Optimera prestanda för en Azure AI Search-lösning
Dina söklösningars prestanda kan påverkas av storleken och komplexiteten i dina index. Du behöver också veta hur du skriver effektiva frågor för att söka efter den och välja rätt tjänstnivå.
Här utforskar du alla dessa dimensioner och ser steg du kan vidta för att förbättra prestandan för din söklösning.
Mäta din aktuella sökprestanda
Du kan inte optimera när du inte vet hur bra söktjänsten presterar. Skapa ett prestandamått för baslinjeprestanda så att du kan verifiera de förbättringar du gör, men du kan också kontrollera om prestanda försämras över tid.
Börja med att aktivera diagnostikloggning med Log Analytics:
- I Azure-portalen väljer du Diagnostikinställningar.
- Välj + Lägg till diagnostikinställningar.

- Ge diagnostikinställningen ett namn.
- Välj allLogs och AllMetrics.
- Välj Skicka till Log Analytics-arbetsyta.
- Välj eller skapa din Log Analytics-arbetsyta.
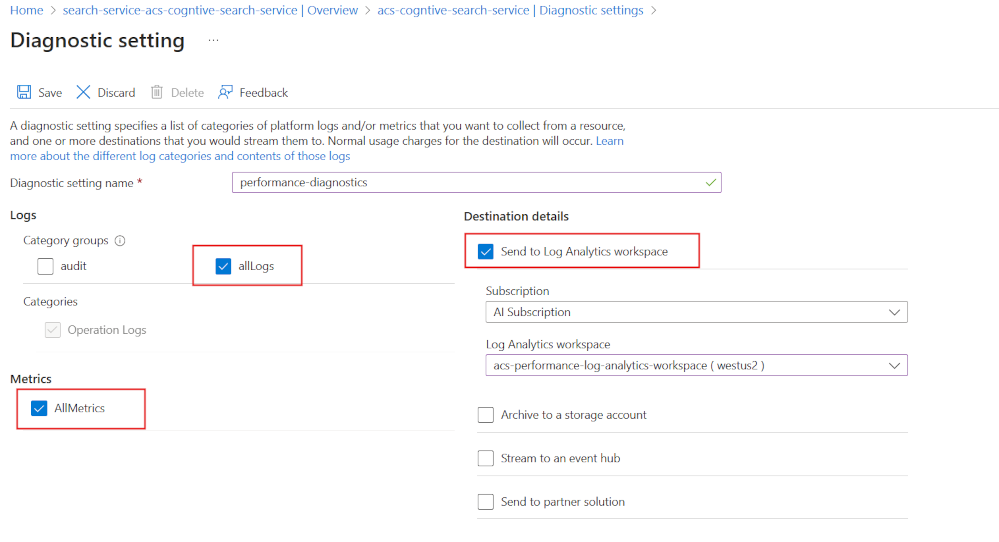
Det är viktigt att samla in den här diagnostikinformationen på söktjänstnivå. Eftersom det finns flera platser där slutanvändarna eller apparna kan se prestandaproblem.

Om du kan bevisa att söktjänsten fungerar bra kan du eliminera den från de möjliga faktorerna om du har prestandaproblem.
Kontrollera om söktjänsten är begränsad
Azure AI Search-sökningar och index kan begränsas. Om dina användare eller appar får sina sökningar begränsade registreras de i Log Analytics med ett 503 HTTP-svar. Om dina index begränsas visas de som 207 HTTP-svar.
Den här frågan som du kan köra mot dina söktjänstloggar visar dig om söktjänsten begränsas.

I Azure-portalen går du till Övervakning och väljer Loggar. På fliken Ny fråga 1 använder du den här frågan:
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
Du skulle köra kommandot för att se ett stapeldiagram över http-svar för söktjänster. I ovanstående kan du se att det har förekommit flera 503 svar.
Kontrollera prestanda för enskilda frågor
Det bästa sättet att testa enskilda frågeprestanda är med ett klientverktyg som Postman. Du kan använda valfritt verktyg som visar rubrikerna i svaret på en fråga. Azure AI Search returnerar alltid värdet "förfluten tid" för hur lång tid det tog för tjänsten att slutföra frågan.

Om du vill veta hur lång tid det skulle ta att skicka och sedan ta emot svaret från klienten kan du subtrahera den förflutna tiden från den totala tur och retur-resan. I ovanstående skulle det vara 125 ms - 21 ms ger dig 104 ms.
Optimera indexstorleken och schemat
Hur dina sökfrågor fungerar är direkt kopplat till storleken och komplexiteten i dina index. Ju mindre och mer optimerade indexen är, kan den snabba Azure AI Search svara på frågor. Här följer några tips som kan hjälpa dig om du har upptäckt att du har prestandaproblem med enskilda frågor.
Om du inte är uppmärksam kan index växa med tiden. Du bör granska att alla dokument i ditt index fortfarande är relevanta och måste vara sökbara.
Kan du minska schemats komplexitet om du inte kan ta bort några dokument? Behöver du fortfarande samma fält för att vara sökbara? Behöver du fortfarande alla kompetensuppsättningar som du startade indexet med?

