Beskriva Strukturerad Spark-strömning
Spark-strukturerad direktuppspelning är en populär plattform för minnesintern bearbetning. Den har ett enhetligt paradigm för batch- och strömning. Allt du lär dig och använder för batch kan du använda för strömning, så det är enkelt att växa från batchbearbetning av dina data till att strömma dina data. Spark Streaming är helt enkelt en motor som körs ovanpå Apache Spark.

Strukturerad direktuppspelning skapar en tidskrävande fråga där du tillämpar åtgärder på indata, till exempel val, projektion, aggregering, fönster och anslutning till strömmande DataFrame med referensdataramar. Därefter matar du ut resultatet till fillagring (Azure Storage Blobs eller Data Lake Storage) eller till ett datalager med hjälp av anpassad kod (till exempel SQL Database eller Power BI). Strukturerad direktuppspelning ger också utdata till konsolen för felsökning lokalt och till en minnesintern tabell så att du kan se de data som genereras för felsökning i HDInsight.
Strömmar som tabeller
Spark-strukturerad direktuppspelning representerar en dataström som en tabell som är obundna på djupet, dvs. tabellen fortsätter att växa när nya data tas emot. Den här indatatabellen bearbetas kontinuerligt av en tidskrävande fråga och resultaten skickas till en utdatatabell:

I Strukturerad direktuppspelning anländer data till systemet och matas omedelbart in i en indatatabell. Du skriver frågor (med hjälp av API:er för DataFrame och datauppsättning) som utför åtgärder mot den här indatatabellen. Frågeutdata ger en annan tabell, resultattabellen. Resultattabellen innehåller resultatet av din fråga, från vilken du ritar data för ett externt datalager, till exempel en relationsdatabas. Tidpunkten för när data bearbetas från indatatabellen styrs av utlösarintervallet. Som standard är utlösarintervallet noll, så Structured Streaming försöker bearbeta data så snart de kommer. I praktiken innebär det att så fort structured Streaming är klar med bearbetningen av körningen av den föregående frågan startar den en annan bearbetningskörning mot nyligen mottagna data. Du kan konfigurera utlösaren så att den körs med ett intervall, så att strömmande data bearbetas i tidsbaserade batchar.
Data i resultattabellerna kan bara innehålla data som är nya sedan den senaste gången frågan bearbetades (tilläggsläge), eller så kan tabellen uppdateras varje gång det finns nya data så att tabellen innehåller alla utdata sedan den strömmande frågan började (fullständigt läge).
Tilläggsläge
I tilläggsläge finns endast de rader som lagts till i resultattabellen sedan den senaste frågekörningen i resultattabellen och skrivs till extern lagring. Den enklaste frågan kopierar till exempel bara alla data från indatatabellen till resultattabellen oförändrad. Varje gång ett utlösarintervall förflutit bearbetas de nya data och raderna som representerar dessa nya data visas i resultattabellen.
Tänk dig ett scenario där du bearbetar aktiekursdata. Anta att den första utlösaren bearbetade en händelse vid tidpunkten 00:01 för MSFT-lager med ett värde på 95 dollar. I den första utlösaren av frågan visas endast raden med tid 00:01 i resultattabellen. Vid tidpunkten 00:02 när en annan händelse kommer är den enda nya raden raden med tid 00:02 och därför innehåller resultattabellen bara den raden.
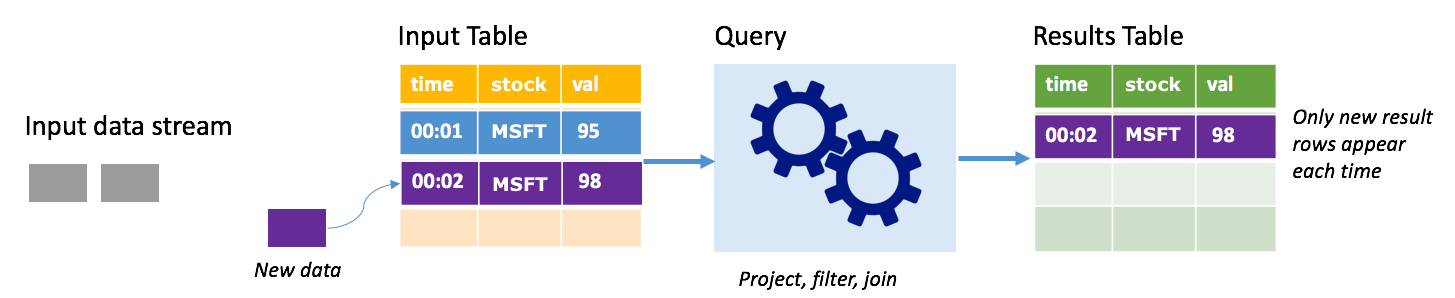
När du använder tilläggsläget använder frågan projektioner (väljer de kolumner som den bryr sig om), filtrerar (väljer endast rader som matchar vissa villkor) eller ansluter (utökar data med data från en statisk uppslagstabell). Tilläggsläget gör det enkelt att endast push-överföra relevanta nya data till extern lagring.
