När ska du använda HDInsight Interaktiv fråga?
Som affärsanalytiker måste du fastställa den lämpligaste typen av HDInsight-kluster att skapa för att skapa din lösning. Interaktiv fråga kluster tillhandahåller ett antal funktioner och samverkansalternativ som gör det unikt fördelaktigt för affärsanalytiker som är bekanta med SQL. Det är bra för användare som vill arbeta med Business Intelligence-verktyg och som behöver snabba interaktiva frågor. Det finns andra fördelar, till exempel stöd för en rad olika filformat, samtidighet och atomic-, konsekventa, isolerade och varaktiga (ACID) transaktioner. För att inte tala om integrering med Apache Ranger för detaljerad kontroll på rad- och kolumnnivå över data.
Kommentar
Innehållet i den här modulen gäller Interaktiv fråga kluster som skapats för HDInsight 4.0, som använder Hive 3.1 och LLAP, även kallat Hive LLAP.
Du har en stor datauppsättning som är redo att frågas
Interaktiv fråga kluster passar bäst för stora datamängder som kan efterfrågas som de är, eller med minimala omvandlingar. Situationer där du utför en mängd olika frågor på data och du behöver omedelbara svar. Interaktiv fråga kluster är inte optimerade för att utföra långvariga batchberäkningar. Interaktiv fråga stöder följande filformat: ORC, Parquet, CSV, Avro, JSON, text och tsv.
Du behöver SQL-liknande funktioner
När du behöver köra interaktiva och ad hoc-frågor under andra svarstiden på stordata som du har i Azure Storage och Azure Data Lake Storage, och du föredrar en SQL-liknande upplevelse, är Azure HDInsight Interaktiv fråga kluster ett utmärkt val. Som affärsanalytiker är du mycket bekant med SQL-tabeller och skapar frågor med hjälp av SQL. Apache Hadoop är ett kraftfullt verktyg för att utföra stordataanalys. Apache Hadoops användning av MapReduce-ramverket och dess Java-API:er kan vara en blockerare för dig om dina Java-programmeringskunskaper är lite rostiga. I det här fallet passar HDInsight Interaktiv fråga bättre eftersom det är byggt ovanpå Apache Hadoop men är enklare för alla med SQL-erfarenhet att använda. Interaktiv fråga använder SQL-liknande Hive-tabeller för att bearbeta data och ett SQL-liknande frågespråk med namnet HiveQL för att fråga efter data. Att använda Hive är mindre komplext än att bearbeta data med Hjälp av MapReduce i Apache Hadoop. Hive gör det snabbare och effektivare att distribuera lösningar till ditt företag.
Snabba interaktiva frågor med intelligent cachelagring
Interaktiv fråga kluster använder intelligenta cachelagringstekniker för att nivåindela data i dynamiskt RAM-minne, SSD för lokala klusternoder och fjärrlagringssystem som Azure Blob och Azure Data Lake Storage för att uppnå interaktiva och snabba frågeresultat över stordata. Ett bra exempel på avancerad cachelagringsteknik är dynamisk textcache, som konverterar CSV-data till ett optimerat minnesinternt format direkt, så cachelagring är dynamiskt och frågorna avgör vilka data som cachelagras. Den här funktionen innebär att du inte behöver läsa in och transformera dina data först. Du kan ladda upp data till Azure Storage i dess ursprungliga format och börja köra frågor mot dem. Och det innebär också att frågor är mer högpresterande andra gången de körs. Första gången en fråga körs läss data från lagringslagret för affärsdata i Azure Storage eller Azure Data Lake Gen2. Sedan cachelagras data till det delade minnesinterna cacheminnet i klustret. Nästa gång frågan körs hämtas data helt enkelt från den delade minnesinterna cachen och du sparar tid genom att inte hämta data från fjärrlagringslagret.
Köra frågor med populära verktyg
Interaktiv fråga gör det enkelt att arbeta med stordata med hjälp av BI-verktyg som du är bekant med, till exempel Microsoft Power BI och Tableau. I stordataanalyser är organisationer alltmer oroade över att slutanvändarna inte får ut tillräckligt med värde från analyssystemen eftersom det ofta är för utmanande och kräver att man använder okända och svårlärda verktyg för att köra analyserna. HDInsight Interaktiv fråga åtgärdar det här problemet genom att kräva minimal eller ingen ny användarutbildning för att få insikter från data. Användare kan skriva SQL-liknande HiveQL-frågor i de verktyg som de redan använder. Dessa verktyg inkluderar Visual Studio Code, Power BI, Apache Zeppelin, Visual Studio, Ambari Hive View, Beeline, Data Analytics Studio och Hive ODBC. Du kan inte köra frågor i ditt Interaktiv fråga kluster med Hive-konsolen, Templeton, Azure Classic CLI eller Azure PowerShell.
Du behöver transaktionskonsekvens och samtidighet
Med introduktionen av detaljerad resurshantering, förebyggande och delning av cachelagrade data mellan frågor och användare stöder Interaktiv fråga enkelt samtidiga användare. HDInsight har stöd för att skapa flera kluster på delad Azure-lagring. Hive-metaarkiv hjälper till att uppnå en hög grad av samtidighet. Du kan skala samtidigheten genom att lägga till fler klusternoder eller genom att lägga till fler kluster som pekar på samma underliggande data och metadata. Interaktiv fråga stöder även databastransaktioner som är Atomic, Consistent, Isolated och Durable (ACID). ACID-transaktioner garanterar att en transaktion, även om den innehåller flera åtgärder, finns i en enda enhet. Om en enskild åtgärd i transaktionen misslyckas kan alltså hela åtgärden återställas, vilket håller data konsekventa och korrekta.
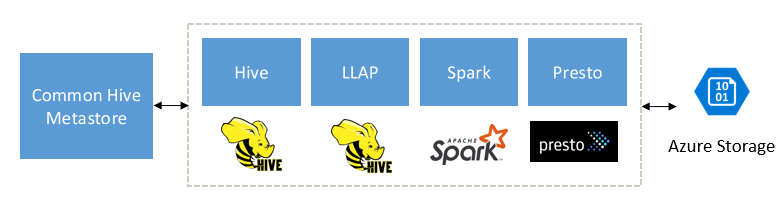
Byggd för att komplettera Spark, Hive, Presto och andra stordatamotorer
HDInsight Interactive-frågan är utformad för att fungera bra med populära stordatamotorer som Apache Spark, Hive, Presto med mera. Den här typen av fråga är särskilt användbar eftersom användarna kan välja något av dessa verktyg för att köra sin analys. Med HDInsights delade data- och metadataarkitektur för externa tabeller kan användare skapa flera kluster med samma eller annan motor som pekar på samma underliggande data och metadata. Den här funktionen är ett kraftfullt begrepp eftersom du inte längre begränsas av en teknik för analys.