Introduktion till Azure Database for PostgreSQL
Azure Database for PostgreSQL är tillgängligt i multiserverversioner.
Som databasutvecklare med många års erfarenhet av att köra och hantera lokala PostgreSQL-installationer vill du utforska hur Azure Database for PostgreSQL stöder och skalar dess funktioner.
I den här lektionen ska du utforska alternativen prissättning, versionsstöd, replikering och skalning i Azure Database for PostgreSQL.
Azure-databas för PostgreSQL
Tjänsten Azure Database for PostgreSQL är en implementering av communityversionen av PostgreSQL. Tjänsten tillhandahåller vanliga funktioner som används av vanliga PostgreSQL-system, inklusive geo-spatialt stöd och fulltextsökning.
Microsoft har anpassat PostgreSQL för Azure-plattformen och är nära integrerat med många Azure-tjänster. Tjänsten Azure Database for PostgreSQL hanteras helt av Microsoft. Microsoft hanterar uppdateringar och korrigeringar av programvaran och tillhandahåller ett serviceavtal med 99,99% tillgänglighet. Det innebär att du bara kan fokusera på de databaser och program som körs med hjälp av tjänsten.
Du kan distribuera flera databaser i varje instans av den här tjänsten.
Prisnivåer
När du skapar en instans av Tjänsten Azure Database for PostgreSQL anger du de beräknings- och lagringsresurser som du vill allokera genom att välja en prisnivå. En prisnivå kombinerar antalet virtuella processorkärnor, mängden tillgängligt lagringsutrymme och olika alternativ för säkerhetskopiering. Ju fler resurser du allokerar, desto högre kostnad.
Azure Database for PostgreSQL-tjänsten använder lagring för att lagra dina databasfiler, temporära filer, transaktionsloggar och serverloggarna. Du kan också ange att du vill att lagringsutrymmet ska ökas när du kommer nära den aktuella kapaciteten. Om du inte väljer det här alternativet fortsätter servrar som har slut på lagring att köras, men fungerar som skrivskyddade.
Azure-portalen grupperar prisnivåer i tre breda intervall:
- Basic, som är lämplig för små system och utvecklingsmiljöer, men har variabel I/O-prestanda.
- Generell användning, som ger förutsägbara prestanda, upp till 6 000 IOPS, beroende på antalet processorkärnor och det tillgängliga lagringsutrymmet.
- Minnesoptimerad, som använder upp till 32 minnesoptimerade virtuella processorskärnor, och som även ger förutsägbara prestanda på upp till 6 000 IOPS.
Microsoft har också ett alternativet Stor lagring i förhandsversion, som kan etablera upp till 16 TB lagring och stöd för upp till 20 000 IOPS.
Du kan finjustera antalet processorkärnor och lagring som du behöver. Du kan skala upp och ned bearbetningsresurserna – du kan inte skala ned lagringen, bara upp – och växla mellan prisnivåerna Generell användning och Minnesoptimerad efter behov när du har skapat dina databaser. Du betalar bara för det du behöver.

Anmärkning
Om du ändrar antalet processorkärnor skapar Azure en ny server med den här beräkningsallokeringen. När servern körs växlas klientanslutningarna till den nya servern. Den här växeln kan ta upp till en minut. Under det här intervallet kan inga nya anslutningar göras och eventuella transaktioner under flygning återställs.
Om du bara ändrar lagringsstorleken för säkerhetskopieringsalternativen sker inget avbrott i tjänsten.
Prisnivån och de allokerade bearbetningsresurserna avgör det maximala antalet samtidiga anslutningar som tjänsten stöder. Om du till exempel väljer prisnivån Generell användning och allokerar 64 virtuella kärnor stöder tjänsten 1900 samtidiga anslutningar. Basic-nivån, med två virtuella kärnor, hanterar upp till 100 samtidiga anslutningar. Själva Azure kräver fem av dessa anslutningar för att övervaka servern. Om du överskrider antalet tillgängliga anslutningar får klienterna felet FATAL: sorry, too many clients already.
Priserna kan ändras. Gå till sidan Azure Database for PostgreSQL-prissättning för den senaste informationen.
Serverparametrar
I en lokal installation av PostgreSQL anger du serverkonfigurationsparametrar i filen postgresql.conf. Använd Azure Database for PostgreSQL för att ändra konfigurationsparametrar via serverparametrar sidan. Alla parametrar för en lokal installation av PostgreSQL är inte relevanta för Azure Database for PostgreSQL, så sidan Serverparametrar visar bara de parametrar som är lämpliga för Azure.