Fullständigt läge
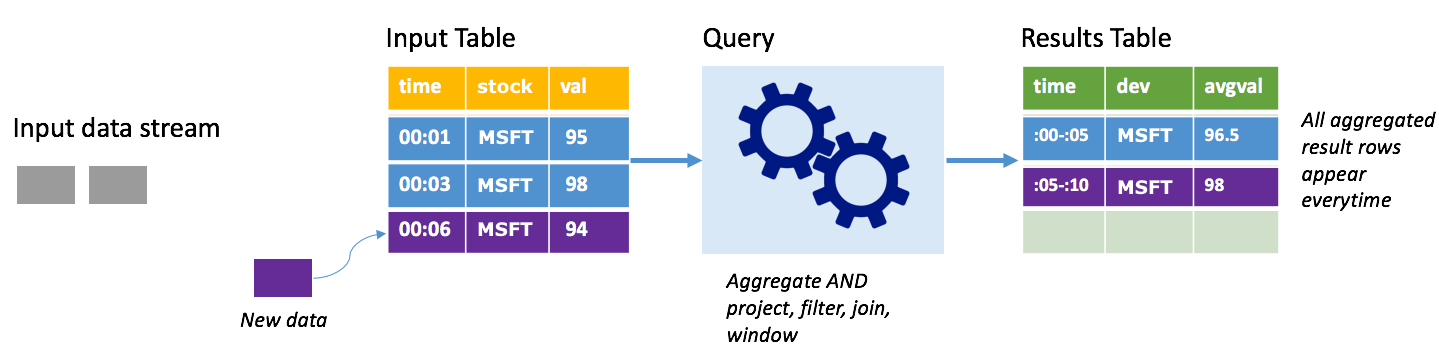
Tänk på samma scenario, den här gången med fullständigt läge. I fullständigt läge uppdateras hela utdatatabellen på varje utlösare, så tabellen innehåller data inte bara från den senaste utlösarkörningen, utan från alla körningar. Du kan använda fullständigt läge för att kopiera data som inte har upphöjts från indatatabellen till resultattabellen. På varje utlöst körning visas de nya resultatraderna tillsammans med alla föregående rader. Resultattabellen för utdata kommer att lagra alla data som samlats in sedan frågan började, och du skulle så småningom få slut på minne. Fullständigt läge är avsett för användning med aggregerade frågor som sammanfattar inkommande data på något sätt, så vid varje utlösare uppdateras resultattabellen med en ny sammanfattning.
Anta att det hittills finns fem sekunders data som redan har bearbetats och att det är dags att bearbeta data för den sjätte sekunden. Indatatabellen har händelser för tid 00:01 och tid 00:03. Målet med den här exempelfrågan är att ge aktiens genomsnittliga pris var femte sekund. Implementeringen av den här frågan tillämpar en aggregering som tar alla värden som faller inom varje 5-sekundersfönster, medelvärder aktiekursen och genererar en rad för den genomsnittliga aktiekursen under det intervallet. I slutet av det första 5-sekundersfönstret finns det två tupplar: (00:01, 1, 95) och (00:03, 1, 98). Så för fönstret 00:00-00:05 producerar aggregeringen en tuppeln med den genomsnittliga aktiekursen på $ 96.50. I nästa 5-sekundersfönster finns det bara en datapunkt vid tidpunkten 00:06, så den resulterande aktiekursen är $ 98. Vid tidpunkten 00:10, med fullständigt läge, har resultattabellen raderna för både windows 00:00-00:05 och 00:05-00:10 eftersom frågan matar ut alla aggregerade rader, inte bara de nya. Därför fortsätter resultattabellen att växa när nya fönster läggs till.
Det är inte alla frågor som använder fullständigt läge som gör att tabellen växer utan gränser. Tänk på i föregående exempel att i stället för att medelvärdet av aktiekursen per fönster, det genomsnitt i stället efter lager. Resultattabellen innehåller ett fast antal rader (en per lager) med den genomsnittliga aktiekursen för lagren över alla datapunkter som tas emot från den enheten. När nya aktiekurser tas emot uppdateras resultattabellen så att medelvärdena i tabellen alltid är aktuella.
