Skapa anpassade AI-modeller med Azure Machine Learning
Tillgängligheten av avancerade AI-modeller kan hjälpa organisationer att avsevärt minska den skrämmande mängd resurser som ett datavetenskapsprojekt kan kräva. Nu ska vi se hur organisationer kan hantera maskininlärningsutmaningar och åtgärder med Azure Machine Learning.
Maskininlärningsutmaningar och behov av maskininlärningsåtgärder
Att underhålla AI-lösningar kräver vanligtvis livscykelhantering för maskininlärning för att dokumentera och hantera data, kod, modellmiljöer och själva maskininlärningsmodellerna. Du måste upprätta processer för att utveckla, paketera och distribuera modeller, samt övervaka deras prestanda och ibland träna om dem. Och de flesta organisationer hanterar flera modeller i produktion samtidigt, vilket ökar komplexiteten.
För att effektivt hantera den här komplexiteten krävs vissa metodtips. De fokuserar på samarbete mellan team, automatisera och standardisera processer och se till att modeller enkelt kan granskas, förklaras och återanvändas. För att få detta gjort förlitar sig datavetenskapsteamen på metoden för maskininlärningsåtgärder . Den här metoden är inspirerad av DevOps (utveckling och drift), branschstandarden för att hantera åtgärder för en programutvecklingscykel, eftersom utvecklarnas och dataforskarnas kamp är liknande.
Azure Machine Learning
Dataexperter kan hantera och köra DevOps för maskininlärning från Azure Machine Learning, en plattform från Microsoft för att göra maskininlärningslivscykelhantering och driftsmetoder enklare. Sådana verktyg hjälper team att samarbeta i en delad, granskningsbar och säker miljö där många processer kan optimeras via automatisering.
Livscykelhantering med Machine Learning
Azure Machine Learning stöder livscykelhantering från slutpunkt till slutpunkt för förtränad och anpassad modeller. Den typiska livscykeln innehåller följande steg: förberedelse av data, modellträning, modellpaketering, modellvalidering, modelldistribution, modellövervakning och omträning.
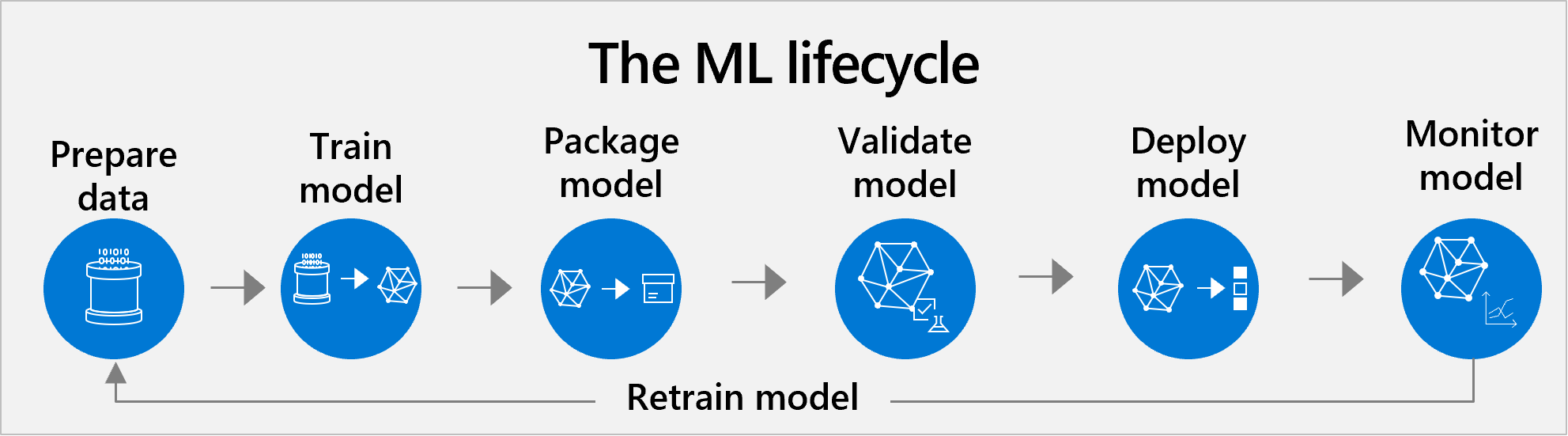
Den klassiska metoden omfattar alla vanliga steg i ett datavetenskapsprojekt.
- Förbereda datauppsättningen. AI börjar med data. För det första måste dataexperter förbereda data för att träna modellen. Dataförberedelse är ofta det största tidsåtagandet i livscykeln. Den här uppgiften omfattar att hitta eller skapa en egen datauppsättning och rensa den så att den enkelt kan läsas av datorer. Du vill se till att data är ett representativt exempel, att dina variabler är relevanta för ditt mål och så vidare.
- Träna och testa. Därefter tillämpar dataforskare algoritmer på data för att träna en maskininlärningsmodell. Sedan testar de den med nya data för att se hur exakta förutsägelserna är.
- Paket. En modell kan inte placeras direkt i en app. Den måste vara containerbaserad, så att den kan köras med alla verktyg och ramverk som den bygger på.
