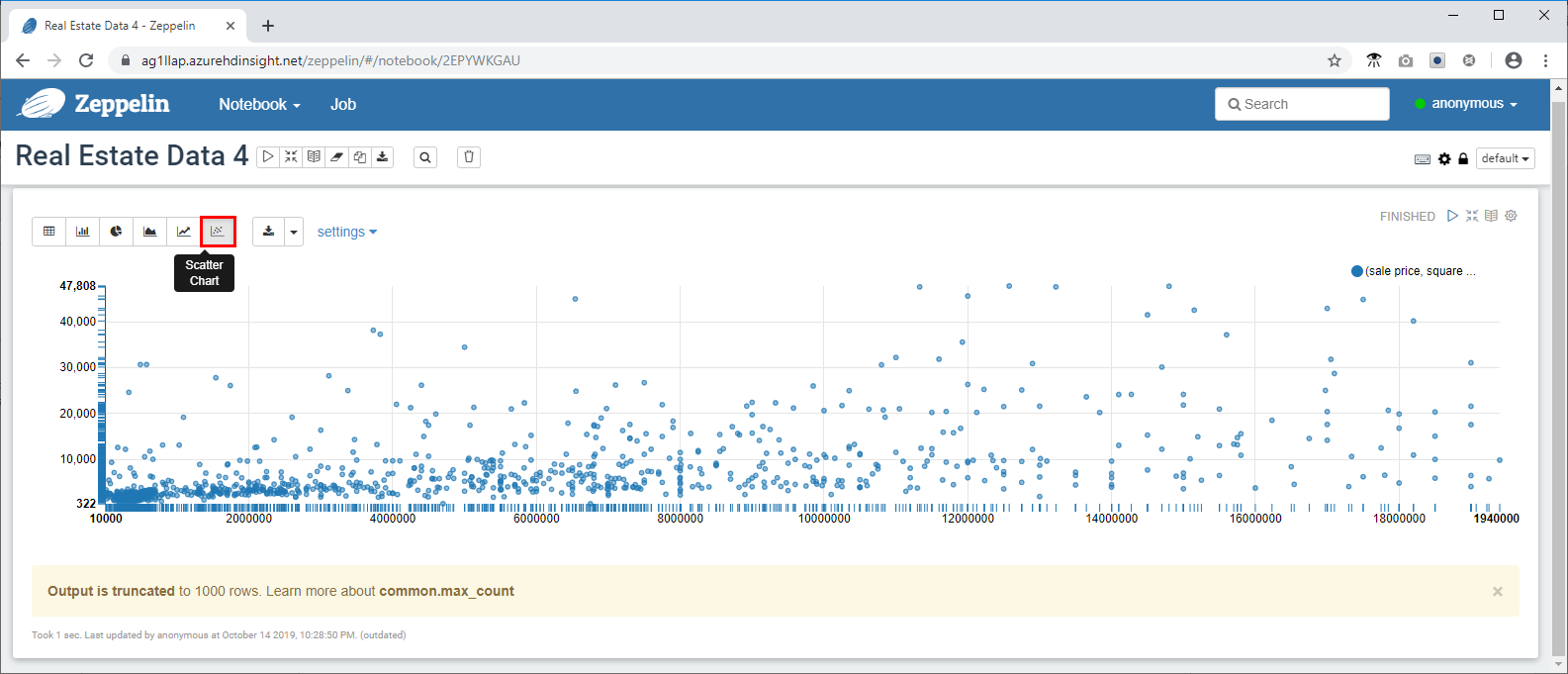
- Starta nu en mer komplex fråga för att använda några av de visualiserings- och graffunktioner som är tillgängliga i Zeppelin. Kopiera följande fråga till kommandotolken och klicka på .
%jdbc(hive)
select `sale price`, `square footage` from newyorkrealestate.propertysales
where `sale price` < 20000000 AND `square footage` < 50000;
Som standard visas frågeutdata i tabellformat. Välj i stället Punktdiagram för att se ett av de visuella objekt som zeppelin-notebook-filerna innehåller.