Obalanser i data
När våra dataetiketter har mer av en kategori än en annan säger vi att vi har en obalans i data. Kom till exempel ihåg att vi i vårt scenario försöker identifiera objekt som hittas av drönarsensorer. Våra data är obalanserade eftersom det finns mycket olika antal vandrare, djur, träd och stenar i våra träningsdata. Vi kan se detta antingen genom att tabulera dessa data:
| Etikett | Vandrare | Djur | Träd | Sten |
|---|---|---|---|---|
| Antal | 400 | 200 | 800 | 800 |
Eller ritar den:
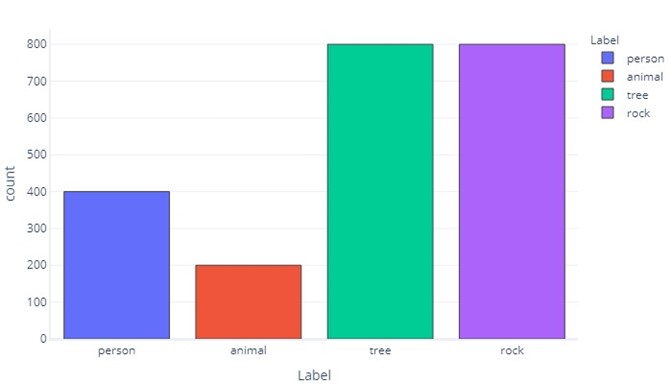
Observera hur de flesta data är träd eller stenar. En balanserad datauppsättning har inte det här problemet.
Om vi till exempel försöker förutsäga om ett objekt är en vandrare, ett djur, ett träd eller en sten, skulle vi helst vilja ha lika många av alla kategorier, så här:
| Etikett | Vandrare | Djur | Träd | Sten |
|---|---|---|---|---|
| Antal | 550 | 550 | 550 | 550 |
Om vi bara försökte förutsäga om ett objekt var en vandrare skulle vi helst vilja ha lika många vandrare och objekt som inte vandrar:
| Etikett | Vandrare | Icke-vandrare |
|---|---|---|
| Antal | 1100 | 1100 |
Varför spelar dataobalanser roll?
Dataobalanser spelar roll eftersom modeller kan lära sig att efterlikna dessa obalanser när det inte är önskvärt. Anta till exempel att vi har tränat en logistisk regressionsmodell för att identifiera objekt som vandrare eller icke-vandrare. Om träningsdata dominerades kraftigt av "vandraretiketter" skulle träning partiska modellen att nästan alltid returnera "vandraretiketter". Men i den verkliga världen kanske vi upptäcker att det mesta drönarna stöter på är träd. Den partiska modellen skulle förmodligen märka många av dessa träd som vandrare.
Det här fenomenet sker eftersom kostnadsfunktioner som standard avgör om rätt svar angavs. Det innebär att för en partisk datamängd kan det enklaste sättet för en modell att uppnå optimala prestanda vara att praktiskt taget ignorera de funktioner som tillhandahålls och alltid, eller nästan alltid, returnera samma svar. Detta kan få förödande konsekvenser. Anta till exempel att vår vandrare/inte-vandrare-modell tränas på data där endast ett per 1 000 prov innehåller en vandrare. En modell som har lärt sig att returnera "inte-vandrare" varje gång har en noggrannhet på 99,9%! Den här statistiken verkar vara enastående, men modellen är värdelös eftersom den aldrig kommer att berätta för oss om någon är på berget, och vi vet inte att rädda dem om en lavin träffar.
Bias i en förvirringsmatris
Förvirringsmatriser är nyckeln till att identifiera obalanser i data eller modellfördomar. I ett idealiskt scenario har testdata ett ungefär jämnt antal etiketter, och de förutsägelser som modellen har gjort är också ungefär spridda över etiketterna. För 1 000 exempel kan en modell som är opartisk, men ofta får fel svar, se ut ungefär så här:
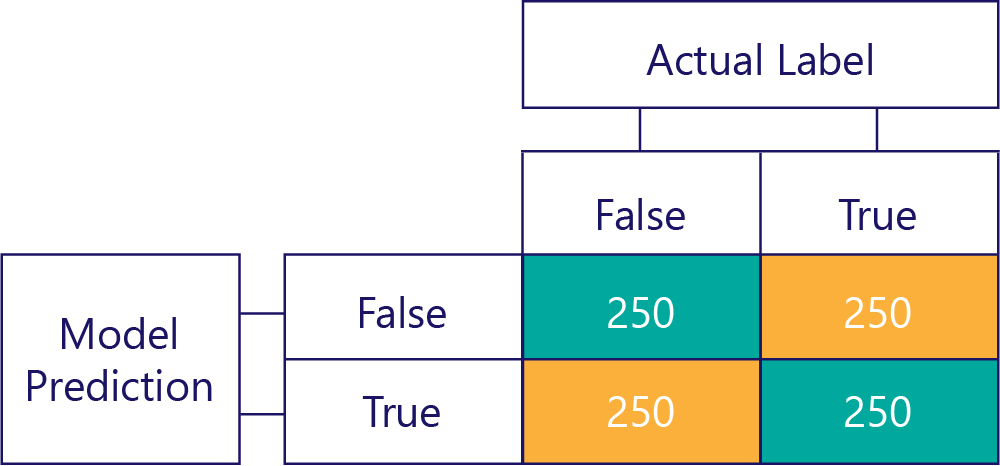
Vi kan se att indata är opartiska eftersom radsummorna är desamma (500 vardera), vilket indikerar att hälften av etiketterna är "true" och hälften är "false". På samma sätt kan vi se att modellen ger opartiska svar eftersom den returnerar sant halva tiden och falskt den andra hälften av tiden.
