Överväganden för att fästa processer
Varför fästa processer och trådar?
Fäst alltid processer på specifika kärnor för att uppnå maximal prestanda och få mer konsekventa prestanda från körning till körning.
Process pinning:
Maximerar minnesbandbredden genom att placera eller fästa processer på platser som använder alla minneskanaler och distribuera alla minneskanaler lika mellan kärnorna.
Förbättrar prestanda för flyttalser genom att garantera att varje process är i sin egen kärna. Detta eliminerar möjligheten att två processer hamnar på samma kärna.
Optimerar dataförflyttning mellan processerna genom att placera processer som kommunicerar i NUMA-domännoder (Non-Uniform Memory Access). Detta garanterar att de har den lägsta svarstiden och den högsta bandbredden.
Minskar operativsystemets omkostnader och ger dig mer konsekventa resultat eftersom operativsystemet inte kan flytta processer till olika kärnor eller NUMA-domäner.
Var fäster du processer och trådar?
För att avgöra var processer och trådar ska fästas måste du förstå processor- och minnestopologin, särskilt antalet och platsen för NUMA-domänerna.
Verktyget lstopo-no-graphics (från hwloc RPM) och Intel Memory Latency Checker (MLC) är användbara verktyg för att fastställa processorn och minnestopologin. Exempel: Hur många NUMA-domäner har den virtuella datorn? Vilka kärnor är medlemmar i varje NUMA-domän? Vad är svarstiden och bandbredden för processer i varje NUMA-domän när de kommunicerar med varandra?
Följande bild visar kartan HB120_v2 NUMA-domänfördröjning som genereras av Intel MLC. Desto kortare svarstid mellan NUMA-domäner, desto snabbare är kommunikationen mellan dem. Bilden visar tydligt att HB120_v2 har 30 NUMA-domäner och vilka NUMA-domäner som finns på vilken socket. Den visar också vilka NUMA-domäner som kan grupperas tillsammans för att uppnå den lägsta dataöverförings- och kommunikationsfördröjningen.

Intel-processorer har sex minneskanaler och AMD EPYC-processorer har åtta minneskanaler. Se till att du använder alla minneskanaler för att maximera den tillgängliga minnesbandbredden. Gör detta genom att fördela de parallella processerna jämnt mellan NUMA-noddomänerna. För parallella hybridprogram ska du behålla process-/trådgruppering i samma NUMA-domäner, helst genom att dela samma L3-cache. Kontrollera att det totala antalet trådar inte överskrider det totala antalet kärnor.
Följande bild visar en HC44 SKU med 2 NUMA-domäner och 44 kärnor.
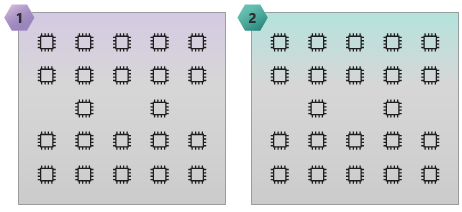
Följande bild visar en HB60 SKU med 15 NUMA-domäner och 60 kärnor.
Program som är bundna till minnesbandbredd
Om du har ett program som är bundet av minnesbandbredd kan du få bättre prestanda på den virtuella datorn genom att minska antalet parallella processer och trådar i varje NUMA-noddomän. Detta kan ge mer minnesbandbredd per process och eventuellt minska klocktiden på väggen.
Om du till exempel använder HB120_v2 SKU med 30 NUMA-noddomäner kan du prova att köra processer och trådar för 1, 2 och 3 per NUMA-noddomän (till exempel 30, 60 och 90 processer och trådar per virtuell dator). Du kan sedan se vilken konfiguration som ger bästa prestanda.