Konfigurera lagring och databaser
En del av distributionsprocessen kräver ofta att du ansluter till databaser eller lagringstjänster. Den här anslutningen kan vara nödvändig för att tillämpa ett databasschema, lägga till vissa referensdata i en databastabell eller för att ladda upp vissa blobar. I den här lektionen får du lära dig mer om hur du kan utöka din pipeline till att fungera med data- och lagringstjänster.
Konfigurera dina databaser från en pipeline
Många databaser har scheman, som representerar strukturen för de data som finns i databasen. Det är ofta en bra idé att tillämpa ett schema på databasen från din distributionskedja. Den här metoden hjälper till att säkerställa att allt din lösning behöver distribueras tillsammans. Om det uppstår ett problem när schemat tillämpas säkerställer det också att pipelinen visar ett fel. Felet gör att du kan åtgärda problemet och distribuera om.
När du arbetar med Azure SQL måste du använda databasscheman genom att ansluta till databasservern och köra kommandon med hjälp av SQL-skript. Dessa kommandon är dataplanoperationer. Din pipeline måste autentisera till databasservern och sedan köra skripten. Azure Pipelines innehåller uppgiften SqlAzureDacpacDeployment som kan ansluta till en Azure SQL-databasserver och exekvera kommandon.
Vissa andra data- och lagringstjänster behöver inte konfigureras med hjälp av ett API för dataplan. När du till exempel arbetar med Azure Cosmos DB lagrar du dina data i en container. Du kan konfigurera dina containrar med hjälp av kontrollplanet direkt från din Bicep-fil. På samma sätt kan du distribuera och hantera de flesta aspekter av Azure Storage-blobcontainrar i Bicep. I nästa övning visas ett exempel på hur du skapar en blobcontainer från Bicep.
Lägga till data
Många lösningar kräver att referensdata läggs till i deras databaser eller lagringskonton innan de fungerar. Ledningar kan vara en bra plats för att lägga till dessa data. När pipelinen har körts är din miljö helt konfigurerad och redo att användas.
Det är också bra att ha exempeldata i dina databaser, särskilt för icke-produktionsmiljöer. Exempeldata hjälper testare och andra personer som använder dessa miljöer att kunna testa din lösning omedelbart. Dessa data kan innehålla exempelprodukter eller saker som falska användarkonton. I allmänhet vill du inte lägga till dessa data i produktionsmiljön.
Vilken metod du använder för att lägga till data beror på vilken tjänst du använder. Till exempel:
- Om du vill lägga till data i en Azure SQL-databas måste du köra ett skript, ungefär som att konfigurera ett schema.
- Om du vill infoga data i en Azure Cosmos DB måste du komma åt dess API för dataplan, vilket kan kräva att du skriver anpassad skriptkod.
- Om du vill ladda upp blobar till en Azure Storage-blobcontainer kan du använda olika verktyg från pipelineskript, inklusive kommandoradsprogrammet AzCopy, Azure PowerShell eller Azure CLI. Vart och ett av dessa verktyg förstår hur du autentiserar till Azure Storage åt dig och hur du ansluter till dataplans-API:et för att ladda upp blobar.
Idempotens
En av egenskaperna hos distributionspipelines och infrastruktur som kod är att du bör kunna distribuera om upprepade gånger utan några negativa biverkningar. När du till exempel distribuerar om en tidigare distribuerad Bicep-fil jämför Azure Resource Manager filen du skickade med det befintliga tillståndet för dina Azure-resurser. Om det inte finns några ändringar gör Resource Manager ingenting. Möjligheten att köra en åtgärd igen upprepade gånger kallas idempotens. Det är en bra praxis att se till att dina skript och andra pipelinesteg är idempotenta.
Idempotens är särskilt viktig när du interagerar med datatjänster, eftersom de bibehåller tillstånd. Anta att du infogar en exempelanvändare i en databastabell från pipelinen. Om du inte är försiktig skapas en ny exempelanvändare varje gång du kör pipelinen. Det här resultatet är förmodligen inte det du vill ha.
När du tillämpar scheman på en Azure SQL-databas kan du använda ett datapaket, även kallat en DACPAC-fil, för att distribuera schemat. Din pipeline skapar en DACPAC-fil från källkoden och skapar en pipelineartefakt, precis som med ett program. Distributionssteget i pipelinen publicerar sedan DACPAC-filen till databasen:
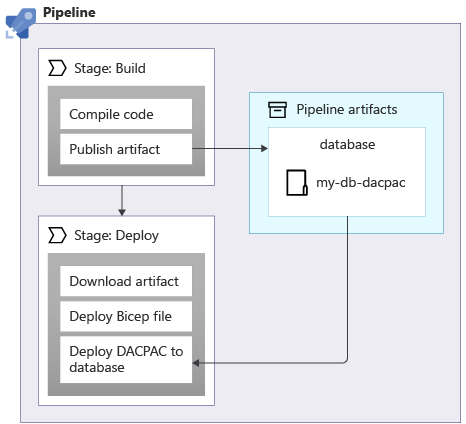
När en DACPAC-fil distribueras fungerar den på ett idempotent sätt. Den jämför måltillståndet för databasen med det tillstånd som definierats i paketet. I många situationer innebär det att du inte behöver skriva skript som följer principen om idempotens eftersom verktygen hanterar det åt dig. En del av verktygen för Azure Cosmos DB och Azure Storage fungerar också korrekt.
