Replikera data till ett sekundärt kluster
Kafka distribueras ofta i flera miljöer för haveriberedskap, hög tillgänglighet och lokala hybridscenarier i molnet. Dessa scenarier kräver replikering av data från en Kafka-instans till en annan med hjälp av Apache Kafkas speglingsfunktion. Spegling kan köras som en kontinuerlig process eller användas tillfälligt som en metod för att migrera data från ett kluster till ett annat.
Spegling bör inte betraktas som ett sätt att uppnå feltolerans. Förskjutningen till objekt i ett ämne skiljer sig mellan de primära och sekundära klustren, så klienterna kan inte använda de två omväxlande.
Hur fungerar spegling?
Spegling fungerar med verktyget MirrorMaker (en del av Apache Kafka) för att använda poster från ämnen i det primära klustret och sedan skapa en lokal kopia på det sekundära klustret. MirrorMaker använder en eller flera konsumenter som läser från det primära klustret och en producent som skriver till det lokala sekundära klustret.
Den mest användbara speglingskonfigurationen för haveriberedskap använder Kafka-kluster i olika Azure-regioner. För att uppnå detta peer-kopplas de virtuella nätverken där klustren finns ihop.
Följande diagram illustrerar speglingsprocessen och hur kommunikationen flödar mellan kluster:
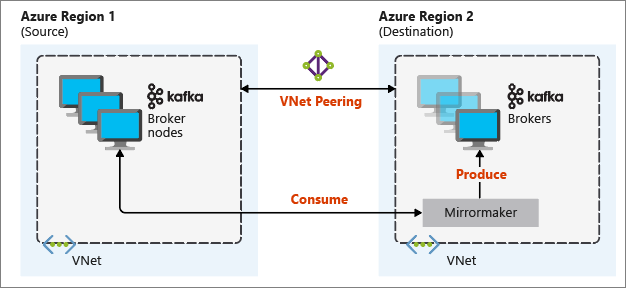
De primära och sekundära klustren kan skilja sig åt i antalet noder och partitioner, och förskjutningar i ämnena är också olika. Spegling underhåller nyckelvärdet som används för partitionering, så postordningen bevaras per nyckel.
Spegling över nätverksgränser
Om du behöver spegla mellan Kafka-kluster i olika nätverk finns följande ytterligare överväganden:
- Gatewayer: Nätverken måste kunna kommunicera på TCP/IP-nivå.
- Serveradressering: Du kan välja att adressera dina klusternoder med hjälp av deras IP-adresser eller fullständigt kvalificerade domännamn.
- IP-adresser: Om du konfigurerar dina Kafka-kluster att använda IP-adressannonsering kan du fortsätta med speglingskonfigurationen med ip-adresserna för asynkrona noder och zookeeper-noder.
- Domännamn: Om du inte konfigurerar dina Kafka-kluster för IP-adressannonsering måste klustren kunna ansluta till varandra med hjälp av fullständigt kvalificerade domännamn (FQDN). Detta kräver en DNS-server (Domain Name System) i varje nätverk som är konfigurerat för att vidarebefordra begäranden till de andra nätverken. När du skapar ett virtuellt Azure-nätverk måste du i stället för att använda den automatiska DNS som medföljer nätverket ange en anpassad DNS-server och IP-adressen för servern. När det virtuella nätverket har skapats måste du sedan skapa en virtuell Azure-dator som använder ip-adressen och sedan installera och konfigurera DNS-programvara på den.
Varning
Skapa och konfigurera den anpassade DNS-servern innan du installerar HDInsight i det virtuella nätverket. Det krävs ingen ytterligare konfiguration för att HDInsight ska kunna använda DEN DNS-server som konfigurerats för det virtuella nätverket.