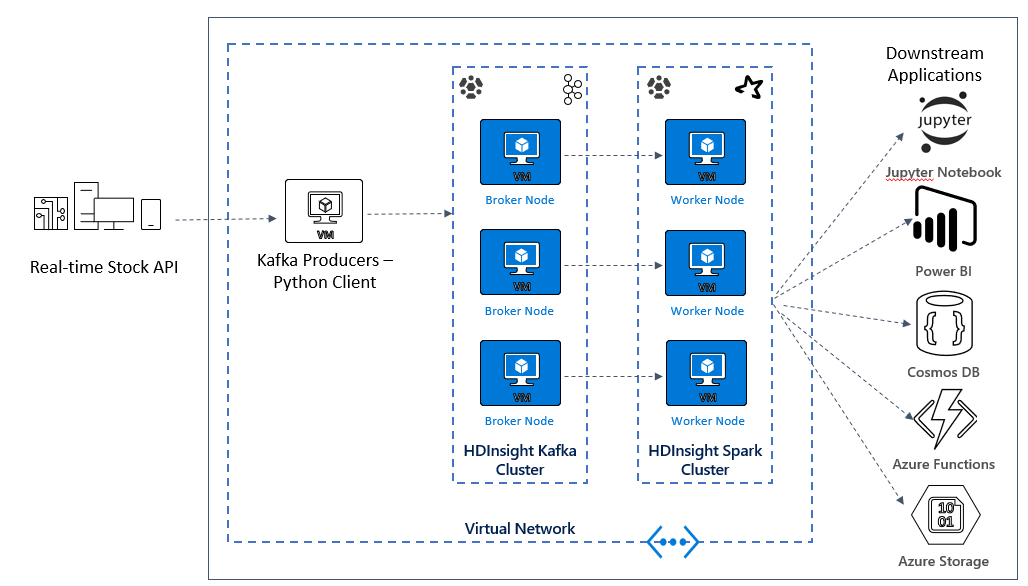
Skapa en Kafka- och Spark-arkitektur
Om du vill använda Kafka och Spark tillsammans i Azure HDInsight måste du placera dem i samma virtuella nätverk eller peer-koppla de virtuella nätverken så att klustren fungerar med DNS-namnmatchning.
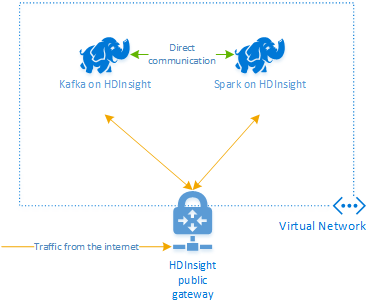
Så här skapar du kluster i samma virtuella nätverk:
- Skapa en resursgrupp
- Lägga till ett virtuellt nätverk i resursgruppen
- Lägg till ett Kafka-kluster och ett Spark-kluster i samma virtuella nätverk eller peer-koppla de virtuella nätverk där tjänsterna fungerar med DNS-namnmatchning.
Det rekommenderade sättet att ansluta HDInsight Kafka- och Spark-klustret är den interna Spark-Kafka-anslutningsappen, som gör det möjligt för Spark-klustret att komma åt enskilda partitioner av data i Kafka-klustret, vilket ökar parallelliteten som du har i realtidsbearbetningsjobbet och ger mycket högt dataflöde.
När båda klustren finns i samma virtuella nätverk kan du också använda Kafka Broker FQDN i Spark-strömningskoden och du kan skapa NSG-regler på det virtuella nätverket för företagssäkerhet.
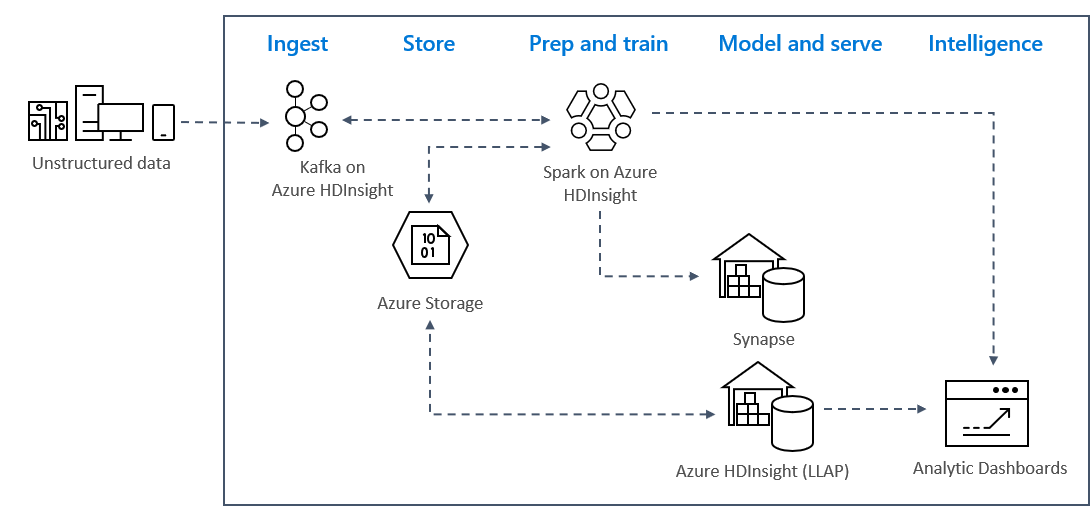
Lösningsarkitekturen
Strömningsanalysmönster i realtid i Azure använder vanligtvis följande lösningsarkitektur.
- Inmatning: Ostrukturerade eller strukturerade data matas in i ett Kafka-kluster i Azure HDInsight.
- Förberedelse och träning: Data är förberedda och tränade med Spark på HDInsight.
- Modell och tjänst: Data placeras i ett informationslager som Azure Synapse eller HDInsight Interaktiv fråga.
- Intelligens: Data hanteras på analysinstrumentpanelen, till exempel Power BI eller Tableau.
- Lagra: Data placeras i en lösning för kall lagring, till exempel Azure Storage, och hanteras senare.
Exempelscenarioarkitektur
I nästa lektion börjar du skapa lösningsarkitekturen för exempelprogrammet. Det här exemplet använder en Azure Resource Manager-mallfil för att skapa resursgruppen, det virtuella nätverket, Spark-klustret och Kafka-klustret.
När klustren har distribuerats hamnar du i en av Kafka-mäklarna och kopierar Python-producentfilen till huvudnoden. Den producentfilen ger artificiella aktiekurser var 10:e sekund, den skriver även partitionsnumret och förskjutningen av meddelandet till konsolen.
När producenten har körts kan du ladda upp Jupyter Notebook till Spark-klustret. I notebook-filen ansluter du Spark- och Kafka-kluster och kör några exempelfrågor på data, inklusive att hitta höga och låga värden för ett lager i ett händelsefönster.