Azure Batch
HPC (High Performance Computing) är praxis att använda betydande databehandlingskraft som ger höga prestanda jämfört med vad du kan få när du använder din bärbara dator och/eller arbetsstation. Det löser stora problem som måste köras på flera kärnor samtidigt.
Det görs genom att dela upp ett problem i mindre beräkningsenheter och distribuera enheterna till ett distribuerat system. Den kommunicerar kontinuerligt mellan dem för att nå den slutliga lösningen mycket snabbare än att köra samma beräkning på färre kärnor.
Det finns flera alternativ för HPC- och batchbearbetning i Azure. Om du pratar med en Azure-expert rekommenderar de att du fokuserar på tre alternativ: Azure Batch, Azure CycleCloud och Microsoft HPC Pack. Följande enheter i den här modulen fokuserar på varje alternativ. Det är viktigt att observera att dessa val inte utesluter varandra. De bygger på varandra och kan ses som olika verktyg i en verktygslåda.
Här lär du dig mer om högpresterande databehandling i allmänhet och lär dig mer om Azure HPC.
Vad är HPC i Azure?
Det finns många olika branscher som kräver kraftfulla databehandlingsresurser för specialiserade uppgifter. Till exempel:
- Inom genetiska vetenskaper, gensekvensering.
- Inom olje- och gasprospektering, reservoarsimuleringar.
- Inom finans, marknadsmodellering.
- Inom teknik, fysisk systemmodellering.
- I meteorologin, vädermodellering.
Dessa uppgifter kräver processorer som kan utföra instruktioner snabbt. HPC-program i Azure kan skalas till tusentals beräkningskärnor, utöka lokal stor beräkning eller köras som en 100% molnbaserad lösning. Den här HPC-lösningen, inklusive huvudnoden, beräkningsnoderna och lagringsnoderna, körs i Azure utan någon maskinvaruinfrastruktur att underhålla. Den här lösningen bygger på Azure-hanterade tjänster: Skalningsuppsättningar för virtuella maskiner, virtuella nätverk och lagringskonton.
De här tjänsterna körs i en miljö med hög tillgänglighet, som har korrigerats och stöds, så att du kan fokusera på din lösning i stället för den miljö som de körs i. Ett Azure HPC-system har också fördelen att du dynamiskt kan lägga till resurser när de behövs och ta bort dem när efterfrågan minskar.
Vad är parallell databehandling i distribuerade system?
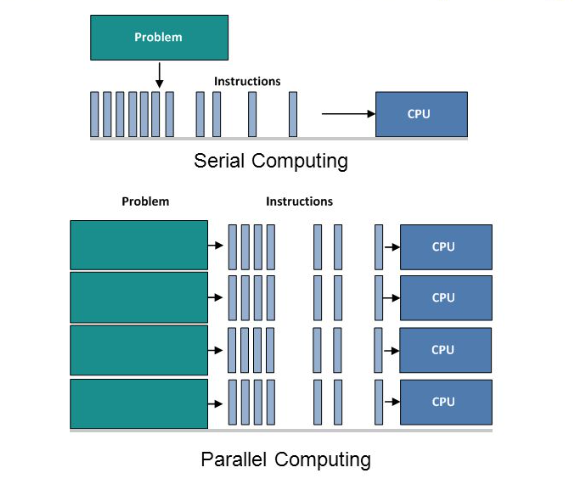
Parallell databehandling är samtidig användning av flera beräkningsresurser för att lösa ett beräkningsproblem:
- Ett problem är indelat i diskreta delar som kan lösas samtidigt.
- Varje del är ytterligare uppdelad i en serie instruktioner.
- Instruktioner från varje del körs samtidigt på olika processorer.
- En övergripande kontroll-/samordningsmekanism används.
