Förvirringsmatriser
Du kan betrakta data som kontinuerliga, kategoriska eller ordningstal (kategoriska men med en ordning). Förvirringsmatriser är ett sätt att bedöma hur väl en kategorisk modell presterar. När det gäller kontexten för hur dessa fungerar ska vi först uppdatera vår kunskap om kontinuerliga data. Genom detta kan vi se hur förvirringsmatriser helt enkelt är en förlängning av de histogram som vi redan känner till.
Kontinuerliga datadistributioner
När vi vill förstå kontinuerliga data är det första steget ofta att se hur de distribueras. Överväg följande histogram:

Vi kan se att etiketten i genomsnitt är ungefär noll och att de flesta datapunkter ligger mellan -1 och 1. Den visas som symmetrisk. det finns ett ungefärligt jämnt antal tal som är mindre och större än medelvärdet. Om vi vill kan vi använda en tabell i stället för ett histogram, men det kan vara otymplig.
Kategoriska datadistributioner
I vissa avseenden skiljer sig kategoridata inte så mycket från kontinuerliga data. Vi kan fortfarande skapa histogram för att utvärdera hur vanliga värden visas för varje etikett. Till exempel kan en binär etikett (true/false) visas med så här frekvens:

Detta anger att det finns 750 exempel med "false" som etikett och 250 med "true" som etikett.
En etikett för tre kategorier liknar följande:

