Definiera övervakad utbildning
Processen för att träna en modell kan antingen övervakas eller vara oövervakad. Vårt mål är att kontrastera dessa metoder och sedan ta en djupare inblick i inlärningsprocessen med fokus på övervakat lärande. Det är värt att komma ihåg under hela den här diskussionen att den enda skillnaden mellan övervakad och oövervakad inlärning är hur målfunktionen fungerar.
Vad är oövervakad inlärning?
I oövervakad inlärning tränar vi en modell för att lösa ett problem utan att vi vet rätt svar. I själva verket används oövervakad inlärning vanligtvis för problem där det inte finns ett korrekt svar, utan i stället bättre och sämre lösningar.
Anta att vi vill att vår maskininlärningsmodell ska rita realistiska bilder av lavinräddningshundar. Det finns ingen "korrekt" ritning att rita. Så länge bilden ser ut ungefär som en hund är vi nöjda. Men om den producerade bilden är av en katt är det en sämre lösning.
Kom ihåg att träning kräver flera komponenter:
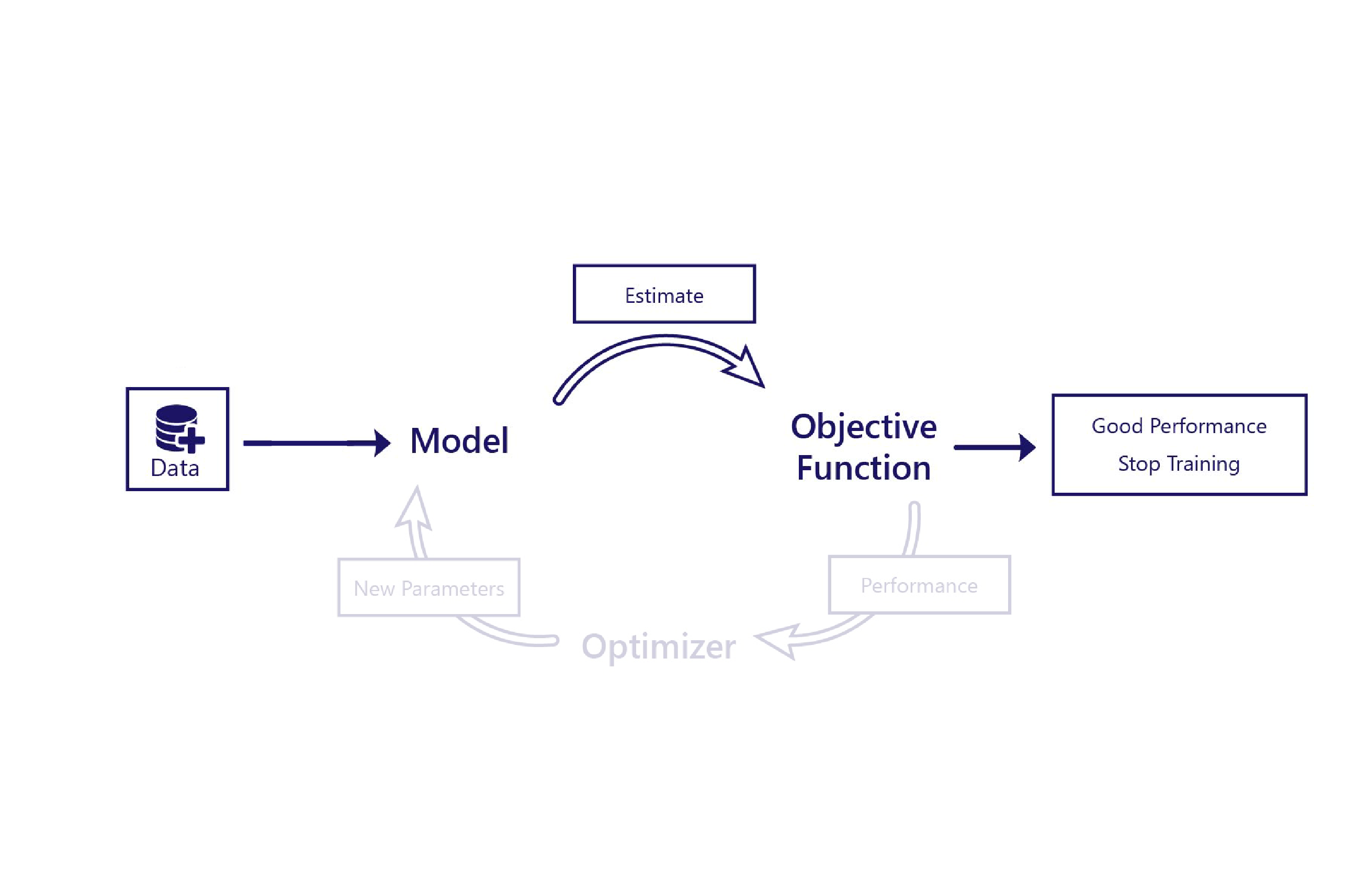
I oövervakad inlärning gör målfunktionen sin bedömning enbart på modellens uppskattning. Det innebär att målfunktionen ofta måste vara relativt sofistikerad. Till exempel kan målfunktionen behöva innehålla en "hunddetektor" för att bedöma om bilder som modellen ritar ser realistiska ut. De enda data som vi behöver för oövervakad inlärning handlar om funktioner som vi tillhandahåller till modellen.