Vilka är fördelarna med Strukturerad Spark-strömning?
När det gäller finanssektorn är tidpunkten för transaktioner mycket viktig. Till exempel i en aktiehandel, skillnaden mellan när aktiehandeln sker på aktiemarknaden, eller när du får transaktionen, eller när data läss alla frågor. För finansinstitut är de beroende av dessa kritiska data och tidpunkten som är associerad med dem.
Händelsetid, sena data och vattenstämpling
Spark-strukturerad strömning vet skillnaden mellan en händelsetid och den tid då händelsen bearbetades av systemet. Varje händelse är en rad i tabellen och händelsetid är ett kolumnvärde på raden. Detta gör att fönsterbaserade aggregeringar (till exempel antalet händelser varje minut) bara är en gruppering och aggregering i kolumnen händelsetid – varje tidsfönster är en grupp och varje rad kan tillhöra flera fönster/grupper. Därför kan sådana event-time-window-baserade aggregeringsfrågor definieras konsekvent både på en statisk datauppsättning och på en dataström, vilket gör datateknikerns livslängd mycket enklare.
Dessutom hanterar den här modellen naturligt data som har kommit senare än förväntat baserat på dess händelsetid. Spark har fullständig kontroll över uppdatering av gamla aggregeringar när det finns sena data, samt rensar upp gamla aggregeringar för att begränsa storleken på mellanliggande tillståndsdata. Eftersom Spark 2.1 dessutom stöder vattenstämpling, vilket gör att du kan ange tröskelvärdet för sena data, och gör att motorn kan rensa det gamla tillståndet.
Flexibilitet att ladda upp senaste data eller alla data
Som vi nämnde i föregående lektion kan du välja att använda tilläggsläge eller slutfört läge när du arbetar med Spark-strukturerad direktuppspelning, så att resultattabellen endast innehåller de senaste data eller alla data.
Stöd för att flytta från mikrobatch till kontinuerlig bearbetning
Genom att ändra utlösartypen för en Spark-fråga kan du gå från bearbetning av mikrobatch till kontinuerlig bearbetning utan andra ändringar i ramverket. Här är de olika typer av utlösare som Spark stöder.
- Ospecificerat är detta standardvärdet. Om ingen utlösare anges uttryckligen körs frågan i mikrobatcherna och bearbetas kontinuerligt.
- Mikrobatch med fast intervall. Frågan startas med återkommande intervall som angetts av användaren. Om inga nya data tas emot körs ingen mikrobatchprocess.
- Engångsmikrobatch. Frågan kör en enskild mikrobatch och stoppas sedan. Det här är användbart om du vill bearbeta alla data sedan den tidigare mikrobatchen och kan ge kostnadsbesparingar för jobb som inte behöver köras kontinuerligt.
- Kontinuerlig med ett fast kontrollpunktsintervall. Frågan körs i ett nytt läge med låg svarstid och kontinuerlig bearbetning som möjliggör låg (~1 ms) svarstid från slutpunkt till slutpunkt med garantier för feltolerans minst en gång. Detta liknar standardvärdet, som kan uppnå exakt en gång-garantier men endast uppnår svarstider på ~100 ms i bästa fall.
Kombinera batch- och strömningsjobb
Förutom att förenkla övergången från batch till direktuppspelningsjobb kan du även kombinera batch- och strömningsjobb. Detta är särskilt användbart när du vill använda långsiktiga historiska data för att förutsäga framtida trender vid bearbetning av realtidsinformation. För aktier kanske du vill titta på aktiens pris under de senaste 5 åren utöver det aktuella priset, för att förutsäga ändringar som gjorts runt årliga eller kvartalsvisa intäktsmeddelanden.
Händelsetidsfönster
Du kanske vill samla in data i fönster, till exempel ett högt aktiekurs och en låg aktiekurs inom ett endagsfönster eller en minuts fönster – oavsett vilket intervall du väljer, och Spark-strukturerad strömning stöder det också. Överlappande fönster stöds också.
Kontrollpunkter för återställning av fel
Om det uppstår ett fel eller en avsiktlig avstängning kan du återställa föregående förlopp och tillstånd för en tidigare fråga och fortsätta där den slutade. Detta görs med hjälp av kontrollpunkts- och skrivföregångsloggar. Du kan konfigurera en fråga med en kontrollpunktsplats och frågan sparar all förloppsinformation (dvs. intervall med förskjutningar som bearbetas i varje utlösare) och de löpande aggregeringarna till kontrollpunktsplatsen. Den här kontrollpunktsplatsen måste vara en sökväg i ett HDFS-kompatibelt filsystem och kan anges som ett alternativ i DataStreamWriter när du startar en fråga.