Ändringar av parametrar som har markerats som dynamisk börja gälla omedelbart. Statiska parametrar kräver en omstart av servern. Du startar om servern med knappen Starta om på sidan Översikt i portalen:

Hög tillgänglighet
Azure Database for PostgreSQL är en tjänst med hög tillgänglighet. Den innehåller inbyggda mekanismer för felidentifiering och redundans. Om en bearbetningsnod stannar på grund av ett maskinvaru- eller programvaruproblem växlas en ny nod in för att ersätta den. Alla anslutningar som för närvarande använder noden kommer att tas bort men öppnas automatiskt mot den nya noden. Alla transaktioner som utförs av noden som misslyckas återställs. Därför bör du alltid se till att klienterna är konfigurerade för att identifiera och försöka utföra misslyckade åtgärder igen.
PostgreSQL-versioner som stöds
Tjänsten Azure Database for PostgreSQL stöder för närvarande PostgreSQL version 11, tillbaka till version 9.5. Du anger vilken version av PostgreSQL som ska användas när du skapar en instans av tjänsten. Microsoft strävar efter att uppdatera tjänsten när nya versioner av PostgreSQL blir tillgängliga och kommer att upprätthålla kompatibilitet med de två tidigare huvudversionerna.
Azure hanterar automatiskt uppgraderingar till dina databaser mellan mindre versioner av PostgreSQL – men inte större versioner. Om du till exempel har en databas som använder PostgreSQL version 10 kan Azure automatiskt uppgradera databasen till version 10.1. Om du vill växla till version 11 måste du exportera dina data från databaserna i den aktuella tjänstinstansen, skapa en ny instans av Tjänsten Azure Database for PostgreSQL och importera dina data till den nya instansen.
Koordinator- och arbetsnoder
Data partitioneras och distribueras mellan arbetsnoder. Frågemotorn i koordinatorn kan parallellisera komplexa frågor och dirigera bearbetningen mot lämpliga arbetsnoder. Arbetsnoder väljs enligt vilka shards som innehåller de data som bearbetas. Koordinatorn ackumulerar sedan resultatet från arbetsnoderna innan de skickas tillbaka till klienten. Enklare frågor kan utföras med bara en enda arbetsnod. Klienter ansluter också till koordinatorn och kommunicerar aldrig direkt med en arbetsnod.
Du kan skala upp och ned antalet arbetsnoder i tjänsten efter behov.
Distribuera data
Du distribuerar data mellan arbetsnoder genom att skapa distribuerade tabeller. En distribuerad tabell delas upp i shards och varje shard allokeras till lagring på en arbetsnod. Du anger hur du delar upp data genom att definiera en kolumn som distribution kolumn. Data fragmenteras baserat på värdena för data i den här kolumnen. När du utformar en distribuerad tabell är det viktigt att du väljer distributionskolumnen noggrant. Du bör använda en kolumn med ett stort antal distinkta värden som vanligtvis används för att gruppera relaterade rader. I en tabell för ett e-handelssystem som lagrar information om kundernas beställningar kan kund-ID vara en rimlig distributionskolumn. Alla beställningar för en viss kund kommer att hållas i samma fragment, men beställningar för alla kunder kommer att spridas över shards.
Du kan också skapa referens tabeller. Dessa tabeller innehåller uppslagsdata, till exempel namnen på städer eller statuskoder. En referenstabell replikeras i sin helhet till varje arbetsnod. Data i en referenstabell bör vara relativt statiska. varje ändring kräver uppdatering av varje kopia av tabellen.
Slutligen kan du skapa lokala tabeller. En lokal tabell är inte fragmenterad, men lagras på koordinatornoden. Använd lokala tabeller för att lagra små tabeller med data som sannolikt inte kommer att krävas av kopplingar. Exempel är namnen på användare och deras inloggningsinformation.
Replikera data i Azure Database for PostgreSQL
Skrivskyddade repliker är användbara för hantering av läsintensiva arbetsbelastningar. Klientanslutningar kan spridas över repliker, vilket underlättar belastningen på en enda instans av tjänsten. Om dina klienter finns i olika regioner i världen använder du replikering mellan regioner för att placera data nära varje uppsättning klienter och minska svarstiden.
Du kan också använda repliker som en del av en beredskapsplan för haveriberedskap. Om huvudservern blir otillgänglig kanske du fortfarande kan ansluta till en replik.