Vad är övervakad inlärning?
Tänk på övervakad inlärning som utbildning efter exempel. I övervakad inlärning utvärderar vi modellens prestanda genom att jämföra dess uppskattningar med rätt svar. Även om vi kan ha enkla objektiva funktioner behöver vi båda:
- Funktioner som tillhandahålls som indata till modellen
- Etiketter, som är rätt svar som vi vill att modellen ska kunna producera
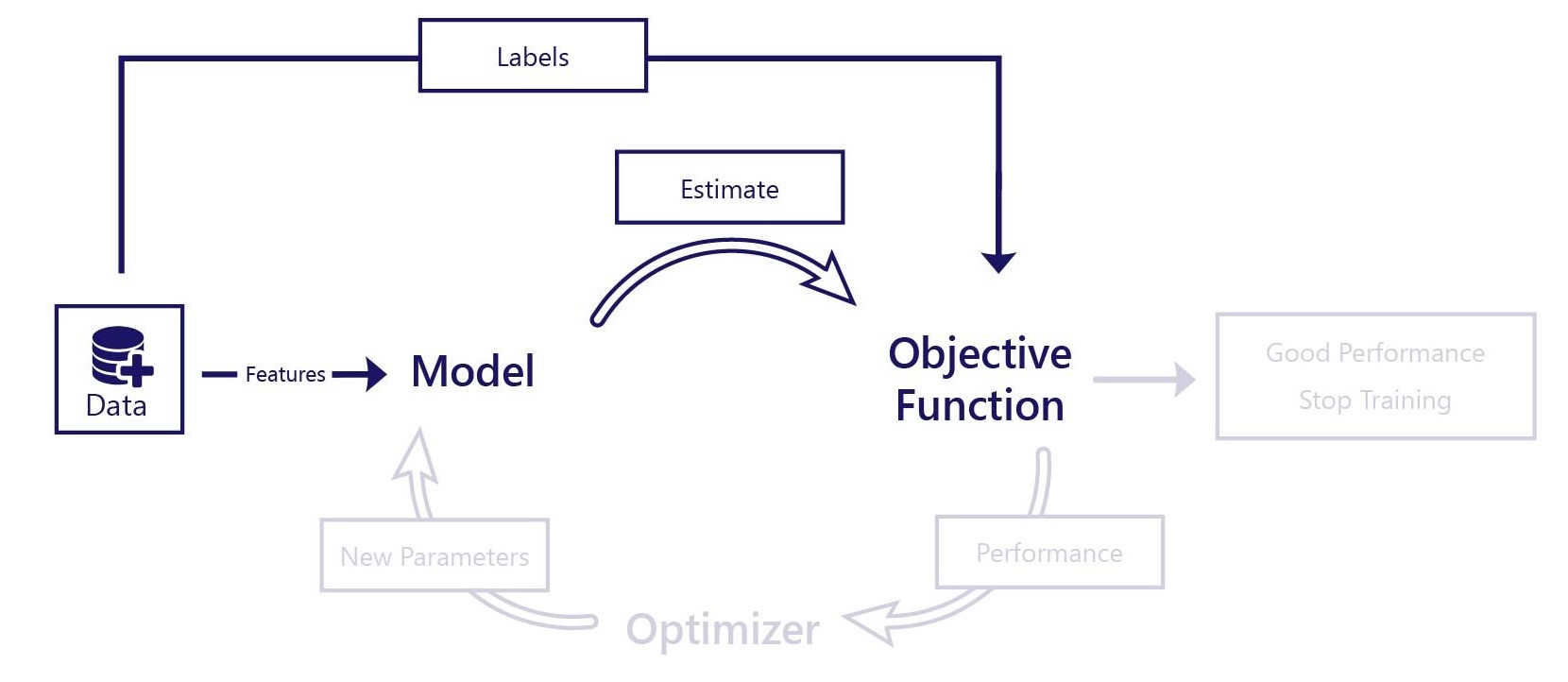
Tänk till exempel på vår önskan att förutsäga vilken temperatur som kommer att vara den 31 januari ett visst år. För den här förutsägelsen behöver vi data med två komponenter:
- Funktion: Datum
- Etikett: Daglig temperatur (till exempel från historiska poster)
I scenariot anger vi datumfunktionen till modellen. Modellen förutsäger temperaturen och vi jämför det här resultatet med datauppsättningens "korrekta" temperatur. Målfunktionen kan sedan beräkna hur väl modellen fungerade och vi kan göra justeringar i modellen.
Etiketter är bara till för inlärning
Det är viktigt att komma ihåg att oavsett hur modeller tränas bearbetar de bara funktioner. Under övervakad inlärning är målfunktionen den enda komponenten som förlitar sig på åtkomst till etiketter. Efter träningen behöver vi inte etiketter för att använda vår modell.