Strömma data med Apache Kafka
Apache Kafka skapades av LinkedIn 2010, med målet att flytta data i mycket hög skala med mycket låg svarstid med hög feltoleransnivå. LinkedIn donerade sedan projektet till Apache Foundation 2012, men LinkedIn använder fortfarande Kafka i hela ekosystemet för att spåra användaraktivitet, utbyta meddelanden och samla in mått.
Kafka är en distribuerad strömningsplattform som har utformats för att:
- Förenkla datapipelines
- Hantera stora mängder data i ett strömningsmönster
- Stöd för realtids- och batchsystem
- Skala horisontellt
Låt oss först lära oss om ren Apache Kafka, sedan om Kafka i Azure HDInsight.
Kafka-komponenter
Innan vi förstår hur Kafka fungerar ska vi titta på rollerna för några av de viktigaste komponenterna i Kafka och hur de samlas för att tillhandahålla ett mycket skalbart och feltolerant meddelandesystem.
Broker
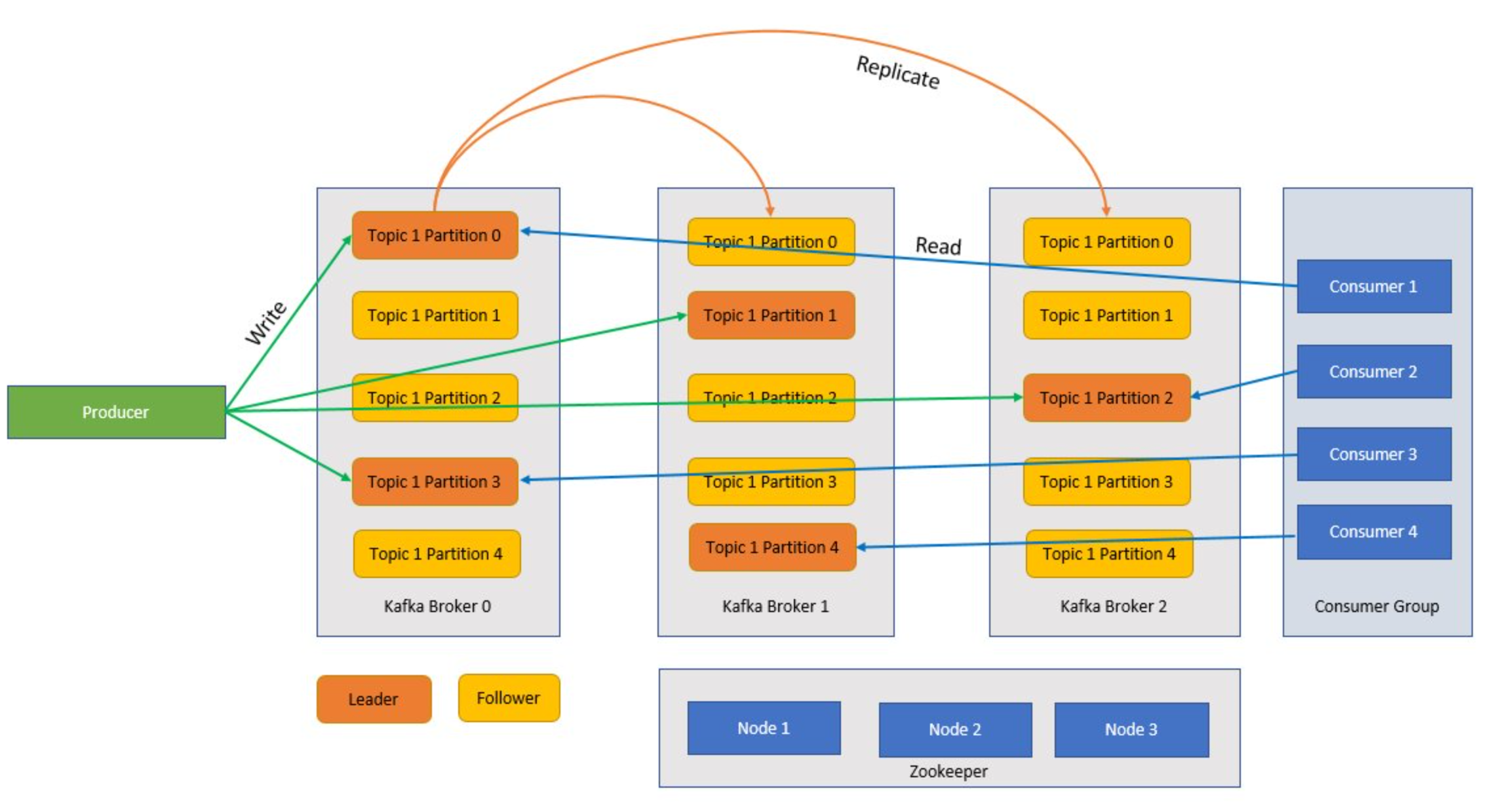
Kafka är en klustrad tjänst och ett enda Kafka-kluster kallas även för asynkron meddelandekö. Koordinatorer tar emot meddelanden från producenter och lagrar dessa meddelanden på disk. Asynkron meddelandekö svarar också på hämtning av begäranden från konsumenter. I ett kluster med asynkrona koordinatorer fungerar en koordinator som kontrollant och ansvarar för administrativa åtgärder och tilldelar partitioner till asynkrona koordinatorer.