Däremot innehåller partiska data mestadels en typ av etikett, så här:
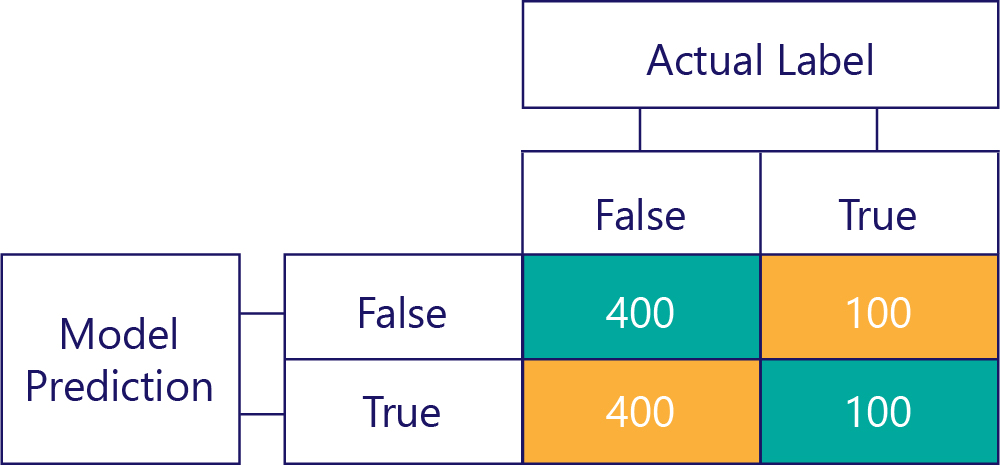
På samma sätt producerar en partisk modell mestadels en typ av etikett, så här:
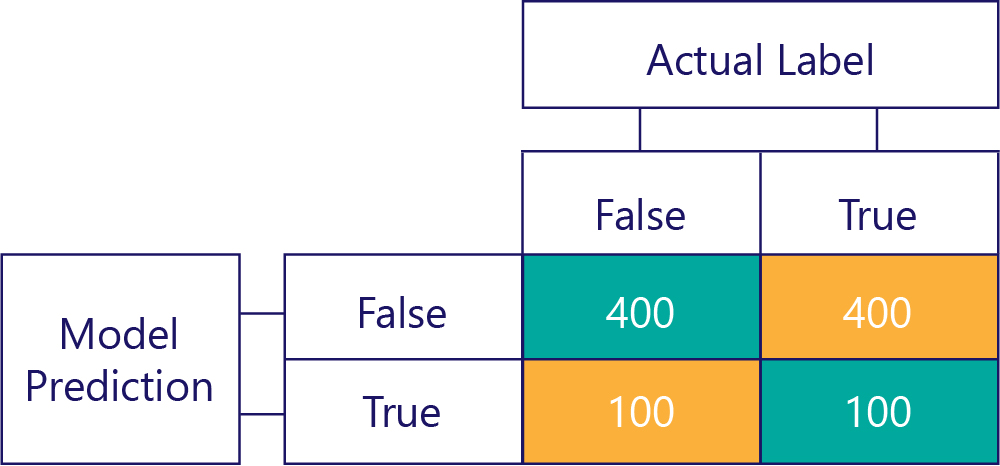
Modellförskjutning är inte noggrannhet
Kom ihåg att bias inte är korrekt. Till exempel är vissa av föregående exempel partiska, och andra är det inte, men de visar alla en modell som får svaret korrekt 50 % av tiden. Som ett mer extremt exempel visar matrisen nedan en opartisk modell som är felaktig:
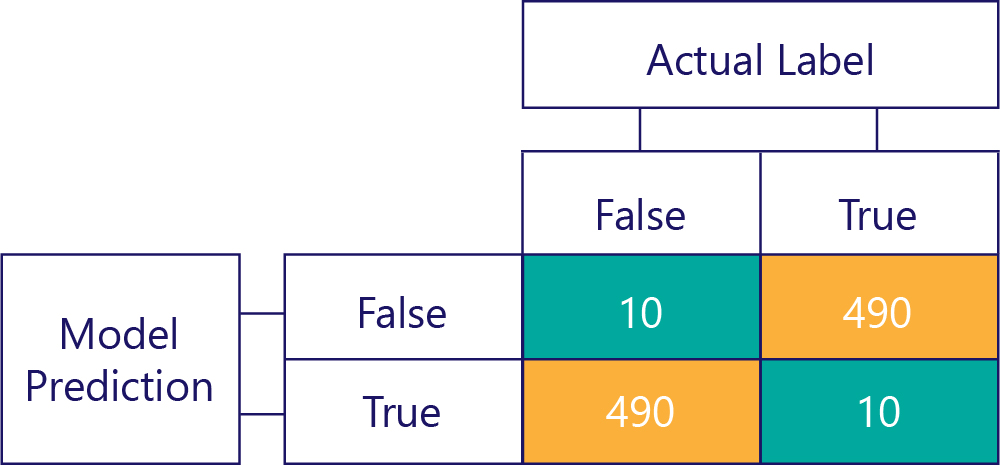
Observera hur antalet rader och kolumner läggs till i 500, vilket indikerar att båda data är balanserade och att modellen inte är partisk. Den här modellen får dock nästan alla svar felaktiga!