Olika faser av parallellitet
Det finns olika sätt att klassificera parallella datorer och Flynns taxonomi är ett av de vanligaste sätten att göra det på. Den särskiljer datorarkitekturer med flera processorer beroende på hur de kan klassificeras längs de två oberoende dimensionerna i Instruktionsström och Dataström. Var och en av dessa dimensioner kan bara ha ett av två möjliga tillstånd: enskild eller flera.
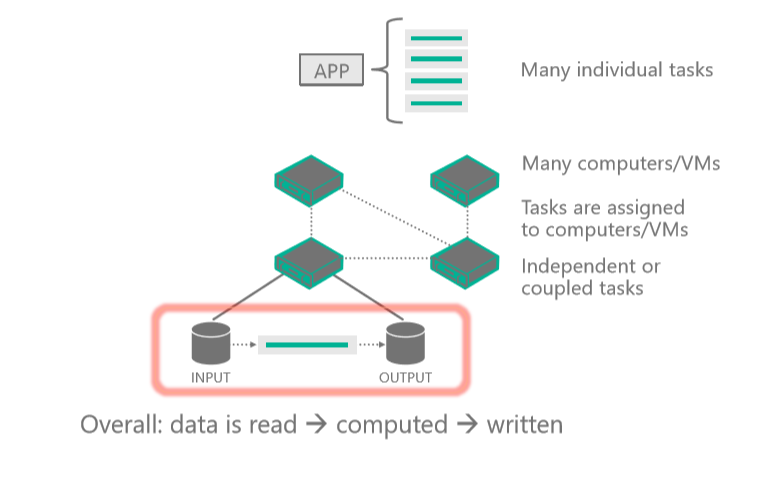
Det här diagrammet visar ett klientprogram eller en värdbaserad tjänst som interagerar med Batch för att ladda upp indata, skapa jobb, övervaka uppgifter och ladda ned utdata.
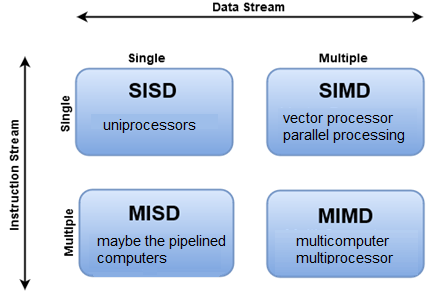
Vi kan ta en närmare titt på de fyra olika klassificeringarna.
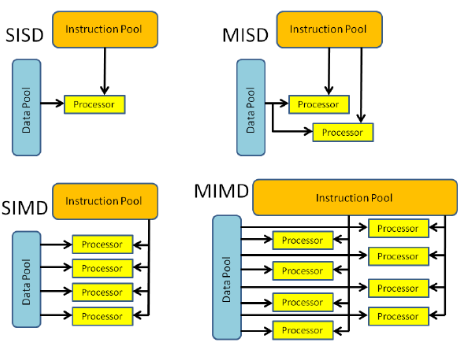
| SISD | SIMD | FEL | MIMD |
|---|---|---|---|
| - Seriell dator – Enskild instruktion: Endast en instruktionsström hanteras av processorn under en klockcykel – Enskilda data: Endast en dataström används som indata under en klockcykel. - Äldsta typen av dator. exempel: 1. Stordatorer i tidig generation 2. Minidatorer, arbetsstationer 3. Datorer med en processorkärna |
– Parallell dator - Enskild instruktion: Alla bearbetningsenheter kör samma instruktion vid en viss klockcykel. – Flera data: Varje bearbetningsenhet kan köras på ett annat dataelement. - Passar bäst för specialiserade problem som kännetecknas av en hög grad av regelbundenhet, till exempel grafik/bildbearbetning. - De flesta moderna datorer använder grafikprocessorer och har SIMD-instruktioner och exekveringsenheter. exempel: 1. Processormatriser: Thinking Machines CM-2, MasPar MP-1 & MP-2, ILLIAC IV 2. Vektorpipelines: IBM 9000, Cray X-MP, Y-MP & C90, Fujitsu VP, NEC SX-2, Hitachi S820, ETA10 |
– Parallell dator – Flera instruktioner: Varje bearbetningsenhet arbetar på data separat via separata instruktionsströmmar. – Enkla data: En enda dataström matas in i flera bearbetningsenheter. - Få (om några) faktiska exempel på den här klassen av parallell dator har någonsin funnits. exempel: 1. Flera frekvensfilter som körs på en enda signalström 2. Flera kryptografialgoritmer försöker knäcka ett enda kodat meddelande |