Överväg att granska alla attribut som du har aktiverat i varje fält. Om du till exempel lägger till stöd för filter, fasetter och sortering kan du fyrdubbla den lagring som behövs för att stödja ditt index.
Kommentar
Om du har för många attribut i ett fält begränsas dess funktioner. I ett fält som är fasettbart, filtrerat och sökbart kan du till exempel bara lagra 16 kB. Ett sökbart fält kan innehålla upp till 16 MB text.
Om ditt index har optimerats men prestandan fortfarande inte är där det behöver vara kan du välja att skala upp eller skala ut söktjänsten.
Förbättra prestandan för dina frågor
Om du vet hur söktjänsten fungerar kan du justera dina frågor för att drastiskt förbättra prestandan. Använd den här checklistan för att skriva bättre frågor:
- Ange bara de fält som du behöver söka i med parametern searchFields . Eftersom fler fält kräver extra bearbetning.
- Returnera det minsta antalet fält som du behöver rendera på sökresultatsidan. Det tar längre tid att returnera mer data.
- Försök att undvika partiella söktermer som prefixsökning eller reguljära uttryck. Den här typen av sökningar är mer beräkningsmässigt dyra.
- Undvik att använda höga överhoppsvärden. Detta tvingar sökmotorn att hämta och rangordna större datavolymer.
- Begränsa användningen av fasettbara och filterbara fält till data med låg kardinalitet.
- Använd sökfunktioner i stället för enskilda värden i filtervillkor. Du kan till exempel använda
search.in(userid, '123,143,563,121',',')i stället för$filter=userid eq 123 or userid eq 143 or userid eq 563 or userid eq 121.
Om du har tillämpat alla ovanstående och fortfarande har enskilda frågor som inte utförs kan du skala ut ditt index. Beroende på vilken tjänstnivå du använde för att skapa söklösningen kan du lägga till upp till 12 partitioner. Partitioner är den fysiska lagring där ditt index finns. Som standard skapas alla nya sökindex med en enda partition. Om du lägger till fler partitioner lagras indexet över dem. Om ditt index till exempel är 200 GB och du har fyra partitioner innehåller varje partition 50 GB av ditt index.
Att lägga till extra partitioner kan hjälpa till med prestanda eftersom sökmotorn kan köras parallellt i varje partition. De bästa förbättringarna visas för frågor som returnerar ett stort antal dokument och frågor som använder fasetter som ger antal över ett stort antal dokument. Det här är en faktor för hur beräkningsmässigt dyrt det är att bedöma dokuments relevans.
Använd den bästa tjänstnivån för dina sökbehov
Du har sett att du kan skala ut tjänstnivåer genom att lägga till fler partitioner. Du kan skala ut med repliker om du behöver skala på grund av ökad belastning. Du kan också skala upp söktjänsten med hjälp av en högre nivå.

De två sökindexen ovan är 200 GB stora. S1-nivån använder åtta partitioner och S2-nivån har bara två. Båda har två repliker och båda skulle kosta ungefär samma sak. Om du väljer den bästa nivån för din söklösning måste du veta den ungefärliga totala lagringsstorleken som du kommer att behöva. Det största index som stöds för närvarande är 12 partitioner på L2-nivån som erbjuder totalt 24 TB.
| Nivå | Typ | Lagring | Repliker | Partitioner |
|---|---|---|---|---|
| F | Kostnadsfri | 50 MB | 1 | 1 |
| F | Grundläggande | 2 GB | 3 | 1 |
| S1 | Standard | 25 GB/partition | 12 | 12 |
| S2 | Standard | 100 GB/partition | 12 | 12 |
| S3 | Standard | 200 GB/partition | 12 | 12 |
| S3HD | High-density | 200 GB/partition | 12 | 3 |
| L1 | Lagringsoptimerad | 1 TB/partition | 12 | 12 |
| L2 | Lagringsoptimerad | 2 TB/partition | 12 | 12 |
Vilken av ovanstående två nivåer i exemplet ovan tycker du presterar bäst? Du har sett att utskalning ger prestandafördelar på grund av parallellitet. Men de högre nivåerna kommer också med premiumlagring, kraftfullare beräkningsresurser och extra minne. Om du väljer det andra alternativet får du mer kraftfull infrastruktur och ger framtida indextillväxt. Vilken nivå som presterar bäst beror tyvärr på storleken och komplexiteten i ditt index och de frågor du skriver för att söka i det. Så båda kan vara bäst.
Att planera för framtida tillväxt i användningen av söklösningen innebär att du bör överväga sökenheter. En sökenhet (SU) är produkten av repliker och partitioner. Det innebär att ovanstående S1-nivå använder 16 SU och att S2-nivån bara är 4 SU. Kostnaderna liknar högre nivåer som debiterar mer per SU.
Fundera på att behöva skala din söklösning på grund av den ökade belastningen. Om du lägger till en annan replik på båda nivåerna ökar S1-nivån till 24 SU , men S2-nivån ökar bara till 6 SU.