Meddelande
En dataenhet i ett Kafka-kluster. Meddelanden i de flesta instanser är nyckelvärdepar.
Ämnen och partitioner
Ämnen och partitioner är kategorier av meddelanden i Kafka. Ämnen är vanligtvis uppdelade i ett antal partitioner att förbättra hela, med ett rekommenderat minimum av tre partitioner. Meddelanden skrivs till en ämnespartition på ett tilläggssätt. Partitioner replikeras ytterligare över flera asynkrona koordinatorer för att förbättra redundansen i händelse av asynkrona fel. Med partitioner kan ämnen läsas parallellt eftersom de gör det möjligt att dela upp data mellan flera asynkrona koordinatorer. Det finns en ledarreplik som hanterar alla skrivskyddade begäranden och följarna replikeras från ledaren. Om en ledare misslyckas blir en av replikerna ledare.
Producenter och konsumenter
Producenter och konsumenter är de klienter som producerar och använder meddelanden från Kafka-systemet. Producenter publicerar nya meddelanden och dirigerar dem till ett specifikt ämne. Konsumenter kan också utformas för att skriva till en specifik ämnespartition. Konsumenter prenumererar i sin tur på ett eller flera ämnen och läser meddelanden från dessa ämnen.
Konsumentgrupp
En eller flera konsumenter kan arbeta tillsammans som en grupp och använda meddelanden som en grupp. Om antalet konsumenter är lika med antalet ämnespartitioner förbrukar varje konsument från en enskild ämnespartition som skapar parallellitet.
Kvarhållning
Meddelanden i Kafka kan behållas korrekt i Kafka-klustret under en fördefinierad tidsperiod. När kvarhållningsgränserna har nåtts kan Kafka upphöra att gälla och ta bort dessa meddelanden.
Förskjutning
En förskjutning är helt enkelt positionen för ett meddelande i en partition. Att uppdatera den aktuella positionen i en partition när meddelanden bearbetas kallas för en incheckning. När ett meddelande har bearbetats checkar Kafka in meddelandets förskjutning till ett särskilt internt Kafka-ämne. När en producent publicerar ett meddelande till en partition vidarebefordras det till ledaren. Ledaren lägger till meddelandet i incheckningsloggen och ökar meddelandeförskjutningen. Meddelandeförskjutningen är hur meddelanden identifieras i ämnet. Meddelandet är endast tillgängligt för konsumenten när meddelandet har checkats in i klustret.
Zookeeper
Zookeeper är en samordningstjänst och i ett Kafka-kluster ger Zookeeper en synkroniserad vy över klustrets tillstånd. Kafka använder Zookeeper för val av ledare bland mäklare och ämnespartitioner. Kafka använder Zookeeper för att hantera tjänstidentifiering för Kafka-mäklare som utgör klustret. Zookeeper skickar ändringar av topologin till Kafka, så varje nod i klustret vet när en ny asynkron meddelandekö har anslutits, en mäklare dog, ett ämne togs bort eller ett ämne lades till.
Hur går allt ihop?