– Parallell dator – Flera instruktioner: Varje processor kan köra en annan instruktionsström. – Flera data: Varje processor kanske arbetar med en annan dataström. - För närvarande är den vanligaste typen av parallell dator - de flesta moderna superdatorer i den här kategorin. exempel: 1. De flesta aktuella superdatorer 2. Nätverkella datorkluster och "rutnät" 3. SMP-datorer med flera processorer 4. Datorer med flera kärnor |
Olika typer av HPC-jobb: Massivt parallella kontra tätt kopplade
Parallella jobb har beräkningsproblem indelade i små, enkla och oberoende uppgifter som kan köras samtidigt, ofta med lite eller ingen kommunikation mellan dem.
Vanliga användningsfall för parallella jobb är risksimuleringar, molekylär modellering, kontextbaserad sökning och logistiksimuleringar.
Nära kopplade jobb har en stor delad arbetsbelastning som är uppdelad i mindre uppgifter som kommunicerar kontinuerligt. De olika noderna i klustret kommunicerar med varandra när de utför sin bearbetning.
Vanliga användningsfall för nära kopplade jobb är:
- beräkningsvätskedynamik
- modellering av väderprognoser
- materialsimuleringar
- emulering av bilkollisioner
- geospatiala simuleringar
- trafikhantering
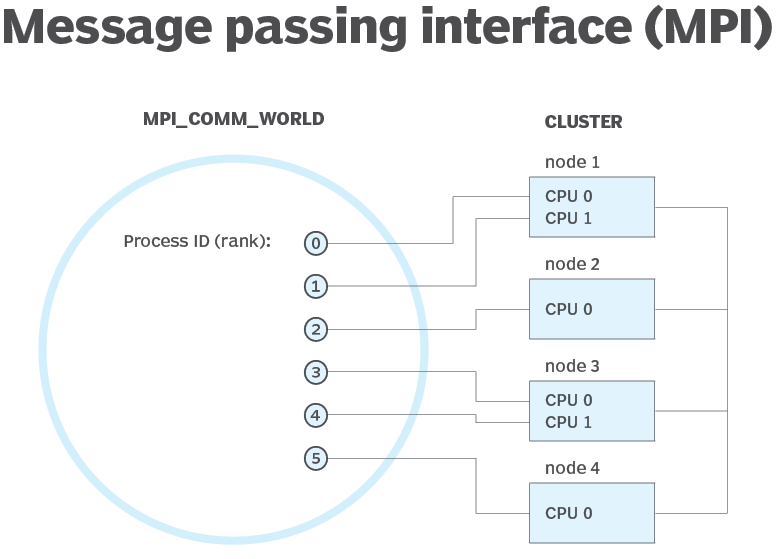
Vad är MPI (Message Passing Interface)
MPI är ett system som syftar till att tillhandahålla en portabel och effektiv standard för meddelandeöverföring. Den är högpresterande, bärbar och skalbar och har utvecklats för att fungera i nätverk med olika parallella datorer.
MPI har bidragit till nätverk och parallell databehandling i industriell och global skala och bidragit till att förbättra arbetet med storskaliga parallella datorprogram.
Microsoft MPI-fördelar:
- Enkelt att portera befintlig kod som använder MPICH.
- Säkerhet baserat på Active Directory Domain Services.
- Höga prestanda i Windows-operativsystemet.
- Binär kompatibilitet mellan olika typer av anslutningsalternativ.