- Verifiera. I det här läget utvärderar teamet hur modellprestandan jämförs med deras affärsmål. Testning kan returnera tillräckligt bra mått, men modellen kanske inte fungerar som förväntat när den används i ett verkligt affärsscenario.
- Upprepa steg 1–4. Det kan ta hundratals träningstimmar att hitta en tillfredsställande modell. Utvecklingsteamet kan träna många versioner av modellen genom att justera träningsdata, justera algoritmens hyperparametrar eller prova olika algoritmer. Helst förbättras modellen med varje justeringsrunda. I slutändan är det utvecklingsteamets roll att avgöra vilken version av modellen som passar bäst för affärsanvändningsfallet.
- Deploy (Distribuera). Slutligen distribuerar de modellen. Alternativen för distribution är: i molnet, på en lokal server och på enheter som kameror, IoT-gatewayer eller maskiner.
- Övervaka och träna om. Även om en modell fungerar bra till en början måste den övervakas kontinuerligt och tränas om för att hålla sig relevant och korrekt.
Kommentar
För att integrera förtränad modeller och anpassa dem till dina affärsbehov krävs ett annat arbetsflöde som integrerar anpassade modeller. Med Azure Machine Learning kan du använda förtränad modeller eller skapa egna modeller. Att välja en metod framför en annan beror på scenariot. Att arbeta med förtränad modeller har fördelen att kräva mindre resurser och leverera resultat snabbare. Fördefinierade modeller tränas dock att lösa ett brett spektrum av användningsfall, så de kan kämpa för att uppfylla mycket specifika behov. I dessa fall kan en fullständig anpassad modell vara en bättre idé. En flexibel blandning av båda metoderna är ofta att föredra och hjälper till att skala. AI-team kan spara resurser med förtränad modeller för de enklaste användningsfallen, samtidigt som de investerar dessa resurser i att skapa anpassade AI-modeller för de svåraste scenarierna. Ytterligare iterationer kan förbättra de fördefinierade modellerna genom att träna om dem.
MLOps (Machine Learning Operations)
Maskininlärningsåtgärder (MLOps) tillämpar metoden för DevOps (utveckling och åtgärder) för att hantera maskininlärningslivscykeln mer effektivt. Det möjliggör ett mer agilt och produktivt samarbete i AI-team bland alla intressenter. Dessa samarbeten omfattar dataforskare, AI-tekniker, apputvecklare och andra IT-team.
MLOps-processer och verktyg hjälper dessa team att samarbeta och ge insyn genom delad, granskningsbar dokumentation. MED MLOps-tekniker kan användarna spara och spåra ändringar i alla resurser, till exempel data, kod, modeller och andra verktyg. Dessa tekniker kan också skapa effektivitet och påskynda livscykeln med automatisering, repeterbara arbetsflöden och återanvändbara tillgångar. Alla dessa metoder gör AI-projekt mer flexibla och effektiva.
Azure Machine Learning stöder följande MLOps-metoder:
Modellåtergivning: innebär att olika teammedlemmar kan köra modeller på samma datauppsättning och få liknande resultat. Reproducerbarhet är avgörande för att göra resultatet av modeller i produktion tillförlitligt. Azure Machine Learning stöder modellåtergivning med centralt hantera tillgångar som miljöer, kod, datauppsättningar, modeller och maskininlärningspipelines.
Modellverifiering: Innan en modell distribueras är det viktigt att verifiera dess prestandamått. Du kan ha flera mått som används för att ange den "bästa" modellen. Det är viktigt att validera prestandamått på sätt som är relevanta för affärsanvändningsfallet. Azure Machine Learning stöder modellverifiering med många verktyg för att utvärdera modellmått, till exempel förlustfunktioner och förvirringsmatriser.
Modelldistribution: När en modell distribueras är det viktigt att dataforskare och AI-tekniker samarbetar för att fastställa det bästa distributionsalternativet. Dessa alternativ omfattar molnenheter, lokala enheter och gränsenheter (kameror, drönare, maskiner).
Modellomträning: Modeller måste övervakas och tränas regelbundet om för att korrigera prestandaproblem och dra nytta av nyare träningsdata. Azure Machine Learning stöder en systematisk och iterativ process för att kontinuerligt förfina och säkerställa modellens noggrannhet.
Dricks

Kundberättelse: En sjukvårdsorganisation använder Azure Machine Learning för att träna anpassade maskininlärningsmodeller som förutsäger sannolikheten för komplikationer under kirurgiska ingrepp. Modellerna tränas på enorma mängder data, inklusive faktorer som ålder, etnicitet, rökningshistoria, kroppsmasseindex och blodplättsantal. Med hjälp av dessa modeller kan medicinsk personal bättre bedöma risker och fastställa alternativ för kirurgi eller livsstilsändringsrekommendationer för enskilda patienter. Den ansvarsfulla AI-instrumentpanelen i Azure Machine Learning hjälper till att förklara prediktiva faktorer och minimera fördomar från demografiska faktorer. I slutändan hjälper den förutsägande modelleringslösningen till att minska risker och osäkerhet och förbättra kirurgiska utfall. Läs hela kundberättelsen här: https://aka.ms/azure-ml-customer-story.
Dricks
Ta en stund att tänka på hur din organisation kan använda datavetenskap och maskininlärningsexpertis för att skapa anpassade modeller.

Nu ska vi avsluta allt med en kunskapskontroll.