Men när du skapar exempeldata i en Azure SQL-databas eller en annan lagringstjänst som inte fungerar automatiskt på ett idempotent sätt. Det är en bra idé att skriva skriptet så att det bara skapar data om de inte redan finns.
Det är också viktigt att överväga om du kan behöva återställa distributioner, till exempel genom att köra en äldre version av en distributionspipeline igen. Återställning av ändringar i dina data kan bli komplicerad, så tänk noga på hur din lösning fungerar om du behöver återställa.
Nätverkssäkerhet
Ibland kan du använda nätverksbegränsningar för vissa av dina Azure-resurser. Dessa begränsningar kan framtvinga regler om begäranden som görs till dataplanet för en resurs, till exempel:
- Den här databasservern är endast tillgänglig från en angiven lista med IP-adresser.
- Det här lagringskontot är endast tillgängligt från resurser som distribueras i ett specifikt virtuellt nätverk.
Nätverksbegränsningar är vanliga med databaser, eftersom det kan verka som om det inte finns något behov av att något på Internet ansluter till en databasserver.
Nätverksbegränsningar kan dock också göra det svårt för dina implementeringspipelines att arbeta med dina resursdataplaner. När du använder en Microsoft-värdbaserad pipelineagent kan IP-adressen inte lätt fastställas i förväg, och den kan tilldelas från en stor IP-adresspool. Dessutom kan pipelineagenter som är värdbaserade av Microsoft inte anslutas till dina egna virtuella nätverk.
Några av uppgifterna i Azure Pipelines som hjälper dig att utföra åtgärder på dataplanet kan lösa dessa problem. Till exempel SqlAzureDacpacDeployment uppgift:
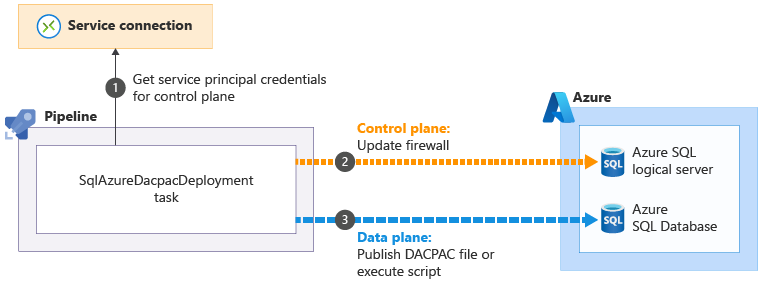
När du använder aktiviteten SqlAzureDacpacDeployment för att arbeta med en logisk Azure SQL-server eller databas, använder den din pipelines huvudprincip för att ansluta till kontrollplanet för den logiska Azure SQL-servern. Den uppdaterar brandväggen så att pipelineagenten kan komma åt servern från dess IP-adress
för att ansluta till kontrollplanet för den logiska Azure SQL-servern. Den uppdaterar brandväggen så att pipelineagenten kan komma åt servern från dess IP-adress . Sedan kan den framgångsrikt skicka DACPAC-filen eller skriptet för att köras
. Sedan kan den framgångsrikt skicka DACPAC-filen eller skriptet för att köras . Uppgiften tar sedan automatiskt bort brandväggsregeln när den är klar.
. Uppgiften tar sedan automatiskt bort brandväggsregeln när den är klar.
I andra situationer går det inte att skapa dessa typer av undantag. Under dessa omständigheter bör du överväga att använda en lokalt installerad pipelineagent, som körs på en virtuell dator eller någon annan beräkningsresurs som du styr. Du kan sedan konfigurera den här agenten hur du än behöver. Den kan använda en känd IP-adress eller anslutas till ditt eget virtuella nätverk. Vi diskuterar inte lokalt installerade agenter i den här modulen, men vi tillhandahåller länkar till mer information på sidan Sammanfattning i slutet av modulen.
Din distributionspipeline
I nästa övning uppdaterar du distributionspipelinen för att lägga till nya jobb för att skapa webbplatsens databaskomponenter, distribuera databasen och lägga till startdata:
