One-hot-vektorer
Hittills har vi gått igenom kontinuerlig datakodning (flyttalsnummer), ordningstal för datakodning (vanligtvis heltal) och binär kategorisk datakodning (överlevde/dog, man/kvinna osv.).
Nu ska vi lära oss att koda data och vi ska utforska kategoriska dataresurser som har fler än två klasser. Vi kommer också att utforska de potentiellt skadliga effekterna av våra beslut om modellförbättringar på modellprestanda.
Kategoridata är inte numeriska
Kategoridata fungerar inte med siffror på samma sätt som andra datatyper fungerar med tal. Med ordningstalsdata eller kontinuerliga (numeriska) data innebär högre värden en ökning av mängden. Till exempel är ett Titanic-biljettpris på £ 30 mer pengar än ett biljettpris på £ 12.
Kategoridata har däremot ingen logisk ordning. Vi får problem om vi försöker koda kategoriska funktioner som har fler än två klasser som siffror.
Till exempel har Port of Embarkment tre värden: C (Cherbourg), Q (Queenstown) och S (Southampton). Vi kan inte ersätta dessa symboler med siffror. Om vi gör det skulle det innebära att en av dessa portar är mindre än de andra portarna, medan en annan är större än de andra portarna. Den här ersättningen är meningslös.
Som ett exempel på det här problemet ska vi vara försiktiga med vinden och modellera relationen mellan Port of Embarkment och Ticket Class och behandla Port of Embarkment som ett tal. Först anger vi C < S < Q:
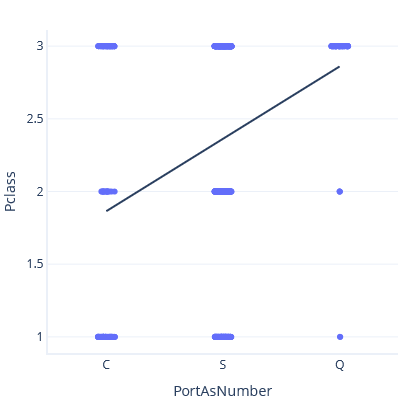
I det här diagrammet förutsäger raden en klass på ~3 för port Q.
Om vi nu anger S < C < Q får vi en annan trendlinje och förutsägelse:
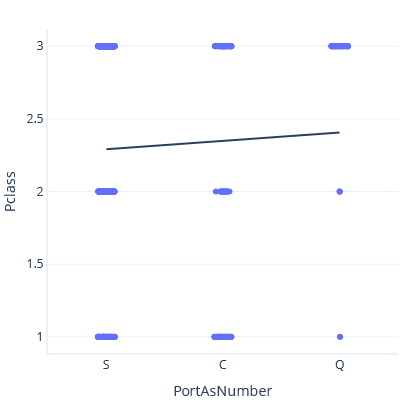
Ingen av dessa trendlinjer är korrekta. Det är ingen mening med att behandla kategorier som kontinuerliga funktioner. Hur arbetar vi då med kategorier?
One-hot-kodning
Kodning med en frekvent kodning kan koda kategoriska data på ett sätt som undviker det här problemet. Varje tillgänglig kategori får en egen enskild kolumn, och en viss rad innehåller bara ett enda värde på 1 i den kategori som den tillhör.
Vi kan till exempel koda portvärdet i tre kolumner: en för Cherbourg, en för Queenstown och en för Southampton (den exakta ordningen här har ingen relevans). Någon som gick ombord på Cherbourg skulle ha en 1 i Port_Cherbourg kolumn, så här:
| Port_Cherbourg | Port_Queenstown | Port_Southampton |
|---|---|---|
| 1 | 0 | 0 |
Någon som gick ombord på Queenstown skulle ha en 1 i den andra kolumnen:
| Port_Cherbourg | Port_Queenstown | Port_Southampton |
|---|---|---|
| 0 | 1 | 0 |
Någon som gick ombord på Southampton skulle ha en 1 i den tredje kolumnen
| Port_Cherbourg | Port_Queenstown | Port_Southampton |
|---|---|---|
| 0 | 0 | 1 |
Kodning med en frekvent kodning, datarensning och statistisk kraft
Innan vi använder en frekvent kodning bör vi förstå att dess användning kan ha positiva eller negativa effekter på en modells verkliga prestanda.