Detta säger oss att det finns 200 prover som är "person", 400 som är "djur" och 100 som är "träd".
Eftersom kategoriska etiketter är enklare kan vi ofta visa dessa som enkla tabeller. De två föregående graferna skulle se ut så här:
| Etikett | Falsk | Sant |
|---|---|---|
| Antal | 750 | 250 |
Och:
| Etikett | Person | Djur | Träd |
|---|---|---|---|
| Antal | 200 | 400 | 100 |
Titta på förutsägelser
Vi kan titta på förutsägelser som modellen gör precis som vi tittar på mark-sanningsetiketterna i våra data. Vi kan till exempel se att vår modell i testuppsättningen förutsade "falskt" 700 gånger och "sant" 300 gånger.
| Modellförutsägelse | Antal |
|---|---|
| Falsk | 700 |
| Sant | 300 |
Detta ger direkt information om de förutsägelser som vår modell gör, men det anger inte vilka av dessa som är korrekta. Vi kan använda en kostnadsfunktion för att förstå hur ofta rätt svar ges, men kostnadsfunktionen talar inte om för oss vilka typer av fel som görs. Modellen kan till exempel gissa alla "sanna" värden korrekt, men även gissa "sant" när den borde ha gissat "false".
Förvirringsmatrisen
Nyckeln till att förstå modellens prestanda är att kombinera tabellen för modellförutsägelse med tabellen för dataetiketter med grundsanning:
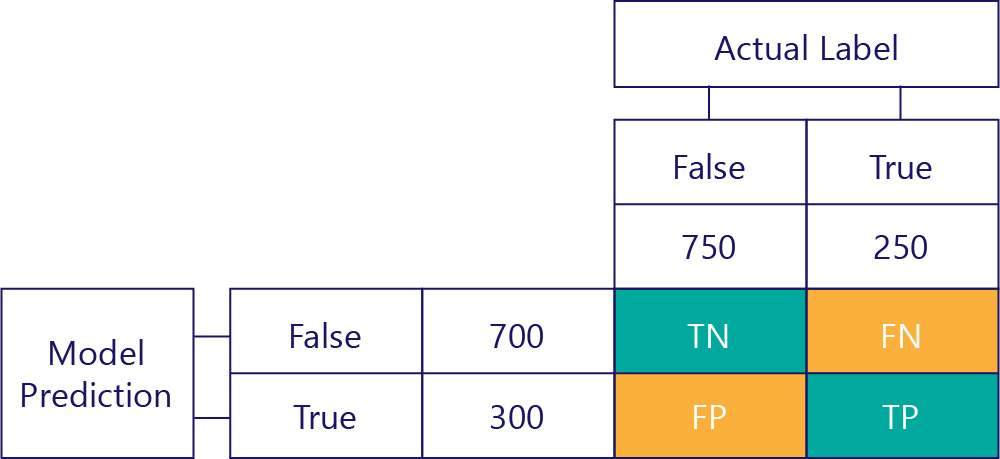
Torget vi inte har fyllt i kallas för förvirringsmatrisen.
Varje cell i förvirringsmatrisen berättar en sak om modellens prestanda. Dessa är True Negatives (TN), False Negatives (FN), False Positives (FP) och True Positives (TP).
Låt oss förklara dessa en i taget och ersätta dessa förkortningar med faktiska värden. Blågröna rutor innebär att modellen gjorde en korrekt förutsägelse, och orangea rutor innebär att modellen gjorde en felaktig förutsägelse.
True Negatives (TN)
Det övre vänstra värdet visar hur många gånger modellen förutsade falskt, och den faktiska etiketten var också falsk. Med andra ord visar detta hur många gånger modellen korrekt förutsade falskt. Låt oss anta att det här hände 500 gånger:
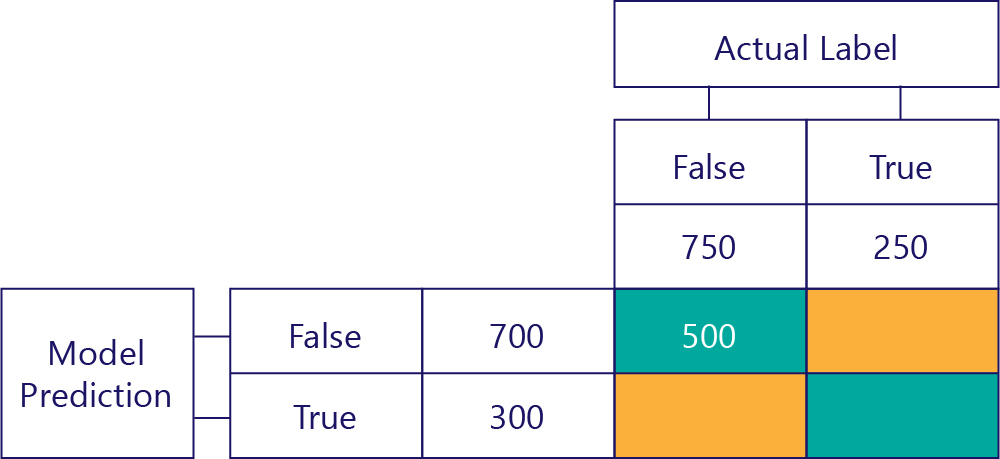
Falska negativa (FN)
Det övre högra värdet anger hur många gånger modellen förutsade falskt, men den faktiska etiketten var sann. Vi vet nu att detta är 200. Hur? Eftersom modellen förutsade false 700 gånger och 500 av dessa gånger gjorde den det korrekt. Därför måste det 200 gånger ha förutsagt falskt när det inte borde ha gjort det.

Falska positiva identifieringar (FP)
Värdet längst ned till vänster innehåller falska positiva identifieringar. Detta anger hur många gånger modellen förutsade sant, men den faktiska etiketten var falsk. Vi vet nu att detta är 250, eftersom det fanns 750 gånger att rätt svar var falskt. 500 av dessa gånger visas i den övre vänstra cellen (TN):
Sanna positiva identifieringar (TP)
Slutligen har vi verkliga positiva resultat. Det här är antalet gånger som modellen korrekt förutsäger sant. Vi vet att detta är 50 av två skäl. För det första förutsade modellen sant 300 gånger, men 250 gånger var det felaktigt (nedre vänstra cellen). För det andra fanns det 250 gånger som sant var rätt svar, men 200 gånger förutspådde modellen falskt.