Anmärkning
Om huvudservern tappas bort eller tas bort blir alla skrivskyddade repliker skrivskyddade servrar i stället. Dessa servrar kommer dock att vara oberoende av varandra, så alla ändringar som görs i data på en server kopieras inte till de återstående servrarna.
Upprätta en replik
En skrivskyddad replik innehåller en kopia av databaserna som finns på den ursprungliga servern, som kallas master. Du använder Azure-portalen eller CLI för att skapa en replik av en huvudreplik.

När du skapar en skrivskyddad replik skapar Azure en ny instans av Tjänsten Azure Database for PostgreSQL och kopierar sedan databaserna från huvudservern till den nya servern. Repliken körs i skrivskyddat läge. Alla försök att ändra data misslyckas.
Replikfördröjning
Replikeringen är inte synkron, och det kan ta en stund innan ändringar som görs i data på huvudservern visas i replikerna. Klientprogram som ansluter till repliker måste kunna hantera den här nivån av slutlig konsekvens. Med Azure Monitor kan du spåra tidsfördröjningen i replikeringen med hjälp av måtten maximal fördröjning mellan repliker och replikfördröjning.
Hantering och övervakning
Du kan använda välbekanta verktyg som pgAdmin för att ansluta till Azure Database for PostgreSQL för att hantera och övervaka dina databaser. Vissa serverfokuserade funktioner, till exempel säkerhetskopiering och återställning av servrar, är dock inte tillgängliga eftersom servern hanteras och underhålls av Microsoft.

Azure-verktyg för övervakning av Azure Database for PostgreSQL
