Välj rätt MPI-bibliotek
HB120_v2, HB60 och HC44 SKU:er stöder infiniBand-nätverksanslutningar. Eftersom PCI Express virtualiseras via SR-IOV-virtualisering (single-root input/output) är alla populära MPI-bibliotek (HPCX, OpenMPI, Intel MPI, MVAPICH och MPICH) tillgängliga på dessa virtuella HPC-datorer.
Den aktuella begränsningen för ett HPC-kluster som kan kommunicera via InfiniBand är 300 virtuella datorer. I följande tabell visas det maximala antalet parallella processer som stöds i nära kopplade MPI-program som kommunicerar via InfiniBand.
| SKU | Maximalt antal parallella processer |
|---|---|
| HB120_v2 | 36 000 processer |
| HC44 | 13 200 processer |
| HB60 | 18 000 processer |
Kommentar
Dessa gränser kan komma att ändras i framtiden. Om du har ett nära kopplat MPI-jobb som kräver en högre gräns skickar du en supportbegäran. Det kan vara möjligt att höja gränserna för din situation.
Om ett HPC-program rekommenderar ett visst MPI-bibliotek kan du prova den versionen först. Om du har flexibilitet när det gäller vilken MPI du kan välja och du vill ha bästa prestanda kan du prova HPCX. Sammantaget presterar HPCX MPI bäst genom att använda UCX-ramverket för InfiniBand-gränssnittet och dra nytta av alla Mellanox InfiniBand-maskinvaru- och programvarufunktioner.
Följande bild jämför de populära MPI-biblioteksarkitekturerna.
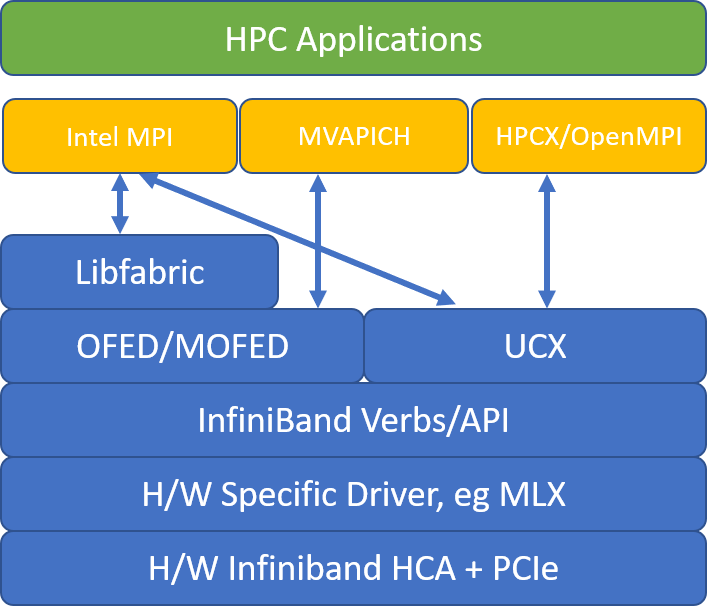
HPCX och OpenMPI är ABI-kompatibla, så du kan dynamiskt köra ett HPC-program med HPCX som har skapats med OpenMPI. På samma sätt är Intel MPI, MVAPICH och MPICH ABI-kompatibla.
Köparet 0 är inte tillgängligt för den virtuella gästdatorn för att förhindra säkerhetsrisker via maskinvaruåtkomst på låg nivå. Detta bör inte ha någon effekt på slutanvändarens HPC-program, men det kan förhindra att vissa lågnivåverktyg fungerar korrekt.
HPCX- och OpenMPI mpirun-argument
Följande kommando illustrerar några rekommenderade mpirun argument för HPCX och OpenMPI:
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
I det kommandot:
| Parameter | Description |
|---|---|
$NPROCS |
Anger antalet MPI-processer. Exempel: -n 16. |
$HOSTFILE |
Anger en fil som innehåller värdnamnet eller IP-adressen för att ange var MPI-processerna körs. Exempel: --hostfile hosts. |
$NUMBER_PROCESSES_PER_NUMA |
Anger antalet MPI-processer som körs i varje NUMA-domän. Om du till exempel vill ange fyra MPI-processer per NUMA använder --map-by ppr:4:numa:pe=1du . |
$NUMBER_THREADS_PER_PROCESS |
Anger antalet trådar per MPI-process. Om du till exempel vill ange en MPI-process och fyra trådar per NUMA använder --map-by ppr:1:numa:pe=4du . |
-report-bindings |
Skriver ut MPI-processer som mappas till kärnor, vilket är användbart för att kontrollera att MPI-processens fästning är korrekt. |
$MPI_EXECUTABLE |
Anger den körbara MPI-länkningen i MPI-bibliotek. MPI-kompilatoromslutningar gör detta automatiskt. Till exempel: mpicc eller mpif90. |
Om du misstänker att ditt nära kopplade MPI-program utför en överdriven mängd kollektiv kommunikation kan du prova att aktivera hierarkiska kollektiv (HCOLL). Om du vill aktivera dessa funktioner använder du följande parametrar:
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
Mpirun-argument för Intel MPI
Intel MPI 2019-versionen bytte från OFA-ramverket (Open Fabrics Alliance) till RAMVERKet Open Fabrics Interfaces (OFI) och stöder för närvarande libfabric. Det finns två providers för InfiniBand-stöd: mlx och verb. Providern mlx är den föredragna providern på virtuella HB- och HC-datorer.
Här följer några föreslagna mpirun argument för Intel MPI 2019-uppdatering 5+:
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
I dessa argument:
| Parametrar | beskrivning |
|---|---|
FI_PROVIDER |
Anger vilken libfabric-provider som ska användas, vilket påverkar DET API, protokoll och nätverk som används. verbs är ett annat alternativ, men ger dig i allmänhet mlx bättre prestanda. |
I_MPI_DEBUG |
Anger nivån för extra felsökningsutdata, som kan ge information om var processer fästs och vilket protokoll och nätverk som används. |
I_MPI_PIN_DOMAIN |
Anger hur du vill fästa dina processer. Du kan till exempel fästa på kärnor, socketar eller NUMA-domäner. I det här exemplet anger du miljövariabeln till numa, vilket innebär att processer fästs på NUMA-noddomäner. |
Det finns några andra alternativ som du kan prova, särskilt om kollektiva åtgärder förbrukar mycket tid. Intel MPI 2019 update 5+ stöder provide mlx och använder UCX-ramverket för att kommunicera med InfiniBand. Det stöder också HCOLL.
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
MVAPICH mpirun argument
Följande lista innehåller flera rekommenderade mpirun argument:
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
I dessa argument:
| Parametrar | beskrivning |
|---|---|
MV2_CPU_BINDING_POLICY |
Anger vilken bindningsprincip som ska användas, vilket påverkar hur processer fästs på kärn-ID:t. I det här fallet anger scatterdu , så att processerna är jämnt utspridda bland NUMA-domänerna. |
MV2_CPU_BINDING_LEVEL |
Anger var processer ska fästas. I det här fallet anger du det till numanode, vilket innebär att processer fästs på enheter i NUMA-domäner. |
MV2_SHOW_CPU_BINDING |
Anger om du vill hämta felsökningsinformation om var processerna fästs. |
MV2_SHOW_HCA_BINDING |
Anger om du vill få felsökningsinformation om vilket värdkanalkort varje process använder. |