Program (även kallade producenter) skickar meddelanden till en Kafka-asynkron meddelandekö och dessa meddelanden bearbetas av en eller flera konsumenter. Meddelanden i ett kluster kategoriseras efter ämnen. En kund kan till exempel skapa ett "Sales"-ämne för att skicka alla meddelanden som är relevanta för försäljning och så vidare. När ämnena växer i storlek med ökande meddelanden delas de upp i partitioner och dessa partitioner replikeras ytterligare mellan Kafka-koordinatorer för redundans. Partitioner kategoriseras som ledare och följare. Den ledande partitionen skrivs till och läss från medan följarpartitionerna helt enkelt är repliker, vilket kommer ikapp ledarens tillstånd. För att avgöra vilken partition som ska skrivas till och läsas från måste producenter och konsumenter veta vilka partitioner som är utformade ledare. Zookeeper-noder hanterar tillståndet i Kafka-klustret och väljer bland annat partitionsledare och tillhandahåller den här informationen till producenter och konsumenter.
Kafka ger garantier för att meddelanden med en partition sorteras i samma sekvens som de kom in i. Ett specifikt meddelande kan identifieras tydligt via dess förskjutning, vilket är dess position inom en partition. Konsument läser meddelanden från partitioner och efter bearbetning, checkar in förskjutningen som anger att meddelandet har bearbetats. Kafka lagrar alla sina poster på disken och upprätthåller meddelandebeständighet. Om konsumenten avbryts av någon anledning och bearbetningen stoppas behåller Kafka dessa meddelanden under en fördefinierad kvarhållningsperiod och efter att ha kommit tillbaka online kan konsumenten starta om bearbetningen från den bekräftade förskjutningen där den slutade före avbrottet.
Kafka-ämnen
Ett Kafka-ämne är ett flöde eller en kö där meddelanden lagras och publiceras. Producenter skickar meddelanden till ämnen och konsumenter läser från ämnen. Varje nod i en Kafka-asynkron meddelandekö kan innehålla flera ämnen.
Vilka är fördelarna med Kafka i Azure HDInsight?
Kafka-versionen med öppen källkod erbjuder många funktioner, men det finns mycket arbete med att konfigurera den. Azure HDInsight ger Azure det bästa av analysramverk med öppen källkod och gör det enkelt för kunder att konfigurera sina kluster med öppen källkod inom några minuter, i stället för att lägga veckor eller månader på att konfigurera dessa kluster, och du kan använda dem direkt. HDInsight är också företagsklart med följande fördelar:
- Det är en hanterad tjänst som tillhandahåller en förenklad konfigurationsprocess. Resultatet är en konfiguration som har testats av och som stöds av Microsoft.
- Microsoft tillhandahåller ett serviceavtal på 99,9 % (SLA) på Spark och Kafka.
- Den använder hanterade diskar i Azure som lagringsenhet för Kafka. Hanterade diskar kan tillhandahålla upp till 16 TB lagringsutrymme per Kafka-mäklare, med flera Kafka-mäklare.
- HDInsight erbjuder bästa företagssäkerhet med virtuella nätverk, detaljerad säkerhet med Apache Ranger och BYOK-kryptering (Bring Your Own Key) för vilande data
- Efterlevnad för HIPAA, SOC och PCI
- Möjligheten att distribuera direktuppspelningspipelines från slutpunkt till slutpunkt med Spark och Storage via automatiserade ARM-mallar (Azure Resource Manager) i samma virtuella nätverk.
- Hög tillgänglighet kan uppnås med Kafka MirrorMaker, som kan använda poster från ämnen i det primära klustret och sedan skapa en lokal kopia på det sekundära klustret.
- I HDInsight kan du ändra antalet arbetarnoder (som är värdar för den asynkrona Kafka-meddelandekön) när klustret har skapats. Du kan utföra skalningen från Azure-portalen, Azure PowerShell och andra Azure-hanteringsgränssnitt. För Kafka bör du balansera om partitionsrepliker efter eventuell skalning. När du balanserar om partitionerna kan Kafka dra nytta av nya antalet arbetarnoder.
- Azure Monitor-loggar kan användas för att övervaka Kafka på HDInsight. Azure Monitor-loggarna innehåller information på virtuell datornivå, till exempel disk- och NIC-mått och JMX-mått från Kafka.