Azure tillhandahåller en omfattande uppsättning tjänster som du använder för att övervaka server- och databasprestanda och felsöka problem. Med de här tjänsterna kan du visa hur PostgreSQL använder de Azure-resurser som du har allokerat. Du använder den här informationen för att bedöma om du behöver skala systemet, ändra strukturen för tabeller och index i dina databaser och visualisera körningsstatistik och andra händelser. De tjänster som är tillgängliga är:
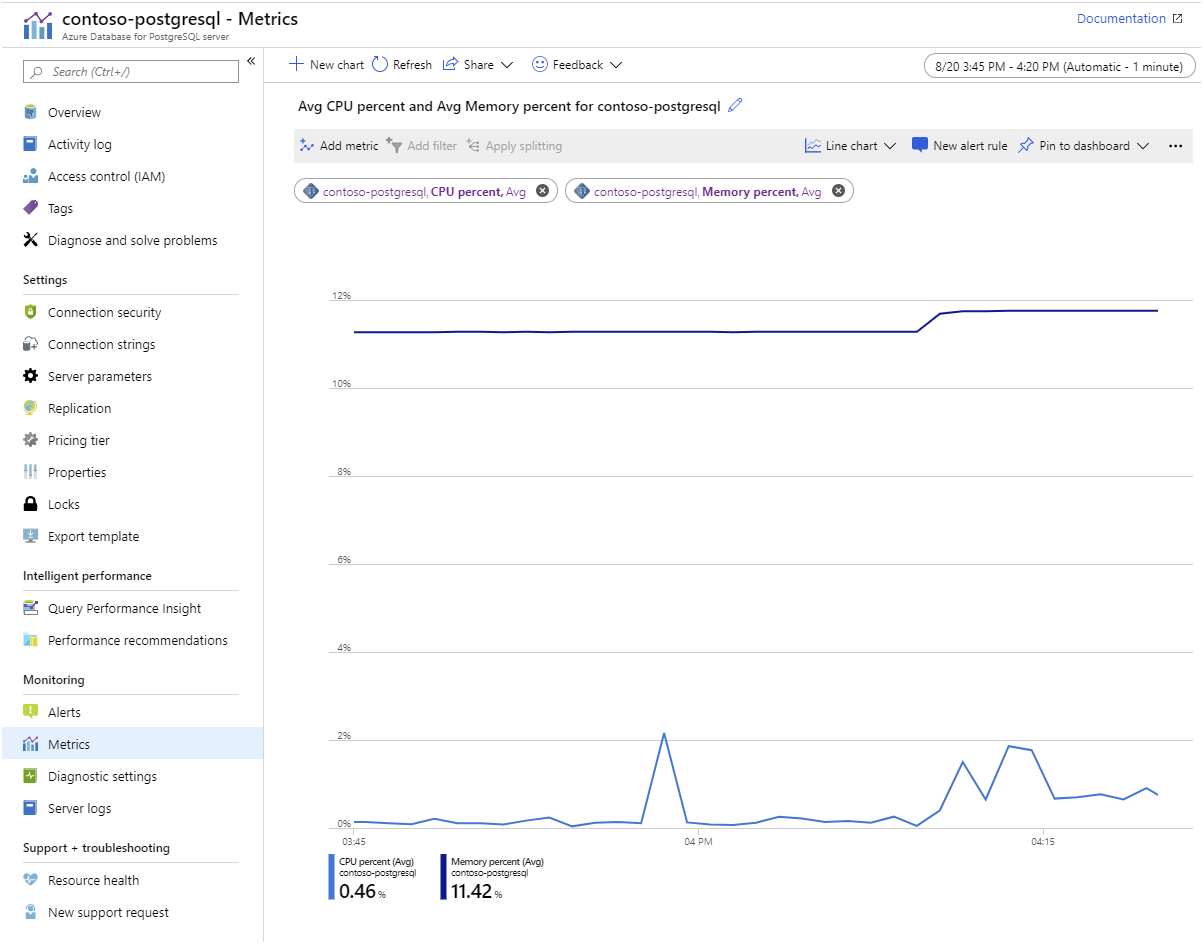
Azure Monitor. Azure Database for PostgreSQL innehåller mått som gör att du kan spåra objekt som processor- och lagringsanvändning, I/O-priser, minnesanvändning, antalet aktiva anslutningar och replikeringsfördröjning:
serverloggar. Azure gör loggarna tillgängliga för varje PostgreSQL-server. Du laddar ned dem från Azure-portalen:

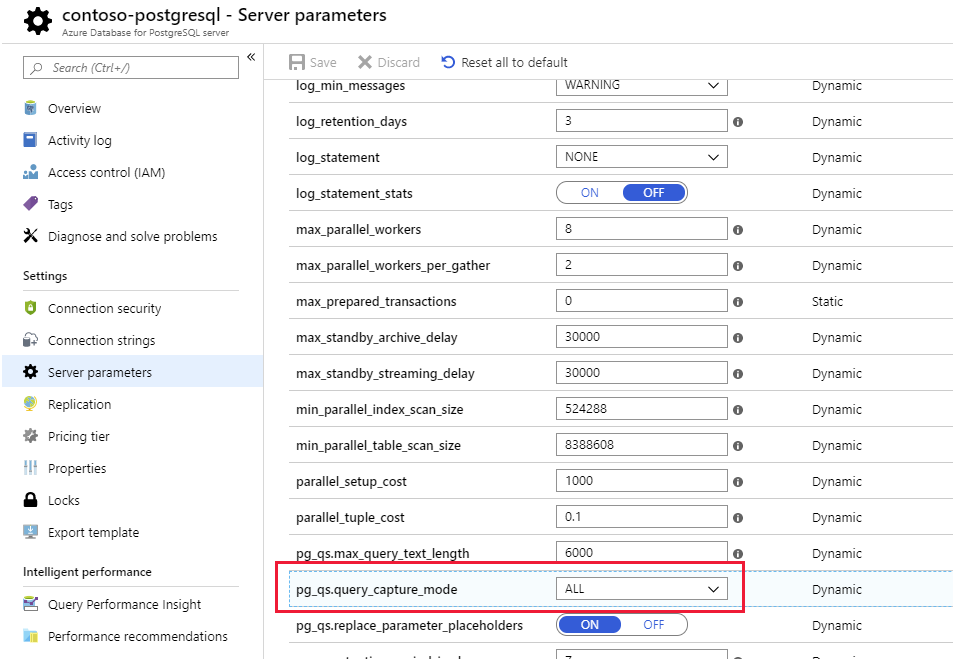
Query Store och Query Performance Insights. Azure Database for PostgreSQL lagrar information om de frågor som körs mot databaser på servern och sparar dem i en databas med namnet azure_sysi schemat query_store. Du frågar query_store.qs_view för att se den här informationen. Som standard samlar Inte Azure Database for PostgreSQL in någon frågeinformation eftersom den medför en liten omkostnad, men du kan aktivera spårning genom att ange egenskapen pg_qs.query_capture_mode server till ALL eller TOP.
Du konfigurerar också Query Store för att samla in information om frågor som ägnar tid åt att vänta. En fråga kan behöva vänta medan en annan fråga frigör ett lås på en tabell, eller på grund av att frågan utför mycket I/O, eller på grund av att minnet är kort. Den här informationen visas i vyn query_store.runtime_stats_view.