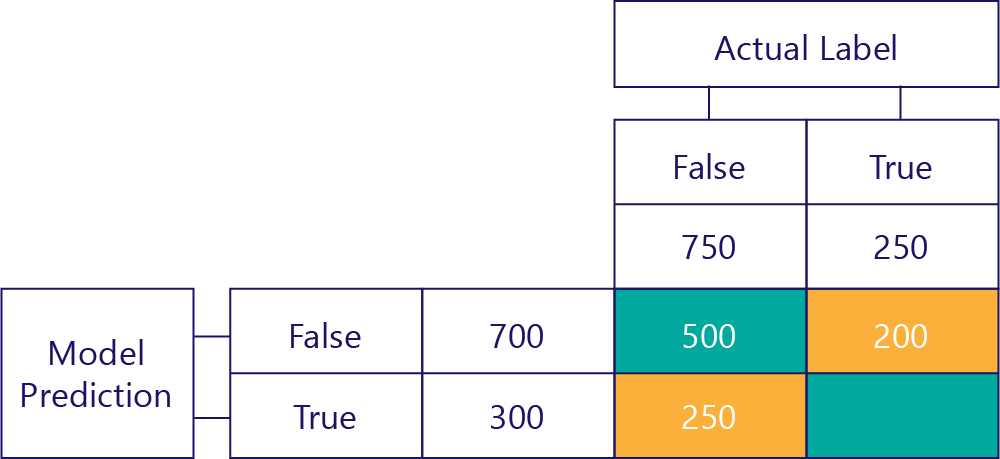
Den slutliga matrisen
Vi förenklar normalt vår förvirringsmatris något, så här:

Vi har färgat cellerna här för att markera när modellen gjorde rätt förutsägelser. Utifrån detta vet vi inte bara hur ofta modellen gjorde vissa typer av förutsägelser, utan också hur ofta dessa förutsägelser var korrekta eller felaktiga.
Förvirringsmatriser kan också konstrueras när det finns fler etiketter. För vårt exempel på person/djur/träd kan vi till exempel få en matris så här:
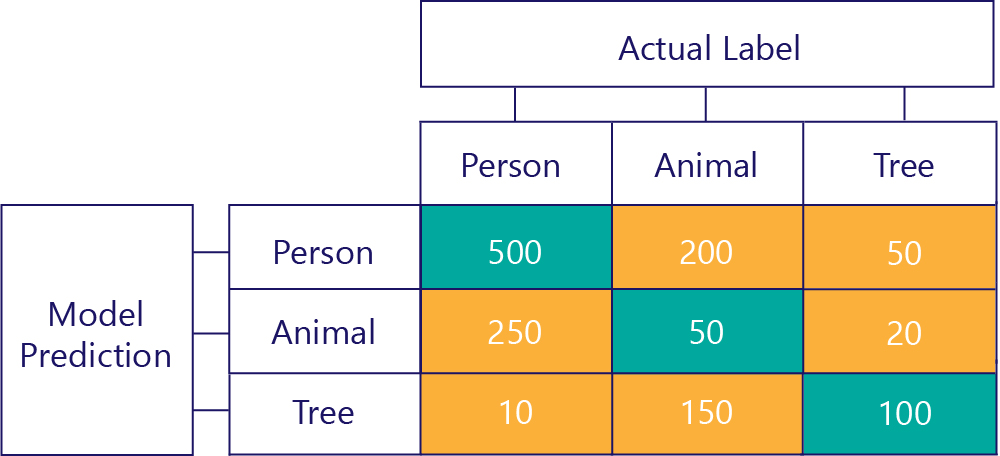
När det finns tre kategorier gäller inte längre mått som True Positives, men vi kan fortfarande se exakt hur ofta modellen gjorde vissa typer av misstag. Vi kan till exempel se att modellen förutsade att "person" 200 gånger när det faktiska korrekta resultatet var "djur".