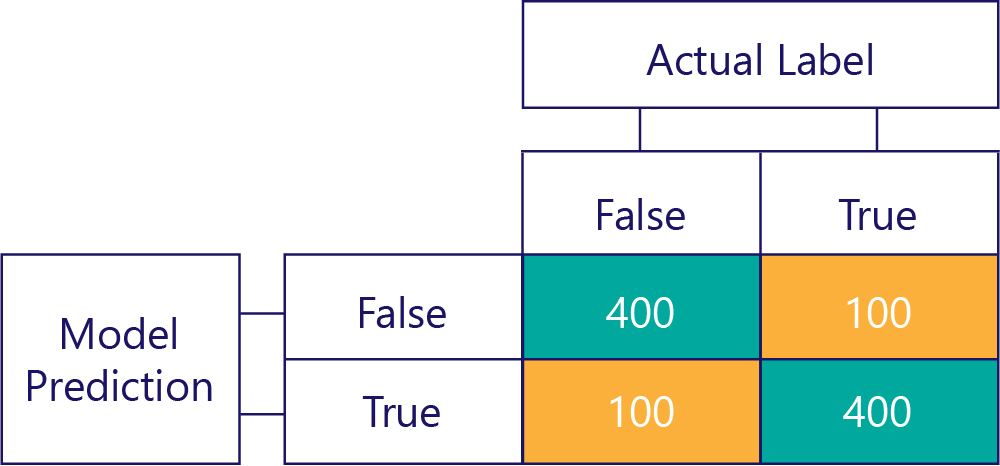
Vårt mål är naturligtvis att modeller ska vara korrekta och opartiska, till exempel:
… men vi måste se till att våra korrekta modeller inte är partiska, bara för att data är:
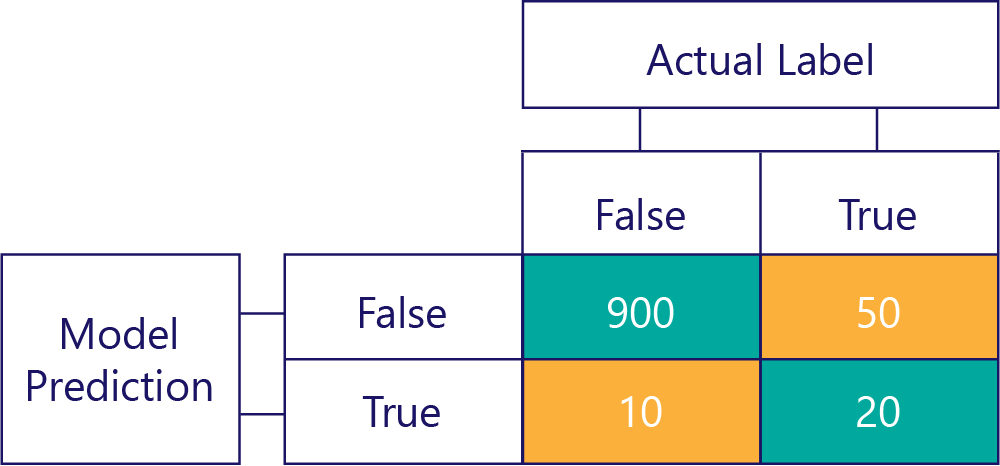
I det här exemplet ser du hur de faktiska etiketterna mestadels är falska (vänster kolumn, visar en obalans i data) och modellen returnerar också ofta falskt (översta raden, som visar modellförskjutning). Den här modellen är inte bra på att korrekt ge "True"-svar.
Undvika konsekvenserna av obalanserade data
Några av de enklaste sätten att undvika konsekvenserna av obalanserade data är:
- Undvik det genom bättre dataval.
- "Sampla om" dina data så att de innehåller dubbletter av klassen för minoritetsetiketter.
- Gör ändringar i kostnadsfunktionen så att den prioriterar mindre vanliga etiketter. Om till exempel fel svar ges till Träd kan kostnadsfunktionen returnera 1. medan om fel svar görs till Hiker, kan det returnera 10.
Vi utforskar dessa metoder i följande övning.