Om du föredrar att visualisera den här statistiken i stället för att köra SQL-instruktioner använder du Query Performance Insight i Azure-portalen:
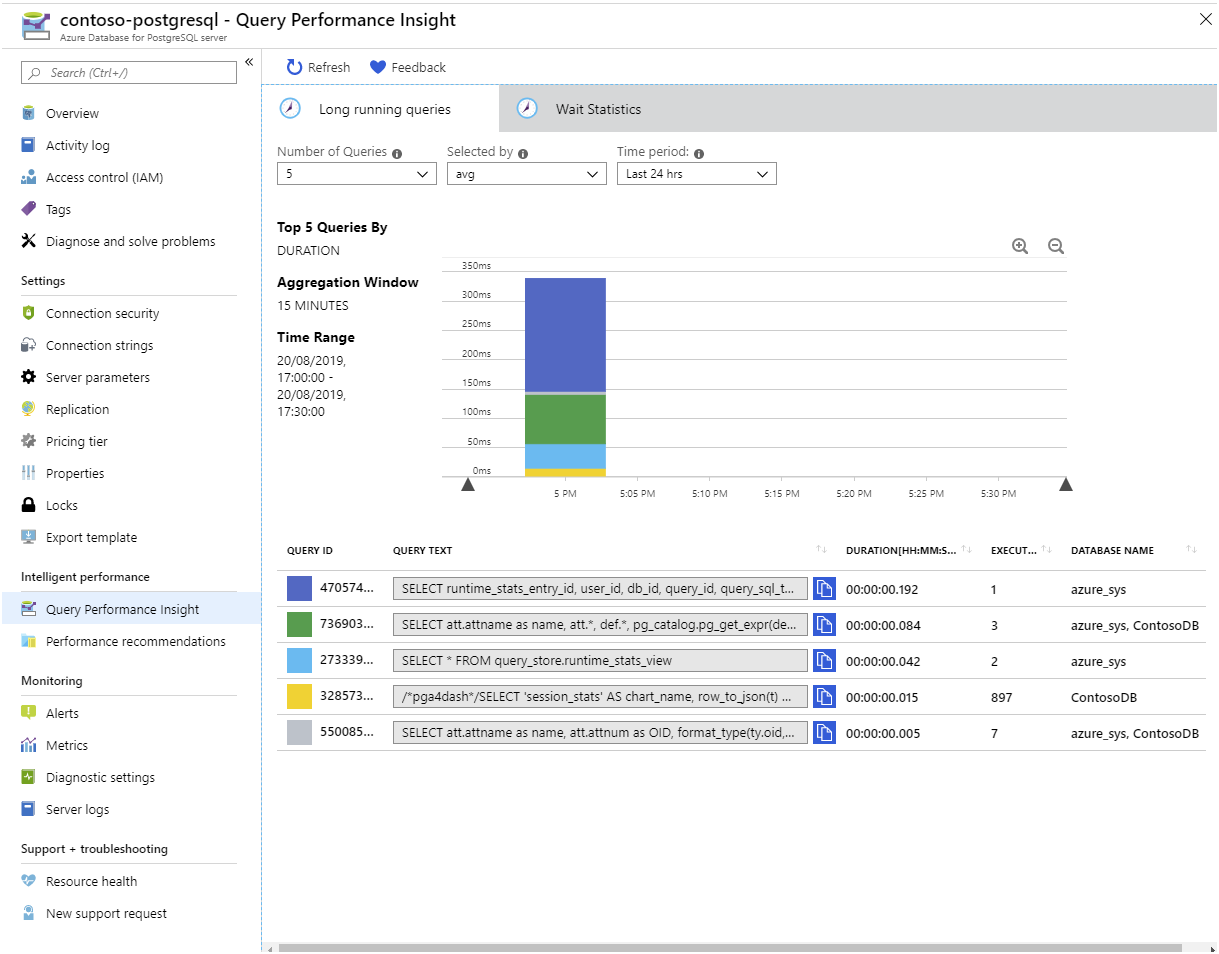
prestandarekommendationer. Verktyget Prestandarekommendationer, som också är tillgängligt i Azure-portalen, undersöker de frågor som dina program kör. Den tittar också på strukturerna i databasen och rekommenderar hur du organiserar dina data och om du bör överväga att lägga till eller ta bort index.