Vad är statistisk makt?
Statistisk effekt syftar på en modells förmåga att på ett tillförlitligt sätt identifiera verkliga relationer mellan funktioner och etiketter. En kraftfull modell kan till exempel rapportera en relation mellan biljettpris och överlevnadsgrad, med hög grad av säkerhet. Däremot kan en modell med låg statistisk makt rapportera en relation med en låg grad av säkerhet, eller kanske inte ens hitta den här relationen alls.
Vi undviker matematiken här, men kom ihåg att de val vi gör kan påverka kraften i våra modeller.
Om du tar bort data minskar den statistiska kraften
Vi nämnde flera gånger att datarensning delvis innebär borttagning av ofullständiga dataexempel. Tyvärr kan datarensning minska den statistiska kraften. Låt oss till exempel låtsas att vi vill förutsäga Titanic-resans överlevnad med hjälp av följande data:
| Biljettpris | Överlevnad |
|---|---|
| £4 | 0 |
| £8 | 0 |
| £10 | 1 |
| £25 | 1 |
Vi kan gissa att någon med en biljett värd £ 15 skulle överleva, eftersom människor med biljetter som kostar minst £ 10 alla överlevde. Men om vi hade mindre data skulle den här gissningen bli svårare:
| Biljettpris | Överlevnad |
|---|---|
| £4 | 0 |
| £8 | 0 |
| £25 | 1 |
Värdelösa kolumner sänker statistisk kraft
Funktioner som har lite värde kan också skada den statistiska kraften, särskilt när antalet funktioner (eller kolumner) börjar närma sig antalet exempel (eller rader).
Anta till exempel att vi vill kunna förutsäga överlevnad med följande data:
| Biljettpris | Överlevnad |
|---|---|
| £4 | 0 |
| £4 | 0 |
| £25 | 1 |
| £25 | 1 |
Vi kan med säkerhet förutsäga att någon med en Cabin A-biljett skulle överleva, eftersom alla med £ 25 biljetter överlevde.
Men nu har vi en annan funktion (cabin):
| Biljettpris | Hytt | Överlevnad |
|---|---|---|
| £4 | A | 0 |
| £4 | A | 0 |
| £25 | F | 1 |
| £25 | F | 1 |
Stugan ger inte användbar information, eftersom den helt enkelt motsvarar biljettpriset. Det är oklart om någon med en stuga för 25 pund en biljett skulle överleva. Förgås de, som andra från stuga A, eller överlever de som de med £ 25 biljetter?
Kodning med en frekvent kodning kan minska den statistiska kraften
Kodning med en frekvent kodning minskar den statistiska kraften mer än kontinuerliga eller ordningsmässiga data, eftersom det kräver flera kolumner, en för varje möjligt kategoriskt värde. Om vi till exempel kodar instansporten med en frekvent kod lägger vi till tre modellindata (C, S och Q).
En kategorisk variabel blir användbar om antalet kategorier är betydligt mindre än antalet exempel (datamängdsrader). En kategorisk variabel blir också användbar om den innehåller information som inte redan är tillgänglig för modellen via andra indata.
Vi såg till exempel att sannolikheten för överlevnad skilde sig åt för personer som gav sig ut i olika hamnar. Denna variation återspeglar förmodligen det faktum att de flesta människor i Queenstown-hamnen hade tredje klassbiljetter. Därför minskar inmatningen förmodligen statistiska kraften i viss utsträckning, utan att lägga till relevant information i vår modell.
Cabin har däremot sannolikt ett starkt inflytande på överlevnaden. Detta beror på att fartygets nedre stugor skulle ha fyllts med vatten innan stugorna närmare fartygets övre däck fyllda med vatten. Som sagt, Titanic-datamängden innehåller 147 olika stugor. Detta minskar den statistiska kraften i vår modell om vi inkluderar dem. Vi kan behöva experimentera med att inkludera eller exkludering av kabindata i vår modell för att se om kabindata kan hjälpa oss.
I nästa övning bygger vi äntligen vår modell som förutsäger Titanic-resans överlevnad, och vi kommer att öva på en het kodning när vi gör det.