Klientanslutning
Azure Database for PostgreSQL körs bakom en brandvägg. För att få åtkomst till tjänsten och databasen måste du lägga till en brandväggsregel för de IP-adressintervall som klienterna ansluter från. Om du behöver komma åt tjänsten inifrån Azure, till exempel ett program som körs med Azure App Services, måste du också aktivera åtkomst till Azure-tjänster.
Konfigurera brandväggen
Det enklaste sättet att konfigurera brandväggen är att använda inställningarna för anslutningssäkerhet för din tjänst i Azure-portalen. Lägg till en regel för varje klient-IP-adressintervall. Du använder också den här sidan för att framtvinga SSL-anslutningar till din tjänst.

Du klickar på Lägg till klient-IP- i verktygsfältet för att lägga till IP-adressen för din stationära dator.
Om du har konfigurerat skrivskyddade repliker måste du lägga till en brandväggsregel till var och en för att göra dem tillgängliga för klienter.
Klientanslutningsbibliotek
Om du skriver egna klientprogram måste du använda lämplig databasdrivrutin för att ansluta till en PostgreSQL-databas. Många av dessa bibliotek är beroende av programmeringsspråk. De underhålls av oberoende tredje parter. Azure Database for PostgreSQL stöder klientbibliotek för Python, PHP, Node.js, Java, Ruby, Go, C# (.NET), ODBC, C och C++.
Logik för omförsök av klient
Som tidigare nämnts kan vissa händelser, till exempel redundans under återställning med hög tillgänglighet och skalning av CPU-resurser, orsaka en kort förlust i anslutningen. Alla pågående transaktioner kommer att återställas. Azure Database for PostgreSQL omdirigerar automatiskt en ansluten klient till en fungerande nod, men alla åtgärder som utförs av klienten vid den tidpunkten returnerar ett fel. Du bör behandla den här förekomsten som ett tillfälligt undantag. Programkoden bör vara beredd att fånga dessa undantag och försöka igen.
PostgreSQL-funktioner som stöds i Azure Database for PostgreSQL
Azure Database for PostgreSQL stöder de flesta funktioner som ofta används av PostgreSQL-databaser, men det finns vissa undantag. Om du behöver en funktion som inte stöds måste du antingen omarbeta databas- och programkoden för att ta bort det här beroendet eller överväga att köra PostgreSQL på en virtuell dator. I det senare fallet måste du ta ansvar för att hantera och underhålla servern.
Tillägg som stöds i Azure Database for PostgreSQL
Många PostgreSQL-funktioner är inkapslade i tillägg. Tillägg är paket med SQL-objekt och kod som lagras på servern– de kan läsas in i en databas med hjälp av kommandot CREATE EXTENSION. Azure Database for PostgreSQL tillhandahåller för närvarande många vanliga tillägg för:
- Datatyper
- Funktionen
- Fulltextsökning
- Index (blomning, btree_gist och btree_gin)
- Språket plpgsql
- PostGIS
- Många administrativa funktioner
Du använder dblink-- och postgres_fdw-paket för att ansluta en PostgreSQL-server till en annan – detta gör att kod på en server kan komma åt data som lagras i en annan. I Azure Database for PostgreSQL kan du bara ansluta mellan servrar som skapats med Azure Database for PostgreSQL. Du kan inte skapa utgående anslutningar till PostgreSQL-servrar som finns någon annanstans, till exempel lokalt eller på en virtuell dator.
Anmärkning
Listan över tillägg som stöds granskas kontinuerligt och kan ändras. Du genererar en lista över de tillägg som stöds med följande fråga. Observera att du inte kan skapa egna anpassade tillägg och ladda upp dem till Azure Database for PostgreSQL:
SELECT * FROM pg_available_extensions;
Azure Database for PostgreSQL innehåller databasen TimescaleDB som ett valfritt tillägg. Den här databasen innehåller tidsorienterade analysfunktioner och andra funktioner som stöder tidsseriearbetsbelastningar. Om du vill använda den här databasen väljer du alternativet TIMESCALEDB i shared_preload_libraries-serverparametern och startar sedan om servern.
Språkstöd för lagrade procedurer och utlösare
Stöd för andra språk än plpgsql kräver vanligtvis att du kompilerar din lagrade procedur eller utlöser kod separat och laddar upp det kompilerade biblioteket till servern. Främst på grund av säkerhetsskäl kan du inte göra detta med Azure Database for PostgreSQL. Om du har kod skriven på andra språk måste du portera den till plpgsql.